







在eclipse中使用hadoop插件编程,在网上找了不少帖子,最终该贴解决了在eclipse中直接run on hadoop,而不用打jar,上传到hadoop主机,然后在hadoop jar xxx.jar。
在帖子中间补充了两点:
1.如果hadoop是搭建在虚拟机中,如何连接并运行程序
2.增加了log4j.properties配置
注:使用eclipse开发时,将workspace的默认字符集设置为utf-8
在前人的基础上,进行总结学习,发现bug,修改bug。
系统平台:Ubuntu14.04TLS(64位)
Hadoop环境:Hadoop2.7.1
Eclipse:Neon.2 Release(4.6.2)
Eclipse插件:hadoop-eclipse-plugin-2.7.1.jar
一.编译环境搭建
1.在eclipse上安装Hadoop插件
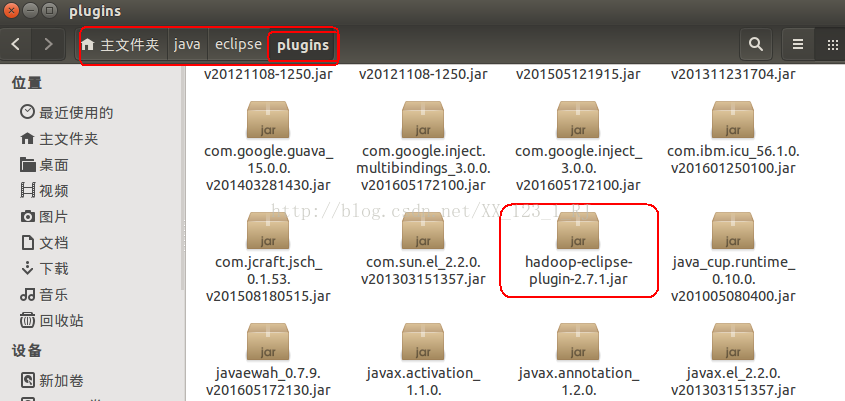
把下载好的hadoop-eclipse-plugin-2.7.1.jar文件拷贝到eclipse安装目录中的plugins文件夹内。如下图:
2.继续配置hadoop编译环境(方便配置,确保已经开启了 Hadoop)
启动 Eclipse 后就可以在左侧的Project Explorer中看到DFS Locations。
3.插件的配置
第一步:选择 Window 菜单下的 Preference。
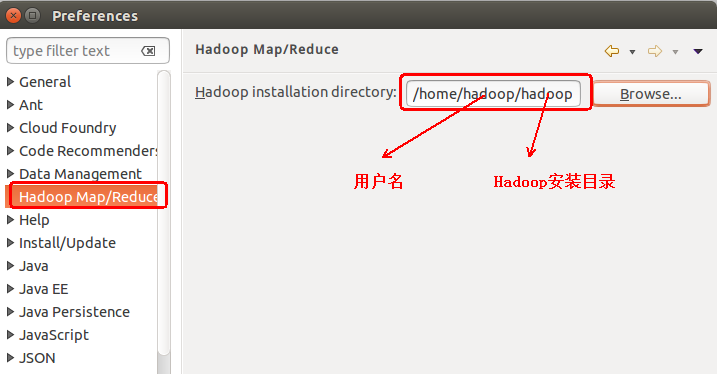
此时会弹出一个窗体,点击选择 Hadoop Map/Reduce 选项,选择 Hadoop 的安装目录(例如:/home/hadoop/hadoop)。
第二步:切换 Map/Reduce 开发视图
选择Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择Map/Reduce 选项即可进行切换。
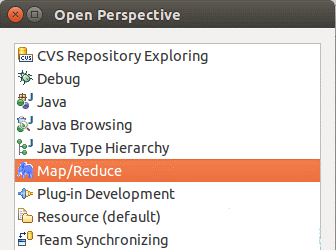
第三步:建立与 Hadoop 集群的连接
点击Eclipse软件右下角的Map/Reduce Locations 面板,在面板中单击右键,选择New Hadoop Location。
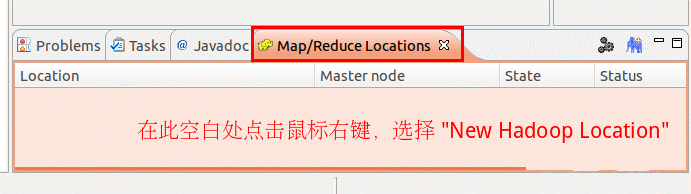
在弹出来的General选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host值是一样的。
如果是在本机搭建hadoop伪分布式,填写 localhost 即可,这里使用的是Hadoop伪分布,设置fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
如果你是在虚拟机中搭建的hadoop伪分布模式,那么图中的Host应该填ip地址或者hostname,建议在这里填写hostname,然后去windows的hosts文件中添加一行
192.168.245.141 hadoop01(hostname可以自定义)
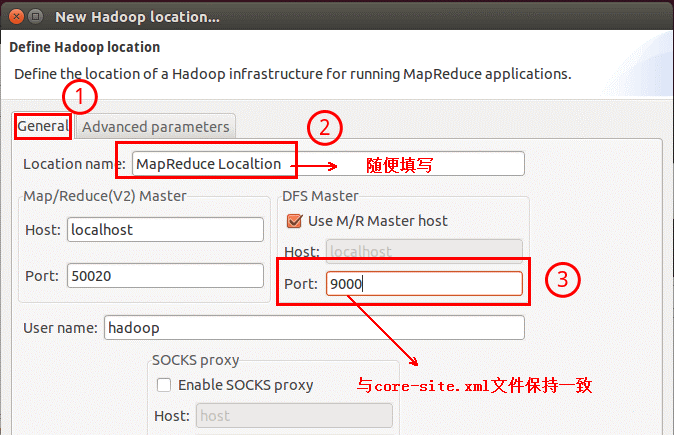
Advanced parameters 选项面板是对 Hadoop 参数进行配置,就是填写 Hadoop 的配置项(/home/hadoop/hadoop/etc/hadoop中的配置文件),如果配置了 hadoop.tmp.dir,就要进行相应的修改。但修改起来会比较繁琐,可以通过复制配置文件的方式解决。只要配置General 就行了,点击 finish,Map/Reduce Location 就创建完成。
二.在 Eclipse 中操作 HDFS 中的文件
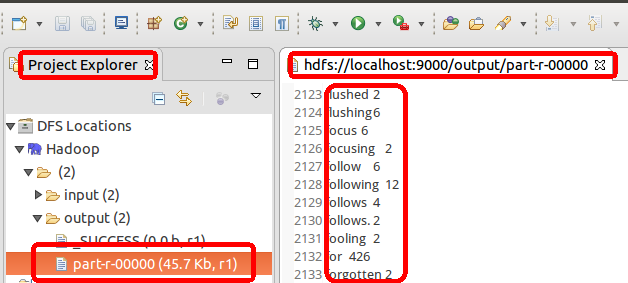
配置好后,点击左侧Project Explorer 中的 MapReduce Location 就能直接查看 HDFS 中的文件列表了(HDFS 中要有文件,如下图是 WordCount的输出结果),双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件。
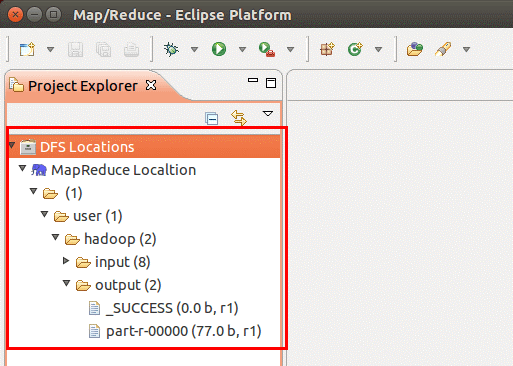
如果无法查看,可右键点击Location 尝试 Reconnect 或重启 Eclipse。HDFS 中的内容更新后Eclipse 不会同步刷新,需要右键点击 Project Explorer中的MapReduce Location,选择Refresh,(文件比较大的情况下eclipse可能死掉,重启eclipse就行)才能看到更新后的文件。
三.在 Eclipse 中创建 MapReduce 项目
点击 File 菜单,选择 New -> Project...:
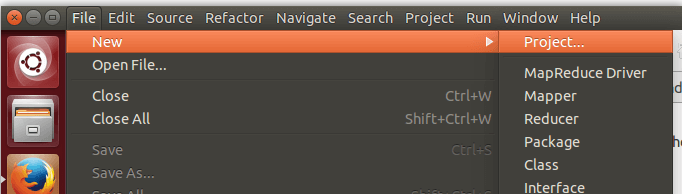
选择Map/Reduce Project,点击Next。
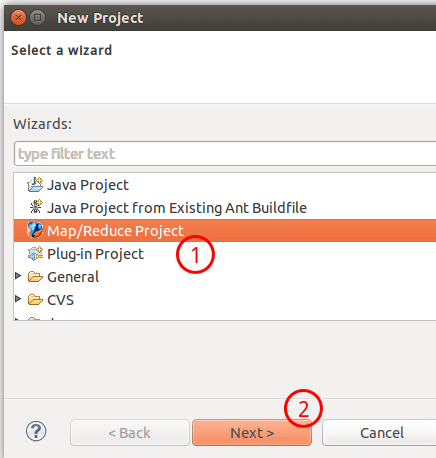
填写 Projectname 为 WordCount 即可,点击Finish就创建好了项目。
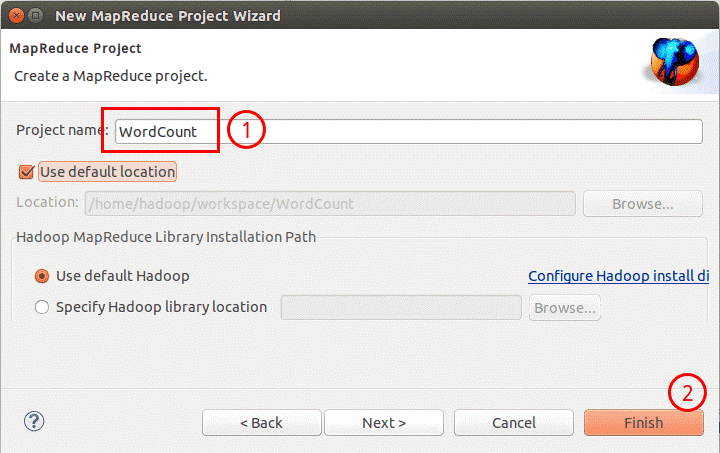
然后在左侧的Project Explorer 可以看到刚才建立的项目。
接着右键点击刚创建的WordCount 项目,选择 New -> Class
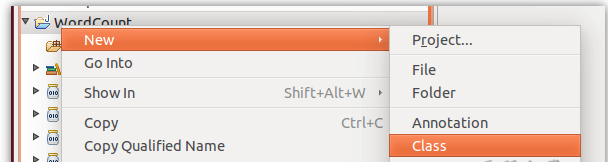
需要填写两个地方:在Package 处填写 org.apache.hadoop.examples;在Name 处填写WordCount。(包名、类名可以随意起)
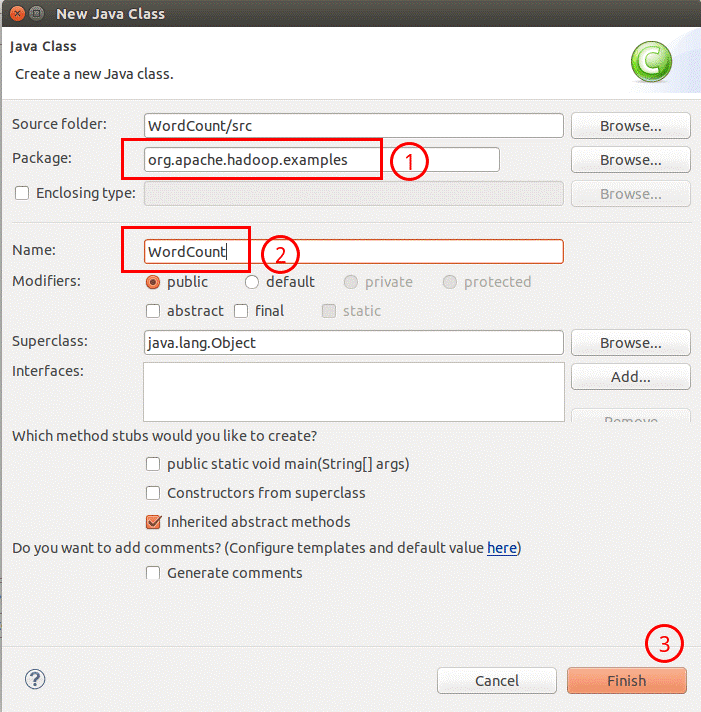
创建 Class 完成后,在 Project 的src中可以看到 WordCount.java 这个文件。将如下 WordCount的代码拷贝到该文件中。
package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Logger logger = Logger.getLogger(WordCountMapper.class);
Text k = new Text();
IntWritable v = new IntWritable(1);
/*
* 知识点
* 1.map方法的key是输入key,是每行的行首偏移量
* 2.map方法的value是输入value,是每行内容
* 3.Writable机制是Hadoop自身的序列化机制,
* 比如:LongWritable IntWritable NullWritable Text(String)等
* 4.context是MR的上下文件对象,此对象的作用:①可以输出结果 ②获取其他环境对象,比如文件的切片信息等
* 5.继承Mapper时,需要制定4个泛型类型
* ①泛型类型对应的是:Mapper输入key的类型
* ②泛型类型对应的是:Mapper输入value的类型
* 初学时,记住:① ②的类型是固定的
* ③泛型类型对应的是:Mapper的输出key类型
* ④泛型类型对应的是:Mapper的输出value类型
* 注:输出key和输出value是程序员自己决定.所以③ ④类型不固定,取决业务
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
logger.info("-----------" + key.get());
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
/*
* 知识点
* 1.reducer组件会接受Mapper组件的输出结果,所以reducer组件不能单独存在,但是Mapper组件可以
* 2.reducer会把Mapper的输出key,按相同的key做聚合(合并)
* 3.合并的形式:key it(迭代器) 通过reduce方法传给开发者.
* 其中 迭代器存储的是 key对应的value的集合
* 4.继承Reducer组件时的四个泛型
* ①泛型对应的Mapper输出key
* ②泛型对应的Mapper输出value
* ③泛型对应的Reducer的输出key
* ④泛型对应的Reducer的输出value
* 5.如果引入reducer组件后,最后的输出结果文件的结果是Reducer的输出key 和输出value
* 6.reduce方法会被调用多次,取决于有多少个不同的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : value) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key, v);
}
}package com.jv.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置 jar 加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置 map 和 reduce 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.245.141:9000/park03"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.245.141:9000/park03/result"));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
四.通过eclipse运行mapreduce
运行 MapReduce 程序前,务必将 /home/hadoop/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要core-site.xml 和 hdfs-site.xml),以及log4j.properties复制到WordCount 项目下的 src文件夹(~/workspace/WordCount/src)中。
原因:
在使用 Eclipse 运行 MapReduce 程序时,会读取 Hadoop-Eclipse-Plugin 的Advanced parameters作为 Hadoop 运行参数,如果未进行修改,则默认的参数其实就是单机(非分布式)参数,因此程序运行时是读取本地目录而不是HDFS 目录,就会提示Input 路径不存在。
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/home/hadoop/workspace/WordCountProject/input所以需要将配置文件拷贝到项目中的 src 目录,来覆盖这些参数。让程序能够正确运行。log4j用于记录程序的输出日记,需要log4j.properties 这个配置文件,如果没有拷贝该文件到项目中,运行程序后在Console 面板中会出现警告提示:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
这种情况不影响程序的正确运行的,但程序运行时无法看到任何提示消息,只能看到出错信息。
或者将如下内容复制到log4j.properties中
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n拷贝完成后,右键点击 WordCount 选择 refresh 进行刷新(不会自动刷新,需要手动刷新),可以看到文件结构如下所示:
将Hadoop安装目录\bin\hadoop.dll复制到c:\windows\system32目录下
在windows环境变量中增加HADOOP_HOME=d:\hadoop-2.7.1
点击工具栏中的 Run 图标,或者右键点击 Project Explorer 中的 WordCount.java,选择 Run As -> Run on Hadoop,就可以运行 MapReduce 程序了。不过由于没有指定参数,运行时会提示 "Usage: wordcount ",需要通过Eclipse设定一下运行参数。
右键点击刚创建的 WordCount.java,选择 Run As -> Run Configurations,在此处可以设置运行时的相关参数(如果 Java Application 下面没有 WordCount,那么需要先双击 Java Application)。切换到 "Arguments"栏,在Program arguments 处填写参数 "/input /output"。
注意:在环境下测试,如果没有"/",会提示如下错误信息:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://localhost:9000/user/hadoop/input
也可以直接在代码中设置好输入参数。可将代码 main() 函数的 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 改为(没有测试):
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"}; /* 直接设置输入参数 */
设定参数后,运行程序,可以看到运行成功的提示,刷新DFS Location后也能看到输出的 output 文件夹。
五.在eclipse中导出可运行的jar包
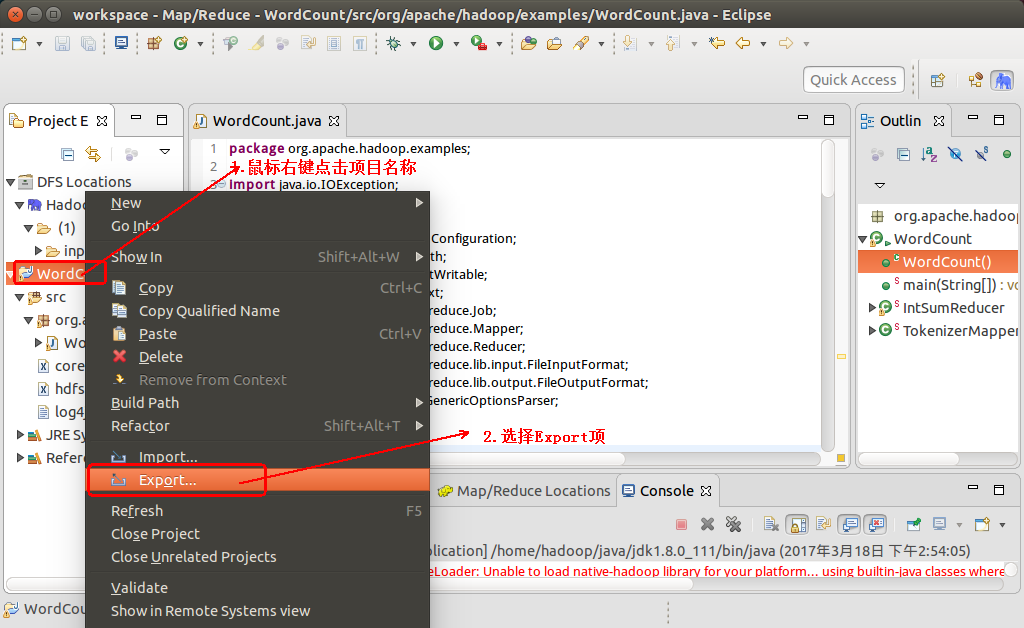
1. 鼠标右键点击项目名称,并选择Export项
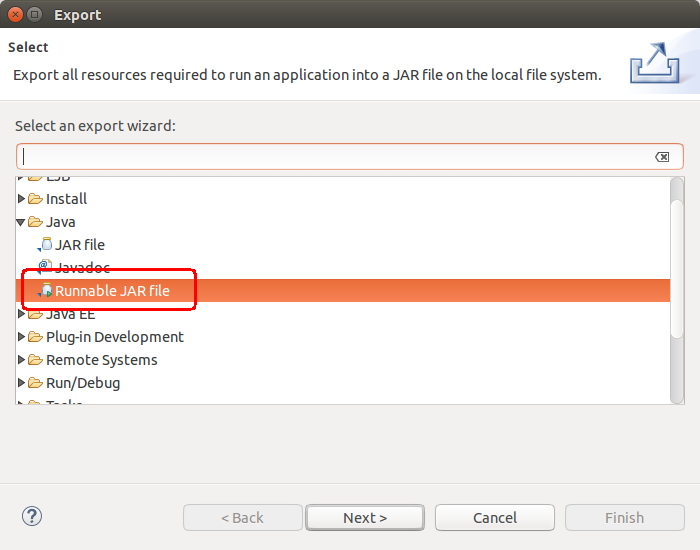
2. 选择Java--> Runnable JAR file
3. 选择正确的项目配置信息,和输出路径以及重命名jar包
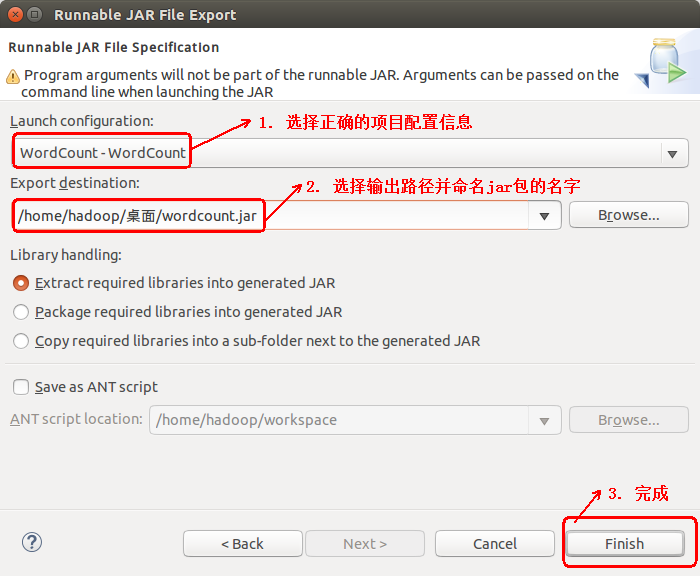
4. 点击OK完成导出可运行jar(测试方法与运行Hadoop自带的Wordcount方法一样,不在赘述)
六、在hadoop的浏览器控制台查看日志
有很多朋友喜欢用System.out.println输出日志,那么可以使用浏览器控制台查看日志
前提:如果按照上面的步骤配置了log4j.properties,那这一节就忽略掉,因为日志不会输出到hadoop主机所在的日志文件中了。如果没有配置log4j.properties,则可以使用控制台查看日志输出
进入自己网址:http://192.168.245.141:50070/logs/userlogs/
下面列出的最后一条就是你最新运行mr程序的日志
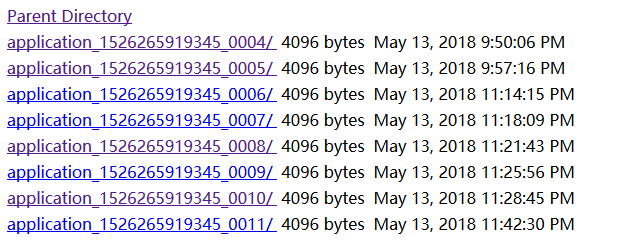
点开最后一条

三个目录应该分别是mapper、reduce、driver的日志输出















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









