






Spark代表着下一代大数据处理技术,并且,借着开源算法和计算节点集群分布式处理,Spark和Hadoop在执行的方式和速度已经远远的超过传统单节点的技术架构。但Spark利用内存进行数据处理,这让Spark的处理速度超过基于磁盘的Hadoop 100x 倍。\
但Spark和内存数据库Redis结合后可显著的提高Spark运行任务的性能,这源于Redis优秀的数据结构和执行过程,从而减小数据处理的复杂性和开销。Spark通过一个Redis连接器可以访问Redis的数据和API,加速Spark处理数据。\
Spark和Redis结合使用到底有多大的性能提升呢?结合这两者来处理时序数据时可以提高46倍以上——而不是提高百分之四十五。\
为什么这些数据处理速度的提升是很重要的呢?现在,越来越多的公司期望在交易完成的同时完成对应的数据分析。公司的决策也需要自动化,而这些需要数据分析能够实时的进行。Spark是一个用的较多的数据处理框架,但它不能做到百分之百实时,要想做到实时处理Spark还有很大一步工作需要做
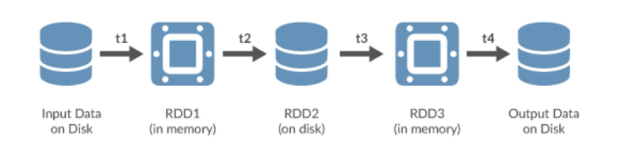
图1\
Spark RDD
\Spark采用弹性分布式数据集(RDD),可将数据存在易变的内存中或持久化到磁盘上。 RDD具有不可变化性,分布式存储在Spark集群的各节点,RDD经过tansform操作后创建出一个新的RDD。RDD是Spark中数据集的一种重要抽象,具有良好的容错性、高效的迭代处理。\
Redis
\Redis天生为高性能设计,通过良好的数据存储结构能达到亚毫秒级的延迟。Redis的数据存储结构不仅仅提高内存的利用和减小应用的复杂性,也降低了网络负载、带宽消耗和处理时间。Redis数据结构包括字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets), bitmaps, hyperloglogs 和 地理空间(geospatial)索引半径查询。\
下面来展示Redis的数据结构如何来简化应用的处理时间和复杂度。这里用有序集合来举例,一个以评分(score)大小排序的元素集合。

图2\
Redis能存储多种数据类型,并自动的以评分(score)排序。常见的例子有,按价格排序的商品,以阅读数排序的文章名,股票价格时序数据,带时间戳的传感器读数。
有序集合依赖Redis优秀的内建操作可以实现范围查询、求交集,可以非常快地(O(log(N)))完成添加,删除和更新元素的操作。Redis内建函数不仅减少代码开发,在内存中执行也减小了网络延时和带宽消耗,可达到亚毫秒级的吞吐延迟。特别地,对时序数据集合来讲,有序集合数据结构比使用内存键值对或使用磁盘的数据库,能给数据分析带来数量级上的性能提升。\
Spark-Redis connector
\为了提高Spark数据分析的能力,Redis团队开发了一个Spark-Redis connector,它使得Spark可以直接使用Redis作为数据源,顺理成章的Spark也能使用Redis的各数据结构,进而显著的提升Spark分析数据的速度。
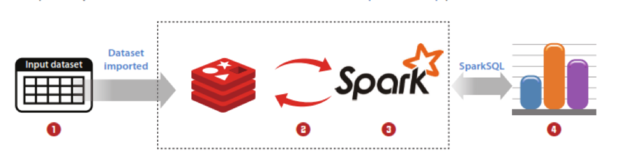
图3\
为了展示Spark结合Redis所产生的效果,Redis团队拿时序数据集合做基准测试,测试了Spark在不同情况下执行时间范围查询:Spark使用堆外内存;Spark使用Tachyon作为堆外缓存;Spark使用HDFS存储;Spark结合Redis使用。\
Redis团队改进了Cloudera的Spark分析时序数据的包,采用Redis有序集合数据结构加速时序数据分析,并且实现Spark访问Redis各类数据结构的接口。此Spark-Redis时序开发包主要做了两件事:\
- 它让Redis节点与Spark集群的节点自动匹配,确保每个Spark节点都使用本地Redis节点,这样可以明显的优化延迟时间; \
- 集成Spark DataFrame和Spark读取数据源,使得Spark SQL查询可自动转化,并能借助Redis能有效的恢复数据。
换句话说,使用Spark-Redis时序开发包意味着用户无需担心Spark和Redis两者如何使用。用户使用Spark SQL进行数据分析可以获得极大的查询性能提升。\
基准测试
\基准测试的时序数据集是跨度32年的1024个股票交易市场按天随机生成的数据。每个股票交易所都有有序数据集,以日期和元素属性(开盘价、最高价、最低价、收盘价等)排序,在Redis中以有序数据结构存储,采用Spark进行数据分析,描述如图4.
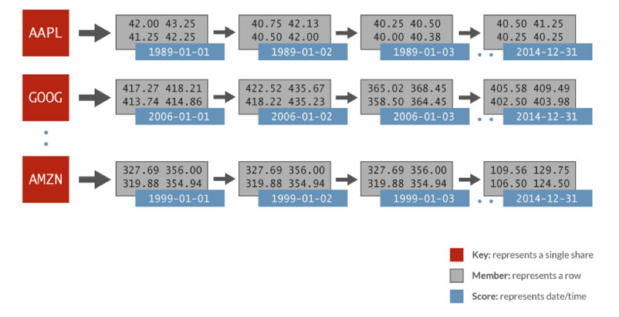
图4\
在上述列子中,就有序集合AAPL来看,有序数据集合以天为评分(score,以蓝色表示),每天相关的值为一行(Member,以灰色表示)。在Redis中,只要执行一个ZRANGEBYSCORE操作就可以获取一个指定时间范围内的所有股票数据,并且Redis执行此查询要比其他Key/Value数据库快100倍。
从图x可以看到,横向比较各种情况的基准测试,Spark结合Redis执行时间片的查询速度比Spark使用HDFS快135倍、比Spark使用堆内内存或Spark使用Tachyon作为堆外内存要快45倍。
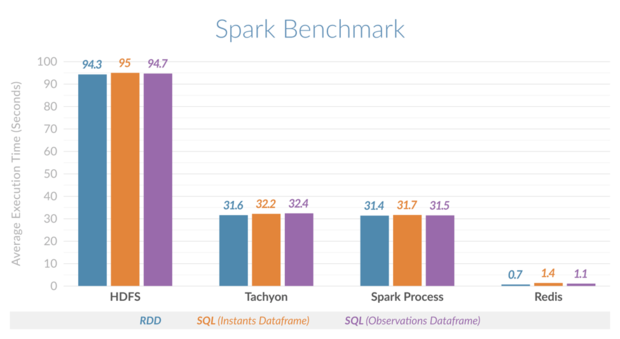
图5\
Spark-Redis其它应用
\按照“Getting Started with Spark and Redis”指南,你可以一步步安装Spark集群和使用Spark-Redis包。它提供一个简单的wordcount的例子展示如何使用Spark结合Redis。待你熟练使用后可以自己进一步挖掘、优化其他的Redis数据结构。
Redis的有序集合数据结构很适合时序数据集合,而Redis其他数据结构(比如,列表(lists), 集合(sets)和 地理空间(geospatial)索引半径查询)也能进一步丰富Spark的数据分析。当使用Spark抽取地理空间信息来获取新产品的人群偏好和邻近中心的位置,可结合Redis的地理空间(geospatial)索引半径查询来优化。\
Spark支持一系列的数据分析,包括SQL、机器学习、图计算和流式数据。Spark本身的内存数据处理能力有一定的限制,而借着Redis可以让Spark更快的做数据分析。其实Spark的DataFrame和Datasets已经在做类似的优化,先把数据进行结构化放在内存里进行计算,并且Datasets可以省掉序列化和反序列化的消耗。结合Spark和Redis,借助Redis的共享分布式内存数据存储机制,可以处理数百万个记录乃至上亿的记录
\时序数据的分析仅仅是一个开始,更多的性能优化可以参见:Spark-Redis。
\作者介绍
侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny分享相关技术文章。\\\\\感谢杜小芳对本文的审校。
\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。














 1952
1952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









