







为了提高查找消息的性能,从0.8开始,为每个日志文件添加了对应的索引文件。
OffsetIndex对象对应管理磁盘上的1个索引文件,与上一节分析的FileMessageSet共同构成1个
LogSegment对象。
---
先来介绍索引文件中的索引项的格式。
每个索引项占了8个字节
相对offset --- 4个字节,也就是第多少条消息,相对于本文件对应的绝对offset来说的。
物理地址 --- 4个字节,索引消息在日志文件中的position位置

这样就实现了offset与物理地址之间的映射。
这里是稀疏索引,所以在FileMessageSet中查询数据的时候,会有个连续查询然后判断的过程。
如果是详细索引,就不会出现这种情况。
---
相对offset表示的是消息相对于baseOffset的偏移量。
baseOffset体现在文件名里面。

这样还可以减少索引文件占用的空间,用4个字节表示相对offset,绝对offset放在文件名里。
--- 关于稀疏索引
Kafka使用稀疏索引的方式构造消息的索引,不保证每个消息在索引文件中都有对应的索引项,这算是磁盘空间、内存空间、查找时间等多方面的折中。
不断减小索引文件大小的目的是为了将索引文件映射到内存里,在offsetIndex中会使用MappedByteBuffer将索引文件映射到内存中。
---接下来,看这个类
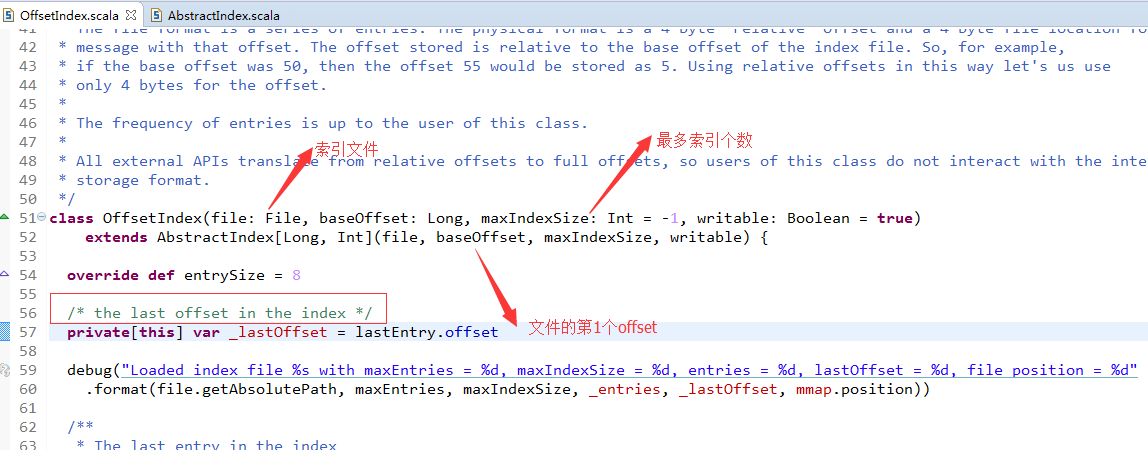
在offsetIndex初始化的时候,会初始化上面的这些字段。
@volatile
protected var mmap: MappedByteBuffer = {
val newlyCreated = file.createNewFile()
val raf = if (writable) new RandomAccessFile(file, "rw") else new RandomAccessFile(file, "r")
try {
/* pre-allocate the file if necessary */
if(newlyCreated) {
if(maxIndexSize < entrySize)
throw new IllegalArgumentException("Invalid max index size: " + maxIndexSize)
raf.setLength(roundDownToExactMultiple(maxIndexSize, entrySize))
}
/* memory-map the file */
val len = raf.length()
val idx = {
if (writable)
raf.getChannel.map(FileChannel.MapMode.READ_WRITE, 0, len)
else
raf.getChannel.map(FileChannel.MapMode.READ_ONLY, 0, len)
}
/* set the position in the index for the next entry */
if(newlyCreated)
idx.position(0)
else
// if this is a pre-existing index, assume it is valid and set position to last entry
idx.position(roundDownToExactMultiple(idx.limit, entrySize))
idx
} finally {
CoreUtils.swallow(raf.close())
}
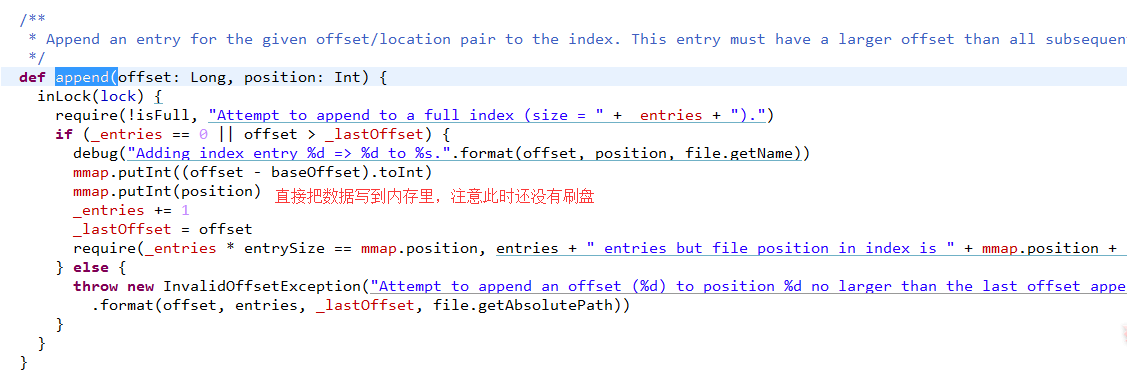
}
---
对于索引文件,更多的是查找,这里用什么算法?
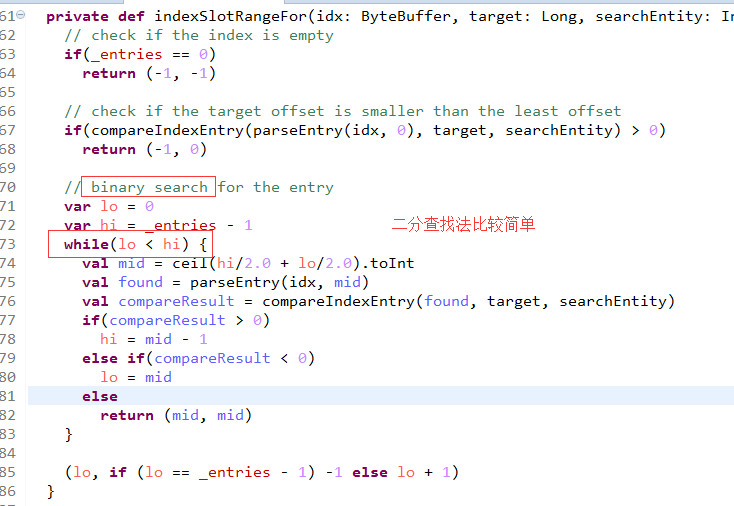
很简单,用二分查找法。
查找的目标是小于targetOffset的最大offset对应的物理地址,然后去FileMessageSet中去查找对应的数据。
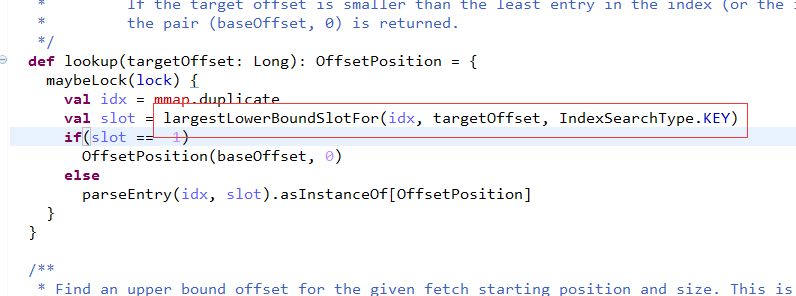

下面看indexSlotRangeFor的具体实现吧。
---
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









