







71、题目要求 : 判断文件并计算单词
【核心要点】
1、[ -f file ] 判断否有某个文件
2、grep -cw 获取单词个数
题目要求
- 判断所给目录内哪些二级目录下有没有text.txt文件。
- 有text.txt文件的二级目录,计算出该test.txt文件里面所给出单词的次数。
- 假如脚本名字为1.sh, 运行脚本的格式为 ./1.sh 123 root,其中123为目录名字,而root为要计算数量的单词。
参考答案
#!/bin/bash
#这个脚本用来判断文件是否存在并计算单词个数
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-11
if [ $# -ne 2 ]
then
echo "请提供两个参数,第一个参数是目录名字,第二个参数是单词"
exit
fi
cd $1
for f in `ls .`
do
if [ -d $f ]
then
if [ -f $f/test.txt ]
then
n=`grep -cw "$2" $f/test.txt`
echo "$1/$f目录下面有test.txt, 该test.txt里面的有$n个$2."
fi
fi
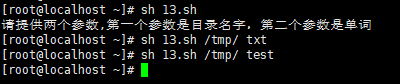
done实例 :
执行脚本,查看结果
注意 :
判断一个目录下,有有没有文件,使用-f test.txt
if [ $# -ne 2 ] #如果不等于2
cd $1 # 切换到所给目录下
if [ -f $f/test.txt ] #判断目录下面有没有test.txt文件
n=`grep -cw "$2" $f/test.txt` #查找$2在/test.txt出现的次数 -c:计算次数;-w :作为一个的单词
72、题目要求 : 打印正方形
题目要求
交互式脚本,根据提示,需要用户输入一个数字作为参数,最终打印出一个正方形。在这里我提供一个linux下面的特殊字符■,可以直接打印出来。
示例: 如果用户输入数字为5,则最终显示的效果为
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
■ ■ ■ ■ ■
【核心要点】
echo -n 不换行
参考答案
#!/bin/bash
#这个脚本用来打印正方形
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-11
while :
do
read -p "Please input a nuber: " n
n1=`echo $n|sed 's/[0-9]//g'`
if [ -n "$n1" ]
then
echo "$n is not a nuber."
continue
else
break
fi
done
for i in `seq 1 $n`
do
for j in `seq 1 $n`
do
echo -n "■ "
done
echo
done实例 :
打印出来,一列三行。

添加for循环
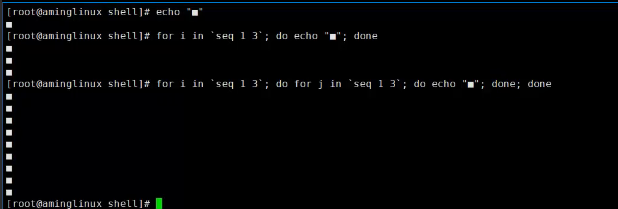
显示三排三列方块,方块后面要有空格。


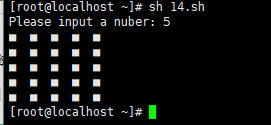
执行脚本,查看结果。输入数字几,就显示几行几列方块。
注意 :
n1=`echo $n|sed 's/[0-9]//g'` #清空所有的数字
if [ -n "$n1" ] #如果n1,不为空。
for i in `seq 1 $n` #打印$n行。
for j in `seq 1 $n` #打印$n行,$n列。
73、题目要求 : 问候用户
写一个脚本,依次向/etc/passwd中的每个用户问好,并且说出对方的ID是什么,如:
Hello, root,your UID is 0.
【核心要点】
对/etc/passwd每一行做遍历,截取第一段用户名和第三段uid,然后格式化输出即可
参考答案
#!/bin/bash
#这个脚本用来问候用户
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-11
cat /etc/passwd |while read line
do
username=`echo $line|awk -F ':' '{print $1}'`
uid=`echo $line|awk -F ':' '{print $3}'`
echo "Hello, $username, your uid is $uid."
done
实例 :
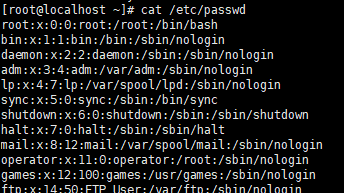
uid在第三段,用户名在第一段,截取出来。然后说 " Hello your uid is $3 "
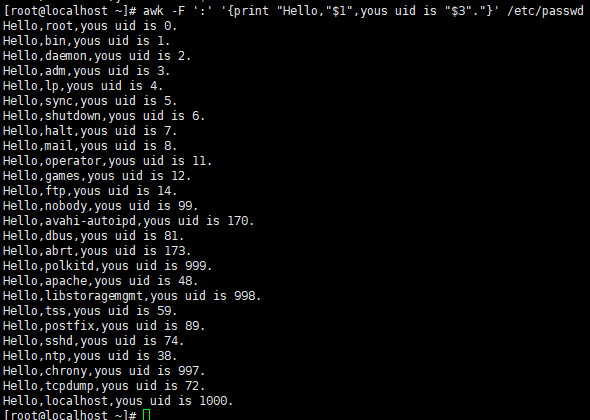
执行脚本,查看结果
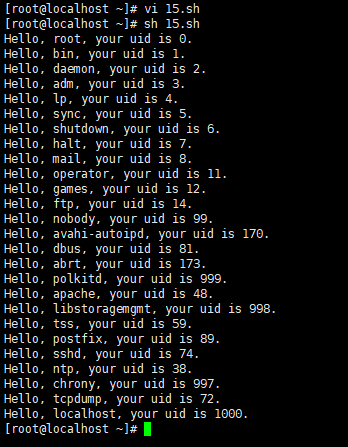
注意 :
username=`echo $line|awk -F ':' '{print $1}'` #打印出来,第一段的username.
uid=`echo $line|awk -F ':' '{print $3}'` #打印出来,第一段的uid.
74、题目要求 : 格式化输出xml
linux系统 /home目录下有一个文件test.xml,内容如下:
<configuration>
<artifactItems>
<artifactItem>
<groupId>zzz</groupId>
<artifactId>aaa</artifactId>
</artifactItem>
<artifactItem>
<groupId>xxx</groupId>
<artifactId>yyy</artifactId>
</artifactItem>
<!-- </artifactItem><groupId>some groupId</groupId>
<version>1.0.1.2.333.555</version> </artifactItem>-->
</artifactItems>
</configuration>
请写出shell脚本删除文件中的注释部分内容,获取文件中所有artifactItem的内容,并用如下格式逐行输出: artifactItem:groupId:artifactId:aaa
【核心要点】
参考答案
#!/bin/bash
#这个脚本用来格式化xml文件
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-11
sed '/<!--.*-->/d' test.xml > test2.xml
egrep -n '<!--|\-\->' test2.xml |awk -F ':' '{print $1}' > /tmp/line_number1.txt
n=`wc -l /tmp/line_number1.txt|awk '{print $1}'`
n1=$[$n/2]
for i in `seq 1 $n1`
do
j=$[$i*2]
k=$[$j-1]
x=`sed -n "$k"p /tmp/line_number1.txt`
y=`sed -n "$j"p /tmp/line_number1.txt`
sed -i "$x,$y"d test2.xml
done
grep -n 'artifactItem>' test2.xml |awk '{print $1}' |sed 's/://' > /tmp/line_number2.txt
n2=`wc -l /tmp/line_number2.txt|awk '{print $1}'`
get_value(){
sed -n "$1,$2"p test2.xml|awk -F '<' '{print $2}'|awk -F '>' '{print $1,$2}' > /tmp/value.txt
cat /tmp/value.txt|while read line
do
x=`echo $line|awk '{print $1}'`
y=`echo $line|awk '{print $2}'`
echo artifactItem:$x:$y
done
}
n3=$[$n2/2]
for j in `seq 1 $n3`
do
m1=$[$j*2-1]
m2=$[$j*2]
nu1=`sed -n "$m1"p /tmp/line_number2.txt`
nu2=`sed -n "$m2"p /tmp/line_number2.txt`
nu3=$[$nu1+1]
nu4=$[$nu2-1]
get_value $nu3 $nu4
done
实例 :
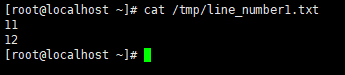
查看/tmp/line_number1.txt中的行数


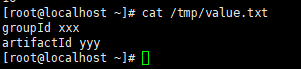
求出来groupID和artifactID对应的值
执行脚本,查看结果 ; 列出来groupID、artifactlID、groupID、artigfactID对应的id.
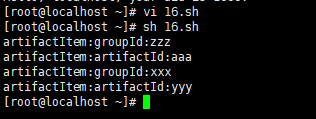
注意 :
sed '/<!--.*-->/d' test.xml > test2.xml #/d删除'/<!--.*-->/d'里面的内容,并重定向到test2.xml
egrep -n '<!--|\-\->' test2.xml |awk -F ':' '{print $1}' > /tmp/line_number1.txt #只查找'<!--|\-\->'前面的行号,并打印出来 ,并写入到/tmp/line_number1.txt
j=$[$i*2] #$便利的数字,乘以2,就是偶数了
k=$[$j-1]
x=`sed -n "$k"p /tmp/line_number1.txt` #取得数字,11
y=`sed -n "$j"p /tmp/line_number1.txt` #取得数字,12
sed -i "$x,$y"d test2.xml #11到12直接删除
for i in `seq 1 $n1` #1到$n1
n1=$[$n/2] #$n除以2,原因:查看有几对行号
wc -l /tmp/line_number1.txt|awk '{print $1}' #统计过滤出来的/tmp/line_number1.txt中的对数,并打印出对数。
75、题目要求 : 小函数
请撰写一个shell函数,函数名为 f_judge,实现以下功能
-
当/home/log目录存在时将/home目录下所有tmp开头的文件或目录移到/home/log目录。
-
当/home/log目录不存在时,创建该目录,然后退出。
【核心要点】
1、[ -d /home/log ]判断目录是否存在
2、查找tmp开头的文件或目录命令是find /home -name "tmp"
参考答案
#!/bin/bash
#这个脚本用来写一个小函数
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-11
f_judge()
{
if [ -d /home/log ]
then
#find /home -name "tmp*" |xargs -i mv {} /home/log/
find /home -name "tmp*" -exec mv {} /home/log/ \;
else
mkdir /home/log
exit
fi
}
f_judge
实例 :
执行脚本,查看结果
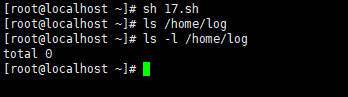
注意 :
find /home -name "tmp*" |xargs -i mv {} /home/log/ #查找/home目录下所有tmp开头的文件或目录移到/home/log目录。
find /home -name "tmp*" -exec mv {} /home/log/ \; #查找/home目录下所有tmp开头的文件或目录移到/home/log目录。
76、题目要求 : 批量杀进程
linux系统中,目录/root/下有一个文件ip-pwd.ini,内容如下:
10.111.11.1,root,xyxyxy
10.111.11.2,root,xzxzxz
10.111.11.3,root,123456
10.111.11.4,root,xxxxxx
……
文件中每一行的格式都为linux服务器的ip,root用户名,root密码,请用一个shell批量将这些服务器中的所有tomcat进程kill掉。
【核心要点】
expect
参考答案
#!/bin/bash
#这个脚本用来批量杀tomcat进程
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-12
cat > kill_tomcat.expect <<EOF
#!/usr/bin/expect
set passwd [lindex \$argv 0]
set host [lindex \$argv 1]
spawn ssh root@\$host
expect {
"yes/no" { send "yes\r"; exp_continue}
"password:" { send "\$passwd\r" }
}
expect "]*"
send "killall java\r"
expect "]*"
send "exit\r"
EOF
chmod a+x kill_tomcat.expect
cat ip-pwd.ini|while read line
do
ip=`echo $line |awk -F ',' '{print $1}'`
pw=`echo $line |awk -F ',' '{print $3}'`
./kill_tomcat.expect $pw $ip
done
实例 :
远程杀死Tomcat的进程
![]()
注意 :
expect "]*" #]*匹配到的关键词,*表示统配
send "killall java\r" #发送killall java指令
set passwd [lindex \$argv 0] #
set host [lindex \$argv 1] #
spawn ssh root@\$host #登录机器,然后执行指令
cat > kill_tomcat.expect <<EOF #查看执行的结果,然后结束
chmod a+x kill_tomcat.expect #添加执行权限kill_tomcat.expect
ip=`echo $line |awk -F ',' '{print $1}'` #IP在第一段,打印出来
pw=`echo $line |awk -F ',' '{print $3}'` #密码在第三段,打印出来
./kill_tomcat.expect $pw $ip #然后执行kill_tomcat.expect脚本,第一个参数,第二参数,批量远程执行。
77、题目要求 : 查找老日志打包
写一个脚本查找/data/log目录下,创建时间是3天前,后缀是*.log的文件,打包后发送至192.168.1.2服务上的/data/log下,并删除原始.log文件,仅保留打包后的文件。
【核心要点】
find ./ mtime +3
参考答案
#!/bin/bash
#这个脚本用来查找老日志打包
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-12
cd /data/log
find . -type f -name "*.log" -mtime +3 > /tmp/old_log
d=`date +%F`
tar czf $d.tar.gz `cat /tmp/old_log|xargs`
rsync -a $d.tar.gz 192.168.1.2:/data/log/
cat /tmp/old_log|xargs rm
实例 :
把文档中的内容,显示在一行
![]()
执行脚本,查看结果
注意 :
find . -type f -name "*.log" -mtime +3 > /tmp/old_log #查找3天前,创建的文件后缀是*.log的文件,并重定向到/tmp/old_log文件中。
d=`date +%F` #打印出当前的时间
tar czf $d.tar.gz `cat /tmp/old_log|xargs` # 打包的包名,是当前的日期发送到/tmp/old_log,并显示在一行
rsync -a $d.tar.gz 192.168.1.2:/data/log/ #打包后发送至192.168.1.2服务上的/data/log下
cat /tmp/old_log|xargs rm #查看,删除原始.log文件,
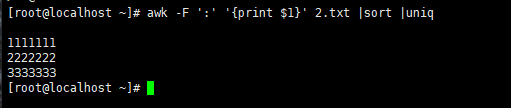
78、题目要求 : 处理文本
如果第一段一样的,规列到下面,有如下文本,其中前5行内容为
1111111:13443253456
2222222:13211222122
1111111:13643543544
3333333:12341243123
2222222:12123123123
用shell脚本处理后,按下面格式输出:
[1111111]
13443253456
13643543544
[2222222]
13211222122
12123123123
[3333333]
12341243123
【核心要点】
第一段排序,然后遍历
参考答案
#!/bin/bash
#这个脚本用来处理文本
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-12
for w in `awk -F ':' '{print $1}' 3.txt |sort |uniq`
do
echo "[$w]"
awk -v w2=$w -F ':' '$1==w2 {print $2}' 3.txt
done实例 :
截取2.txt第一段,排序,去重复。

执行脚本,查看结果。
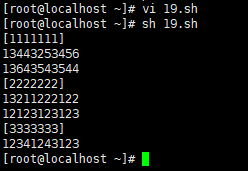
awk传递一个shell变量到awk中,变成w2,当 $1等于w2的情况下,然后打印第二段。对文档进行排序。
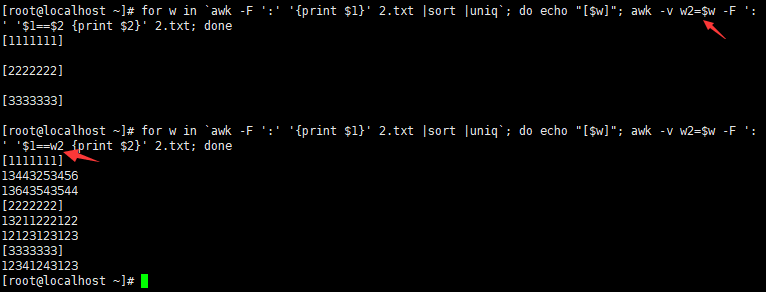
注意 :
for w in `awk -F ':' '{print $1}' 3.txt |sort |uniq` #查找并打印出第一行,排序,去重复。for w in :循环遍历。
awk -v w2=$w -F ':' '$1==w2 {print $2}' 3.txt #传递一个shell变量到$2,然后打印第二段。
79、题目要求 : 批量删除日志
需求背景: 服务器上,跑的lamp环境,上面有很多客户的项目,每个项目就是一个网站。 由于客户在不断增加,每次增加一个客户,就需要配置相应的mysql、ftp以及httpd。这种工作重复性非常强的,所以用脚本实现非常合适。mysql增加的是对应客户项目的数据库、用户、密码,ftp增加的是对应项目的用户、密码(使用vsftpd,虚拟用户模式),httpd就是要增加虚拟主机配置段。
参考答案
要求:两类机器一共300多台,写个脚本自动清理这两类机器里面的日志文件。在堡垒机批量发布,也要批量发布到crontab里面。
A类机器日志存放路径很统一,B类机器日志存放路径需要用匹配(因为这个目录里除了日志外,还有其他文件,不能删除。匹配的时候可用.log)
A类:/opt/cloud/log/ 删除7天前的 B类: /opt/cloud/instances/ 删除15天前的
要求写在一个脚本里面。不用考虑堡垒机上的操作,只需要写出shell脚本。
【核心要点】
判断机器是A类还是B类是关键点
参考答案
#!/bin/bash
#这个脚本用来删除老日志
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-12
dir1=/opt/cloud/log/
dir2=/opt/cloud/instance/
if [ -d $dir1 ]
then
find $dir1 -type f -mtime +7 |xargs rm
elif [ -d $dir2 ]
then
find $dir2 -name "*.log" -type f -mtime +15 |xargs rm
fi 实例 :
执行脚本,查看结果。
![]()
注意 :
find $dir2 -name "*.log" -type f -mtime +15 |xargs rm #查找目录2中,15天前的日志,并删除15天前的的日志。
find $dir1 -type f -mtime +7 |xargs rm #查找目录1中,7天前的日志,并删除7天前的的日志。
if [ -d $dir1 ] #如果目录1存在执行下一步查找。
elif [ -d $dir2 ] #如果目录2存在执行下一步查找。
80、题目要求 : 房贷计算器
贷款有两种还款的方式:等额本金法和等额本息法,简单说明一下等额本息法与等额本金法的主要区别:
等额本息法的特点是:每月的还款额相同,在月供中“本金与利息”的分配比例中,前半段时期所还的利息比例大、本金比例小,还款期限过半后逐步转为本金比例大、利息比例小。所支出的总利息比等额本金法多,而且贷款期限越长,利息相差越大。 等额本金法的特点是:每月的还款额不同,它是将贷款额按还款的总月数均分(等额本金),再加上上期剩余本金的月利息,形成一个月还款额,所以等额本金法第一个月的还款额最多 ,而后逐月减少,越还越少。所支出的总利息比等额本息法少。
两种还款方式的比较不是我们今天的讨论范围,我们的任务就是做一个贷款计算器。其中:
等额本息每月还款额的计算公式是:
每月还款额=[贷款本金×月利率×(1+月利率)^还款月数]÷[(1+月利率)^还款月数-1]
等额本金每月还款额的计算公式是:
每月还款额=贷款本金÷贷款期数+(本金-已归还本金累计额)×月利率
【核心要点】
搞清楚公式
参考答案
#!/bin/bash
#这个脚本用来实现简易的房贷计算器
#作者:猿课-阿铭 www.apelearn.com
#日期:2018-12-12
read -p "请输入贷款总额(单位:万元):" sum_w
read -p "请输入贷款年利率(如年利率为6.5%,直接输入6.5):" y_r
read -p "请输入贷款年限(单位:年):" y_n
echo "贷款计算方式:"
echo "1)等额本金计算法"
echo "2)等额本息计算法"
read -p "请选择贷款方式(1|2)" type
#贷款总额
sum=`echo "scale=2;$sum_w*10000 " | bc -l`
#年利率
y_r2=`echo "scale=6;$y_r/100 " | bc -l`
#月利率
m_r=`echo "scale=6;$y_r2/12 " | bc -l`
#期数
count=$[$y_n*12]
echo "期次 本月还款额 本月利息 未还款额"
jin()
{
#月还款本金m_jin=贷款总额sum/期数count
m_jin=`echo "scale=2;($sum/$count)/1 " | bc -l`
#定义未还本金r_jin(第一期应该是贷款总额)
r_jin=$sum
for((i=1;i<=$count;i++))
do
#本月利息m_xi=剩余本金*月利率
m_xi=`echo "scale=2;( $r_jin*$m_r)/1"|bc -l`
#本月还款m_jinxi=月还本金m_jin+本月利息m_xi
m_jinxi=`echo "scale=2;( $m_jin+$m_xi)/1"|bc -l`
#已还款本金jin=月还本金m_jin*期数i
jin=`echo "scale=2;( $m_jin*$i)/1"|bc -l`
#剩余本金r_jin=贷款总额sum-已还本金jin
r_jin=`echo "scale=2;( $sum-$jin)/1"|bc -l`
if [ $i -eq $count ]
then
#最后一月的还款额应该是每月还款本金+本月利息+剩余本金
m_jinxi=`echo "scale=2;( $m_jin+$r_jin+$m_xi)/1"|bc -l`
#最后一月的剩余本金应该是0
r_jin=0
fi
echo "$i $m_jinxi $m_xi $r_jin"
done
}
xi()
{
#每期还款m_jinxi=(贷款总额sum*月利率m_r*((1+月利率m_r)^期数count))/(((1+月利率m_r)^期数count)-1)
m_jinxi=`echo "scale=2;(($sum*$m_r*((1+$m_r)^$count))/(((1+$m_r)^$count)-1))/1 " | bc -l`
#定义未还本金r_jin(第一期应该是贷款总额)
r_jin=$sum
for((i=1;i<=$count;i++))
do
#本期利息m_xi=剩余本金r_jin*月利率m_r
m_xi=`echo "scale=2;( $r_jin*$m_r)/1"|bc -l`
#本期本金m_jin=本期本息m_jinxi-本期利息m_xi
m_jin=`echo "scale=2;($m_jinxi-$m_xi)/1 " | bc -l`
#未还本金r_jin=上期未还本金r_jin-本期应还本金m_jin
r_jin=`echo "scale=2;($r_jin-$m_jin)/1 " | bc -l`
if [ $i -eq $count ]
then
#最后一月本息m_jinxi=本期本金m_jin+未还本金r_jin
m_jinxi=`echo "scale=2;($m_jin+$r_jin)/1 " | bc -l`
#最后一月的剩余本金应该是0
r_jin="0.00"
fi
echo "$i $m_jinxi $m_xi $r_jin"
done
}
case $type in
1)
jin
;;
2)
xi
;;
*)
exit 1
;;
esac实例 :
执行脚本,查看结果.
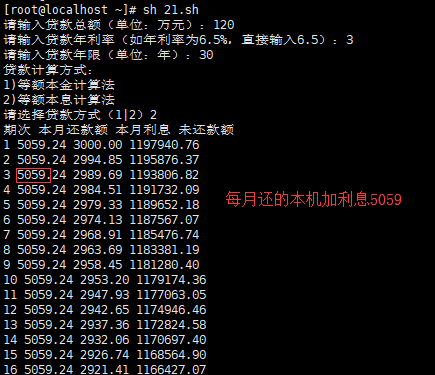
注意 :
#贷款总额
sum=`echo "scale=2;$sum_w*10000 " | bc -l` #scale=2表示小数点2位 ;$sum_w*10000表示乘以10000
#年利率
y_r2=`echo "scale=6;$y_r/100 " | bc -l` #scale=6表示小数点六位 ;$y_r/100表示年利率除以100。
#月利率
m_r=`echo "scale=6;$y_r2/12 " | bc -l` #scale=6表示小数点六位 ;$y_r2/12表示月利率除以12
如果有能力提前还款,选择第一种 : 等额本金法。
等额本息法 : 意思是利息相同,每月还款相同 ;提前还款,也要还利息。银行工作人员一般会推荐你等额本息法,让你多还钱。
来源 :https://github.com/aminglinux/shell100/blob/master/61.md















 4932
4932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









