






筛法求素数:
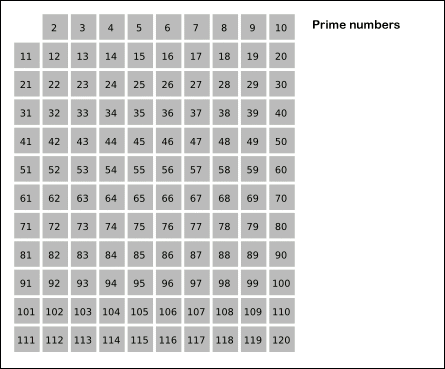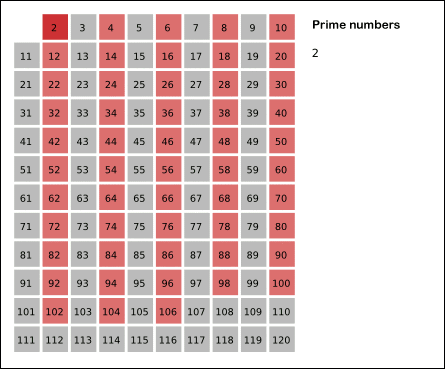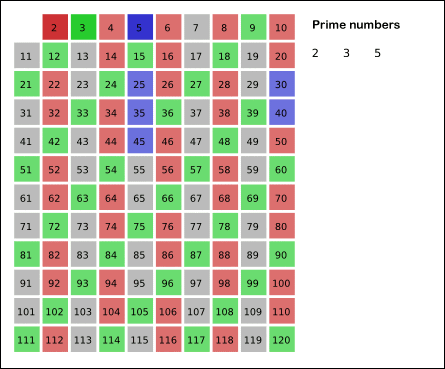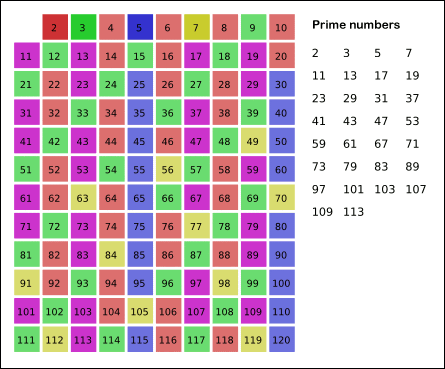
求n内的素数。先用2去筛,即把2留下,把2的倍数剔除掉;再用下一个质数,也就是3筛,把3留下,把3的倍数剔除掉;接下去用下一个质数5筛,把5留下,把5的倍数剔除掉;不断重复下去……。
由此,我们可以写出基础版的筛法求素:
const int maxn = 102410240; bool isp[maxn]; void init() { memset(isp, true, sizeof(isp)); isp[0] = isp[1] = false; const int max1 = sqrt(maxn + 0.5); for(int i = 2; i <= max1; i++) if(isp[i]) for(int j = i * i; j < maxn; j += i) isp[j] = false; }
经过测试,计算1亿以内的素数大概要2.7s多。
但是我们发现这个算法有可以优化的地方,因为有很多合数被重复标记。
比如40 被 质数2,5各标记了一次
下面这种优化版的算法可以把所有数只标记一次,令算法接近O(n)
const int maxn = 102410240; bool not_prime[maxn]; int prime[maxn/2], cnt; void init() { memset(not_prime, 0, sizeof(not_prime)); for (int i = 2; i < maxn; i++) { if (!not_prime[i]) prime[cnt++] = i; //位置1 for (int j = 0; j < cnt && i * prime[j] < maxn; j++) { not_prime[i * prime[j]] = 1; //位置2 if (!(i % prime[j])) break; //位置3 } } }
经过测试,求1亿以内的素数只要1.43秒
可以看到,比基础版的快了将近一倍(我的小mac运行速度本来就不快)
解释:
那么这个算法是如何做到保证每个数字只被标记一次的?
我这里粗略的解释一下我是如何理解它的:
对于所有大于1的整数,分为质数(素数)和合数这两种。
合数又可以分为两种:
1. 由1个质数和另1个质数组成
2. 由2个以上质数组成 ---> 把它进一步看成:由1个质数和1个合数组成
在位置1我们可以得到所有的质数,相信这个我就不用解释了。
在位置2我们标记所有的合数:
在位置2的时候一共由两种可能:
1. i为质数,prime[j]为质数
可以看到正好符合了合数的第一种,所以所有的第一种合数会被标记
2. i为合数,prime[j]为质数
正好符合合数的第二种,所有第二种合数会被标记
ok, 我们现在知道了这个算法会把所有合数标记出来,那么它是如果不重复标记的?
依靠位置3
因为任意一个合数a可以拆成一个比它小的质数b乘以一个比它小的合数c(强调“比它小”)
所以在i < a 的时候,一定有存在一个时间点是i等于c,且prime[j]等于b,且这一组合是唯一的,
那么当它们标记完之后就要退出。因为每一个合数都有一组唯一的a, b,这样就保证了这个算法的不重不漏。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









