






三
.
使用命令和插件监控更多信息
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
个人觉得这里是全篇文章里面最难理解的部分,我也将尽力解释清楚.还是那句话,原理了解了什么就都简单了.
在上篇文章里面,我们已经增加了三个监控项目,分别监控nagios-server,dbpi,yahoon这三台主机是否存活.现在我对这三台机器分别做了如下设置
开放nagios-server的ftp
开放dbpi的ssh
开放yahoon的IIS
这篇文章里面所做的就是对这些服务进行监控,另外我们还要监控nagios-sever的根分区的使用情况.
在这个系列的开篇<nagios全攻略(一)----准备阶段>里面谈到nagios的原理时,特别指出了nagios本身并没有监控的功能,所有的监控是由插件完成的,插件将监控的结果返回给nagios,nagios分析这些结果,以web的方式展现给我们,同时提供相应的报警功能(这个报警的功能也是由插件完成的)
所有的这些插件是一些实现特定功能的可执行程序,默认安装的路径是/usr/local/nagios/libexec,可以查看

<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
这些程序都是可以独立执行的,使用方法可以通过”命令名 –h”来查看
例如,我们查看check_disk这个插件的用法则可以使用check_disk –h,如下图
|
[root@server1 libexec]#
./check_disk -h
check_disk (nagios-plugins 1.4.9) 1.91
Copyright (c) 1999 Ethan Galstad <[email]nagios@nagios.org[/email]>
Copyright (c) 1999-2006 Nagios Plugin Development Team
This plugin checks the amount of used disk space on a mounted file system
and generates an alert if free space is less than one of the threshold values
Usage: check_disk -w limit -c limit [-p path | -x device] [-t timeout][-m] [-e] [-W limit] [-K limit] [-v] [-q] [-E]
Options:
……
以下略
|
输出的资料十分详细给出了这个插件的功能,使用方法,参数意义等,对于每一个插件都是这样.所以当你不懂某个插件怎么使用时就好好读读吧.从上面的输出可以看到check_disk这个插件是用来检查磁盘使用情况的.
我现在来独立执行它,例如查看根分区的使用情况,执行
[root@server1 libexec]# ./check_disk -w 10% -c 5% /
命令的含义是检查分区/的使用情况,若剩余10%以下,为警告状态(warning),5%以下为严重状态(critical),
执行后我们会看到下面这条信息
DISK WARNING - free space: / 487 MB (6% inode=78%);| /=7449MB;7524;7942;0;8361
说明当前是warning的状态,空闲空间只有6%了.如果nagios收到这些状态结果就会采取报警等措施了
或许在这里大家又迷糊了,我们在定义某个监控项目时,所用的监控命令都是来自commands.cfg的,这和这些插件有什么关系???想到了吧,commands.cfg中定义的监控命令就是使用的这些插件.举个例子,之前我们已经不止一次用到了check-host-alive这个命令,打开commands.cfg就可以看到这个命令的定义,如下:
|
################################################################################
#
# SAMPLE HOST CHECK COMMANDS
#
################################################################################
# This command checks to see if a host is "alive" by pinging it
# The check must result in a 100% packet loss or 5 second (5000ms) round trip
# average time to produce a critical error.
# Note: Only one ICMP echo packet is sent (determined by the '-p 1' argument)
# 'check-host-alive' command definition
define command{
command_name check-host-alive
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 1
}
|
command_name check-host-alive
这句话的意思是定义的命令名是check-host-alive,也就是我们在services.cfg中使用的名称
执行的操作是
$USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 1
其中$USER1$是在resource.cfg文件中定义的,代表插件的安装路径.就如我们上面看到的那样$USER1$=/usr/local/nagios/libexec,至于$HOSTADDRESS$,则默认被定义为监控主机的地址.
简单的说,我们在services.cfg中定义了对dbpi执行check-host-alive命令,实际上就是执行了
/usr/local/nagios/libexec/ check_ping -H dbpi的ip地址 -w 3000.0,80% -c 5000.0,100% -p 1
实际上check-host-alive只是这一长串命令的简称而已,而在services.cfg中都是使用简称的.
在commands.cfg中定义了很多这样的命令简称.基本上我们常用的监控项目都包含了,例如ftp,http,本地的磁盘,负载等等.
我们再看一个命令,check_local_disk定义如下
|
# 'check_local_disk' command definition
define command{
command_name check_local_disk
command_line $USER1$/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$
}
|
check_local_disk实际上是执行的check_disk插件.这里的$ARG1$, $ARG2$, $ARG3$是什么意思呢?在之前我们已经提到了这个check_disk这个插件的用法,-w的参数指定磁盘剩了多少是警告状态,-c的参数指定剩多少是严重状态,-p用来指定路径.
在使用check-host-alive的时候,只需要在services.cfg中直接写上这个命令名check-host-alive.后面没任何的参数.而使用check_local_disk则不同,在services.cfg中这要这么写
check_local_disk!10%!5%!/
在命令名后面用!分隔出了3个参数,10%是$ARG1$的值,5%是$ARG2$的值,/ 是$ARG3$的值,
我不知道讲的是否清楚,头晕的就在后面提问哈.简单的一句话就是
|
services.cfg
定义监控项目用某个命令
↓
这个命令必须在commands.cfg中定义
↓
定义这个命令时使用了libexec下的插件
|
如果命令不带$ARG1$就可以在services.cfg中直接使用,如果带了使用时就带上参数,以!相隔
如果你理解了上面我说的”昏话”,下面的事情就简单的多了.我们要监控什么就修改相应的 命令就行了.
1).监控nagios-server的ftp
编辑services.cfg 增加下面的内容,基本上就是copy上节我们定义监控主机存活的代码.略做修改.
|
define service{
host_name nagios-server
要监控的机器
,
给出机器名
,
注意必须是
hosts.cfg
中定义的
service_description check ftp
给这个监控项目起个名字吧
,
任意起
,
你自己懂就行
check_command check_ftp
所用的命令
,
当然必须是
commands.cfg
中定义了的
max_check_attempts 5
normal_check_interval 3
retry_check_interval 2
check_period 24x7
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
contact_groups sagroup
}
|
2).监控dbpi的ssh
|
define service{
host_name dbpi
意义同上
service_description check-ssh
意义同上
check_command check_tcp!22
ssh
所用的
tcp
的
22
号端口
,
我就用
commands
中定义的
check_tcp
命令
.
至于
!22
的意思不用我说了吧
.
max_check_attempts 5
normal_check_interval 3
retry_check_interval 2
check_period 24x7
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
contact_groups sagroup
}
|
3).监控yahoon的IIS
|
define service{
host_name yahoon
service_description check-http
check_command check_http
max_check_attempts 5
normal_check_interval 3
retry_check_interval 2
check_period 24x7
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
contact_groups sagroup
}
|
4).监控nagios-sever的根分区的使用情况.
|
define service{
host_name nagios-server
service_description check disk
check_command check_local_disk!10%!5%!/
max_check_attempts 5
normal_check_interval 3
retry_check_interval 2
check_period 24x7
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
contact_groups sagroup
}
|
修改了配置文件,当然就要重新启动了,简单的方法杀掉nagios进程,然后重新启动
/usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg
等几分钟,你会看到下面这张图
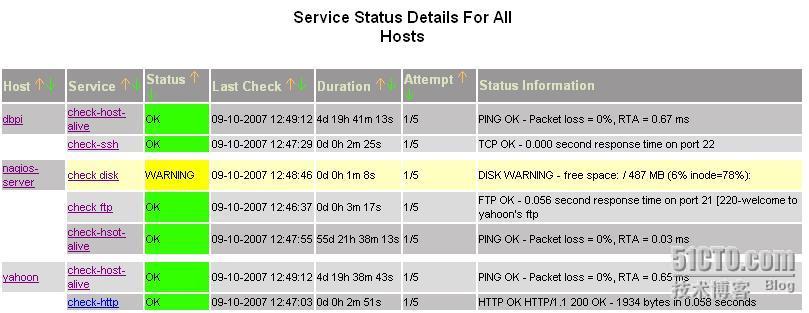 可以看到我的nagios-seerver上磁盘空间已经不足了,是warning.
可以看到我的nagios-seerver上磁盘空间已经不足了,是warning.
哈哈,本章到此结束!!!
但是,但是但是…事情远远没完.我提几个问题:你知道了nagios-server这台机器的磁盘使用情况,可是dbpi这台机器的使用情况呢?dbpi当前登陆多少用户?多少进程?cpu负载如何?
ftp,ssh,http这些都是向外开放的服务,即使不用nagios我自己也可以试的出来,随便找一台机器看能不能访问这些服务就行了.可是磁盘容量,cpu负载,当前登陆用户数量你不登录这台机器原则上是不可能知道的,因为他们是”本地信息”.当然,***可以做到…下节我们就让nagios做”***”..
注:我们通过nagios查看到了nagios-server这台机的磁盘信息,这应该属于”本地信息”,本地信息不是得不到的吗??这是因为我们nagios运行在这台机器上啊.它当然可以检测自己所在的机器,对dbpi和yahoon…暂时看来是无能为力了.
敬请期待
nagios
全攻略
(
四
)----
使用
NRPE
监控
LINUX
上的
”
本地信息
”
转载于:https://blog.51cto.com/sookk8/94068















 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









