







1.云计算就是不在一台机器上,同时在好多台机器上运算。其实不是不想复杂,真是有点浪费生命。
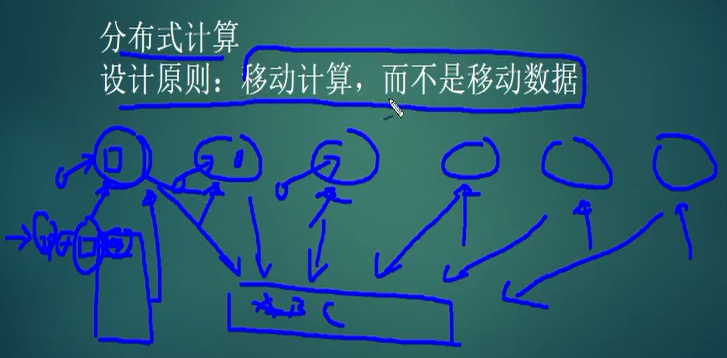
2.分布式的计算原则,移动计算而不是数据,因为机器很多,数据更多,汇总到一台机器上做运算,不但机器资源没有这么强悍,而且也不效率。
3.yarn (yet another resource negotiation)主要是为hadoop1计算框架解决资源(主要针对hdfs的cpu和内存)调度用的。
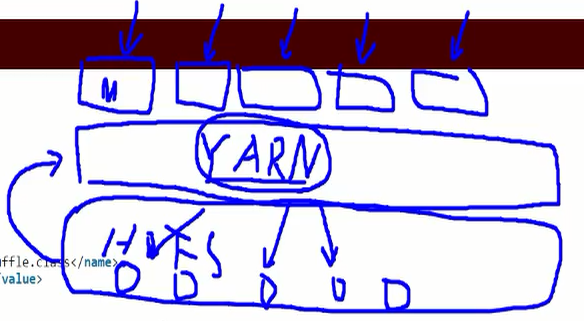
4.RM(resource manager)管理着多个NM(node manager),实际生产中RM和NN是分开的,原因是他们都比较耗资源,尤其是内存。NM和DN离的比较近,至少是在一个机架上。省了数据搬家的成本。
5.逻辑上来说NM和DN是可以分离的,所以不启动hdfs也可以直接启动yarn。启动时它也会读取slaves文件,所以在RM上用命令:start-yarn.sh就把所有集群都启动起来了。
6.hadoop一个包就包含了yarn,hdfs,mapreduce三个组件。只不过补充说下,着三个组件是相互独立的,没有谁必须跑在谁上面。
7.如何验证yarn是否启动了呢?start-yarn.sh/stop-yarn.sh后可以查看的路径:http://192.168.56.100:8088/,hdfs:http://192.168.56.100:50070
8.下面我们来跑一个mapreduce计算。
利用本机的mapreduce job程序测试,后查看生成的结果文件:

hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wcinput/input.text /wcoutput2
9.说个关键的,mapreduce要跑的话是需要把数据拉到本地来跑的,如果用yarn就不需要把数据拉到本地,而可以把计算发到数据附近去计算。
10.secondaryname是做checkpoint用的。
11.mapreduce形象的理解,按行拆,到多个机器map,map suffle,执行多个reduce,然后汇总。
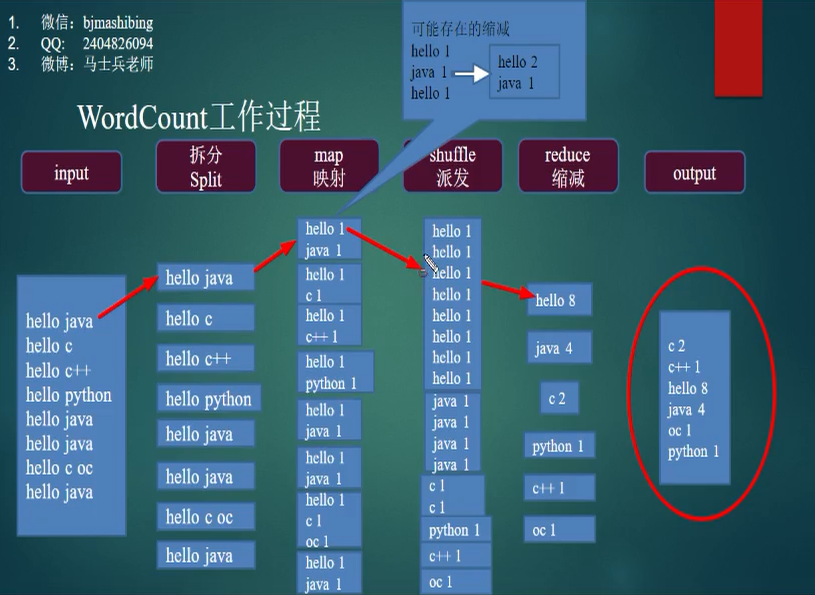
12.比如举个例子,mapreduce可以做日志的离线处理,实时处理用storm。
13.什么是灵活,mapreduce不断迭代跑出想要的结果就行了。
14.nn 和 rm可以分开机器,dn 和 nm资源紧张的话也可以不放一起,只不过离的比较近些才行,比如放在同一个机架上。
15.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









