







今天,我们介绍的机器学习算法叫逻辑回归。它英语名称是Logistic Regression,简称LR.
跟之前一样,介绍这个算法之前先举一个案例。然后,看一下,如何算法去解决案例中的问题。
这里,我们就直接使用“K临近算法”那一节课用到的案例。我再把案例简述一下:某公司开发了一款游戏,并且得到一些用户的数据。如下所示:
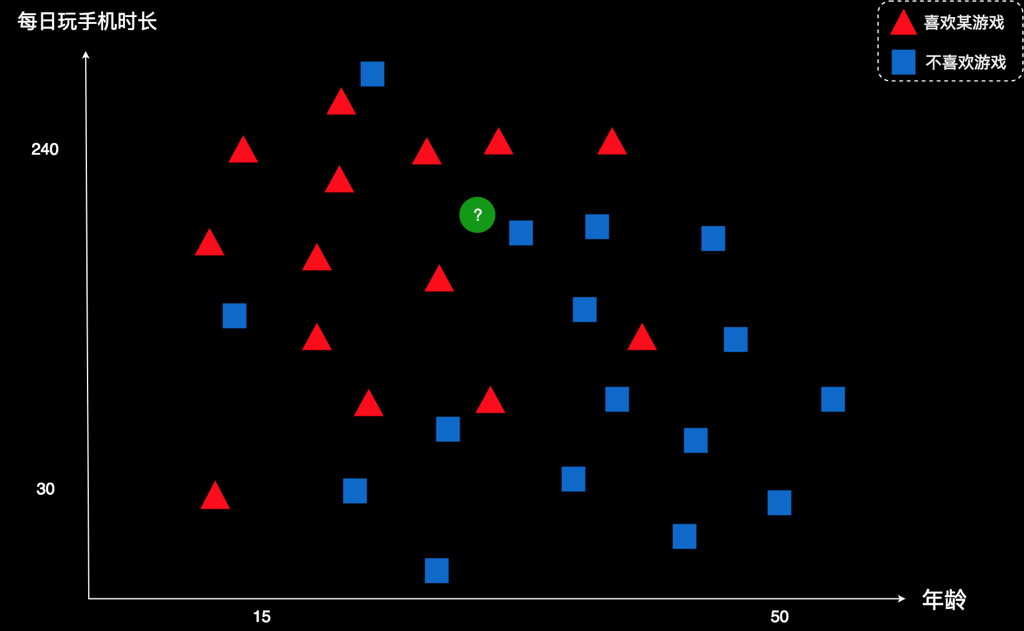
图中每一个图形表示一个用户。横坐标是用户年龄,纵坐标是用户每天使用手机的时长。红色表示该用户喜欢这款游戏,蓝色表示该用户不喜欢这款游戏。现在有个新用户,用绿色所示。这家公司想知道:这个新用户是否喜欢这款游戏?
在K临近法里,我们是找到新用户的几个邻居,然后比较邻居中哪种颜色的人多。根据物以类聚的原则,这个新用户跟大多数邻居的偏好应该是一致的,从而判断他是否喜欢这款游戏。
但是,K临近存在一个问题是,就是计算量特别大。对于每一个新用户,我们都需要计算他自己到所有人的距离,然后把距离从小到大进行排序,最后的到它的K个邻居。
假如有10000个老用户,然后用k临近法预测10000个新用户的类型。那总共需要计算10000 x 10000 = 100000000次,计算量大,消耗资源多。
而今天我们介绍的逻辑回归算法,则换了一种思路。它先从老用户中找到某种规律,然后直接利用这个规律判断新用户是那种类型的。
接下来,我们来看一下逻辑回归是怎么做。
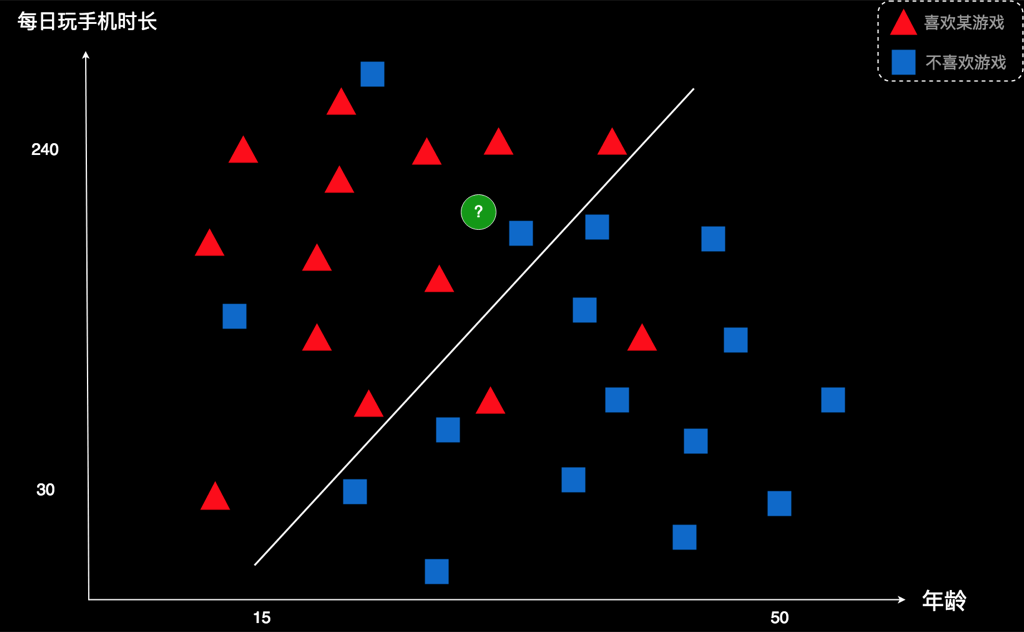
对于这个案例,我们先画一条线把已有的用户分到两边。
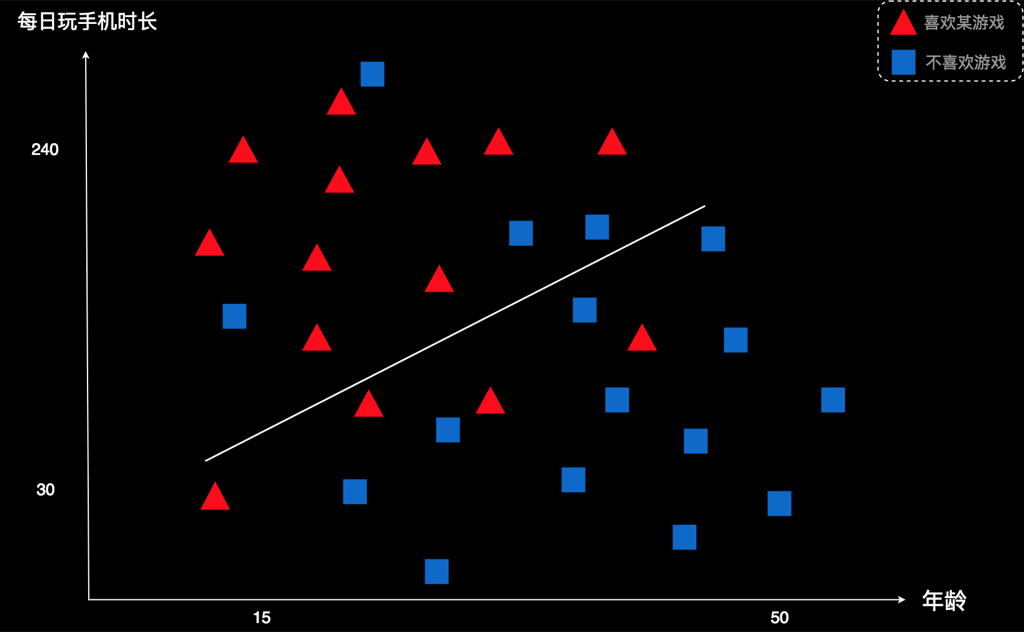
这条线是随便画的。但我们发现,线上方的图形大部分是红色的,线下面的图形大部分是蓝色的。于是,我们就会得出一个初步的规律:“线上方的用户大都倾向于喜欢这款游戏,线下方的用户大都倾向于不喜欢这款游戏”。如果新用户在线的上方,我们就可以判断他很可能也喜欢这款游戏,也就是应该为红色。如果新用户在线的下方,他很可能不喜欢这款游戏,就应该是蓝色。
但是,我怎么知道这条线是不是一条好的划分呢?这里有一种判定标准,叫错误率。所谓错误率,就是一条线把多少用户划到了错误的一边。错误率是一个比率,我们的案例中,因为总人数是固定的,为了方便,我们就直接用错误人数代替错误率。
就拿这条线来说。它认为上方是红色用户,下面是蓝色用户。但是,它上方有4个蓝色是被错误划分的,而下面四个红色也是被错误划分的。 因此它划错的人数是4+4=8个。
我们把这条线稍微调整一下,看看能不能做到更好一点。现在我把线往逆时针方向转动了一点。 这时,他的下方还是4个红色被错误划分,但是上方只有三个蓝色被错误划分。最终错误数变成了7个,比刚才的错误数8要好一点,说明进步了。也就是,这条线比上一条线更合理。
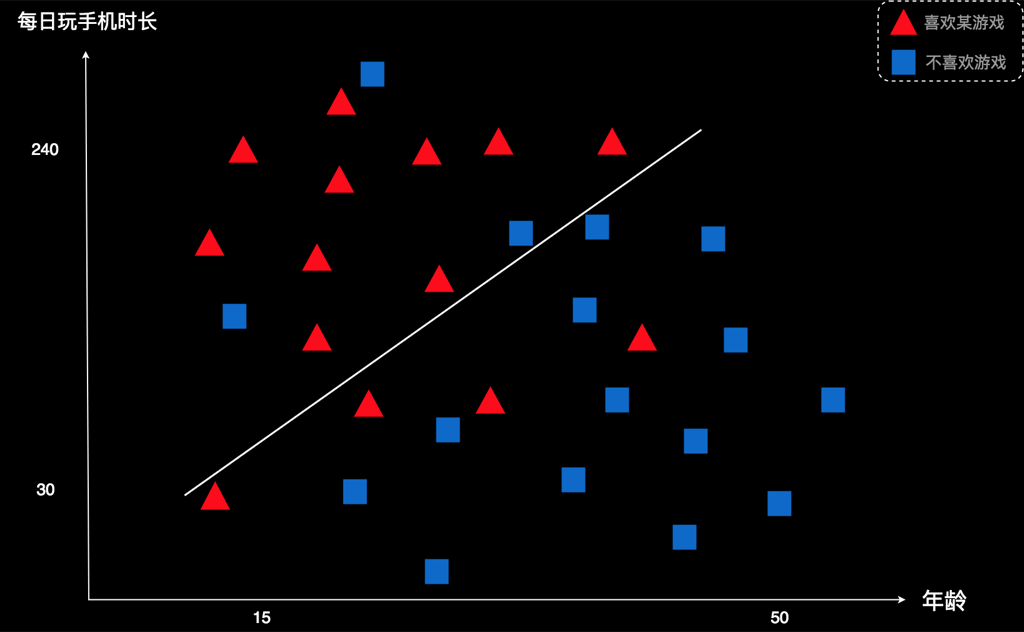
然后,我们可以再微调一次,再计算错误率。再微调,再计算。这样不断进行下去。微调的过程中,如果哪一次的错误率变高了,我们就放弃那次结果。如果错误率降低了,我们就记下来。一直到错误率降到最低为止。我们就找到了一条最优的划分线。
假如图中这个是最优的线,它的左上侧有三个蓝色被划错;右下侧有2个红色被划错。合计5个。
我们就拿这条线作为标准,去预测新用户。 如下图:
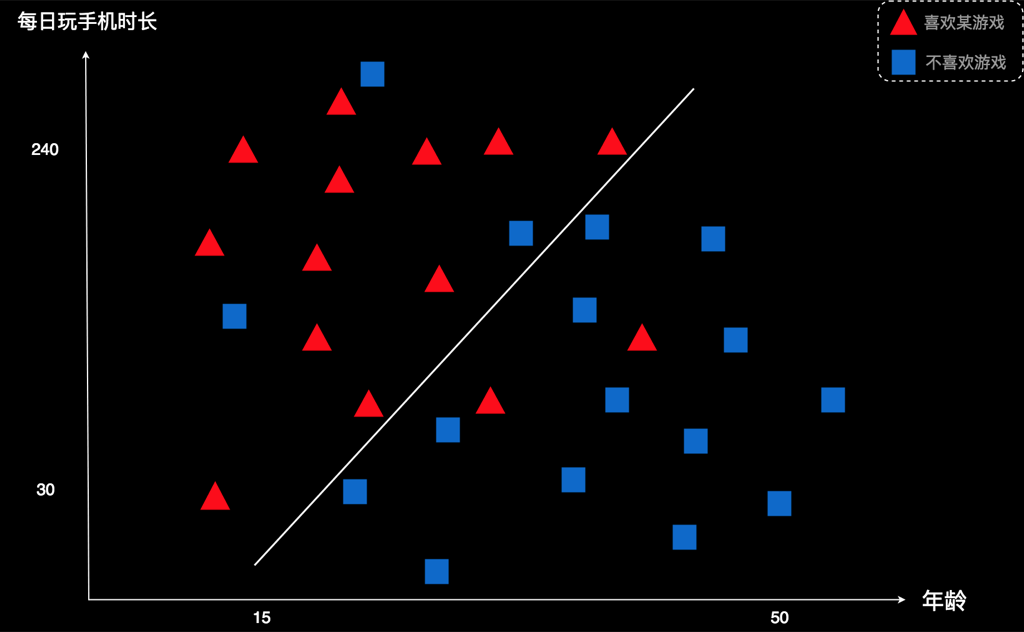
本案例里,我们发现,绿色的新用户在线的左上侧,于是我们判断,这个用户应该是红色。也就是说,他可能喜欢这款游戏,这家公司应该向他推广这款游戏。
在逻辑回归算法里,微调和计算错误率都是自动进行的。而且,微调的方向也不是随机的,它是由一个叫“梯度下降”的方法控制着,这个方法可以保证每次微调都是向“正确”的方向调整。只要把数据给它,它就能自动调整,一直调到最优,程序才停下来。这就是逻辑回归的原理。
实际上,我们不一定非要用直线来划分,用曲线也是可以的,而且效果可能会更好。
比如改为这样的曲线,错误数就会降到4,这比刚才到使用直线的最优值5还要低。也就是说,这个分类效果更好。
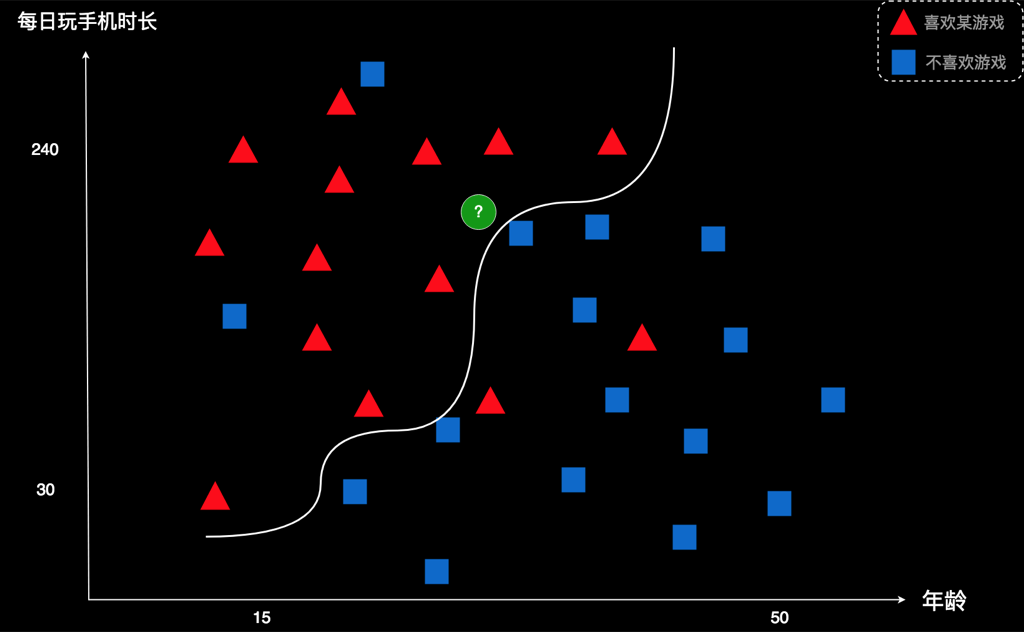
曲线也是回归出来的。初始的时候,随机画一条曲线,然后慢慢调整曲线的位置、各个拐角的弯曲度,等等,一直调整到最终这个样子。
我们把这个过程称之为“训练”。“训练”是人工智能领域里面常用的一个词语。比如,打败人类围棋冠军的AlphaGo就是训练出来的;图像识别、语音识别、自动驾驶等等,里面用到的模型也都是训练出来的。
训练这个词,是借鉴过来的。人工智能出现之前,训练这个词用的最多的地方有可能是马戏团。比如,马戏团让猴子骑自行车表演,是需要先对这只猴子进行训练的。猴子最初是不会骑车的,骑上去就倒了。不过,让它多骑几次,就会有一点点进步。它每次进步一点,训练师就给他一点奖励,比如喂它一点食物,抚摸它几下。如果骑的不好,比如摔倒了,训练师就惩罚它,比如对它大吼,甚至打它。这样,即使猴子听不懂人类的语言,人与猴之间仅仅通过奖励和惩罚的机制,就能教会猴子骑自行车。

人工智能里的算法也是这样的,工程师通过奖励和惩罚计算机程序来训练模型。
那怎么奖励计算机程序呢?其实很简单。就拿我们的逻辑回归来说,程序不断调整划分线的过程,实际上是在不断调整表达那条线的参数。如果某一次参数的调整,使得划分的错误率变低,说明调整的好,我们就把这次调整的参数保留下来,“保留”就是对程序对奖励。如果这次调整使得错误率变高,就把他抛弃掉,“抛弃”就是对计算机对惩罚。这样,留到最后的参数就是最好的参数,最后的曲线,就是最优的曲线。
实际做这件事情的是一个叫损失函数的东西,它类似训练猴子中的,用于判断猴子做的“好”还是“不好”这样的机制,并且对“好”和“不好”进行量化。如果损失函数做的好,我们就能训练出一个更好的模型。
跟猴子一样,计算机也听不懂人类的语言,但是我们只要通过奖励和惩罚它,就能训练出一个好的模型。
好了,今天我们介绍了逻辑回归算法,并且用它对新用户进行了预测。
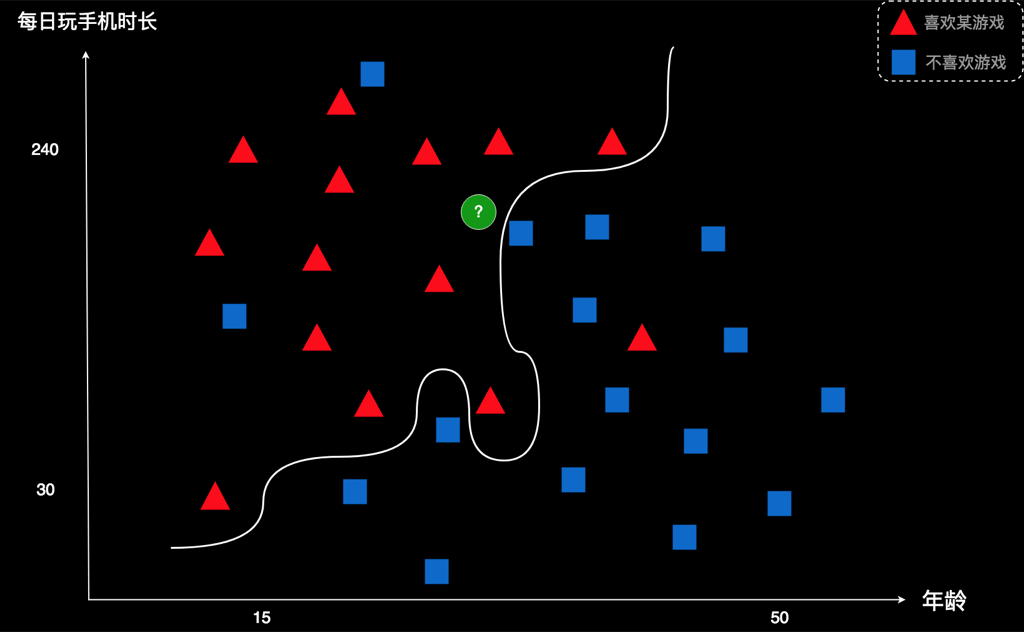
最后,我给大家留一个思考题。对于今天的案例,这里有一个新的划分曲线,它的错误数只有3,比刚才那条曲线错误数为更低,你认为这是不是一种更好的划分方式呢?如果想到了答案,就留在评论中。
相关文章:














 2832
2832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









