







针对 Smart 2.3-SNAPSHOT 版本
Smart 对技术选型是非常谨慎的,选择的技术一定是业界最牛逼的,对于数据库连接池也不例外。所以,当初经过百般纠结之后,选择了 Apache Commons 的 DBCP。一点不假,它是一个强大的数据库连接池,稳定且高效,很少有人没听说过它。
当然,市面上并非只有 DBCP 这一款优秀的连接池,比较不错的还有国外的 C3P0,以及国内的 Druid(由阿里巴巴开源)。
目前,Smart 选择的是 DBCP 连接池,而且强耦合在框架中了,若要更换成其它连接池,则必须更改源代码,这严重违反了 开闭原则,所以,非常有必要对这部分代码进行重构。
我的想法是这样的:
让 DBCP 作为 Smart 的默认连接池,当开发者需要使用其它连接池时,只需开发一个 Plugin,并实现 Smart 提供的相关接口,通过配置的方式即可覆盖默认的连接池实现。
也就是说,Smart 仅提供一个默认的实现,第三方可以提供其它的实现,但每种实现都基于相同的接口。
我们不妨先看看重构之前的代码:
<!-- lang: java -->
/**
* 封装数据库相关操作
*
* @author huangyong
* @since 1.0
*/
public class DatabaseHelper {
...
public static DataSource getDataSource() {
// 从配置文件中读取 JDBC 配置项
String driver = ConfigHelper.getConfigString("smart.framework.jdbc.driver");
String url = ConfigHelper.getConfigString("smart.framework.jdbc.url");
String username = ConfigHelper.getConfigString("smart.framework.jdbc.username");
String password = ConfigHelper.getConfigString("smart.framework.jdbc.password");
// 创建 DBCP 数据源
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(username);
ds.setPassword(password);
ds.setValidationQuery("select 1 from dual");
return ds;
}
...
}
我们通过 DatabaseHelper 类的 getDataSource 方法即可获取 DataSource 对象。可见,目前确实是基于 DBCP 的实现,要用别的实现,只能修改框架内核代码了。
下面来对这段代码做一个整容手术,让它彻底改变原有的屌丝形象,瞬间变得白富美!
第一步:提供一个接口
通过 工厂模式 来创建 DataSource 对象,这种做法将创建对象的细节隐藏在具体的工厂实现中,手段非常高明,不用这种模式,都会觉得自己不够专业。
<!-- lang: java -->
/**
* 数据源工厂
*
* @author huangyong
* @since 2.3
*/
public interface DataSourceFactory {
/**
* 获取数据源
*/
DataSource getDataSource();
}
以上 DataSourceFactory 接口仅提供一个 getDataSource 方法,就是要用来获取 DataSource 的,其它的事情一律不做,这就是传说中的 单一职责原则。
下面要做的就是如何来实现这个接口了,参考现在基于 DBCP 的代码,这是很容易实现,但要注意的是,我们一定要做得抽象!因为不能与 DBCP 绑死了,那么应该如何来实现呢?
第二步:提供抽象实现
既然要抽象,就要学会“透过现象看本质”的功力。根据重构前的代码,我们不难发现,创建一个 DataSource 对象必须做以下几件事情:
- 从配置文件中读取 JDBC 配置项
- 创建数据源对象
- 设置数据源属性(包括基础属性与高级属性)
所以,我们的抽象实现应该这样写:
<!-- lang: java -->
/**
* 默认数据源工厂
* <br/>
* 基于 Apache Commons DBCP 实现
*
* @author huangyong
* @since 2.3
*/
public abstract class AbstractDataSourceFactory<T extends DataSource> implements DataSourceFactory {
protected final String driver = ConfigHelper.getString("smart.framework.jdbc.driver");
protected final String url = ConfigHelper.getString("smart.framework.jdbc.url");
protected final String username = ConfigHelper.getString("smart.framework.jdbc.username");
protected final String password = ConfigHelper.getString("smart.framework.jdbc.password");
@Override
public final T getDataSource() {
// 创建数据源
T ds = createDataSource();
// 设置基础属性
setDriver(ds, driver);
setUrl(ds, url);
setUsername(ds, username);
setPassword(ds, password);
// 设置高级属性
setAdvancedConfig(ds);
return ds;
}
public abstract T createDataSource();
public abstract void setDriver(T ds, String driver);
public abstract void setUrl(T ds, String url);
public abstract void setUsername(T ds, String username);
public abstract void setPassword(T ds, String password);
public abstract void setAdvancedConfig(T ds);
}
以上提供了一个基于泛型的 AbstractDataSourceFactory,其中实现了 DataSourceFactory 接口的 getDataSource 方法。
注意,此时的返回值是一个泛型,此泛型必须扩展 DataSource,即泛型表示一个实现了 DataSource 接口的类型。除了必须实现的方法以外,还抽出了若干模板方法。这是什么设计模式?当然是 模板方法模式 了,看来该模式真是无处不在啊!大神们一般都会用。
大家知道,抽象类是不能创建对象的,我们必须对这个抽象类进行具体化才行,也就是再写一个实现类,让它去继承这个抽象类,这样才能实例化。不妨先写一个基于 DBCP 的具体实现吧。
第三步:提供默认实现(基于 DBCP 的实现)
既然是针对 DBCP 的具体实现,那么一定要与 DBCP 紧密耦合,代码写起来应该是非常容易的。
<!-- lang: java -->
/**
* 默认数据源工厂
*
* @author huangyong
* @since 2.3
*/
public class DefaultDataSourceFactory extends AbstractDataSourceFactory<BasicDataSource> {
@Override
public BasicDataSource createDataSource() {
return new BasicDataSource();
}
@Override
public void setDriver(BasicDataSource ds, String driver) {
ds.setDriverClassName(driver);
}
@Override
public void setUrl(BasicDataSource ds, String url) {
ds.setUrl(url);
}
@Override
public void setUsername(BasicDataSource ds, String username) {
ds.setUsername(username);
}
@Override
public void setPassword(BasicDataSource ds, String password) {
ds.setPassword(password);
}
@Override
public void setAdvancedConfig(BasicDataSource ds) {
ds.setValidationQuery("select 1 from dual");
}
}
当我们编写 DefaultDataSourceFactory 时,让它继承 AbstractDataSourceFactory,此时必须为指定一个泛型的具体类,也就是这里的 BasicDataSource 了,它是 DBCP 的核心类,它扩展了 DataSource 类,所以,下面重写的方法都是基于 BasicDataSource 的,而我们要做的事情就是对方法进行“填空”!
现在的结构看起来是这样的:
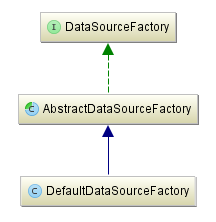
我们只需面向 DataSourceFactory 接口即可获取特定的 DataSource 对象,当然,这取决于 DataSourceFactory 接口选择哪种具体实现了。
与此类似,我们也可以提供基于 C3P0 或 Durid 的 DataSourceFactory 实现。
第四步:提供其它实现
打算通过 Plugin 的方式来提供其它实现,因为要把市面上所有的连接池都用一遍,这是一件不可思议的事情,不妨先使用 C3P0 与 Durid 做一个示例吧,也算是抛砖引玉了。
1. 基于 C3P0 的实现
<!-- lang: java -->
/**
* 基于 C3P0 的数据源工厂
*
* @author huangyong
* @since 2.3
*/
public class C3P0DataSourceFactory extends AbstractDataSourceFactory<ComboPooledDataSource> {
private static final Logger logger = LoggerFactory.getLogger(C3P0DataSourceFactory.class);
@Override
public ComboPooledDataSource createDataSource() {
return new ComboPooledDataSource();
}
@Override
public void setDriver(ComboPooledDataSource ds, String driver) {
try {
ds.setDriverClass(driver);
} catch (PropertyVetoException e) {
logger.error("错误:初始化 JDBC Driver Class 失败!", e);
}
}
@Override
public void setUrl(ComboPooledDataSource ds, String url) {
ds.setJdbcUrl(url);
}
@Override
public void setUsername(ComboPooledDataSource ds, String username) {
ds.setUser(username);
}
@Override
public void setPassword(ComboPooledDataSource ds, String password) {
ds.setPassword(password);
}
@Override
public void setAdvancedConfig(ComboPooledDataSource ds) {
}
}
与 DBCP 类似,C3P0 是使用自己的 ComboPooledDataSource 来创建 DataSource 的。
2. 基于 Durid 的实现
<!-- lang: java -->
/**
* 基于 Durid 的数据源工厂
*
* @author huangyong
* @since 2.3
*/
public class DruidDataSourceFactory extends AbstractDataSourceFactory<DruidDataSource> {
private static final Logger logger = LoggerFactory.getLogger(DruidDataSourceFactory.class);
@Override
public DruidDataSource createDataSource() {
return new DruidDataSource();
}
@Override
public void setDriver(DruidDataSource ds, String driver) {
ds.setDriverClassName(driver);
}
@Override
public void setUrl(DruidDataSource ds, String url) {
ds.setUrl(url);
}
@Override
public void setUsername(DruidDataSource ds, String username) {
ds.setUsername(username);
}
@Override
public void setPassword(DruidDataSource ds, String password) {
ds.setPassword(password);
}
@Override
public void setAdvancedConfig(DruidDataSource ds) {
try {
ds.setFilters("stat");
} catch (SQLException e) {
logger.error("错误:设置 Stat Filter 失败!", e);
}
}
}
使用 Durid 创建 DataSource 也一样,只不过我们可以在 setAdvancedConfig 方法中提供一些高级特性,比如 Durid 的统计功能,可以在浏览器中看到连接池的相关统计数据,这个很赞哦!
想使用 Durid 的统计功能,需要在 web.xml 中配置一个 Servlet,如果不想手工配置的话,完全可以使用 Smart 牛逼的插件机制来完成这件事情,就像下面的代码这样:
<!-- lang: java -->
/**
* 用于注册 Druid 的相关 Servlet
*
* @author huangyong
* @since 2.3
*/
public class DruidPlugin extends WebPlugin {
private static final String DRUID_STAT_URL = "/druid/*";
@Override
public void register(ServletContext servletContext) {
// 添加 StatViewServlet
ServletRegistration.Dynamic druidServlet = servletContext.addServlet("DruidStatView", StatViewServlet.class);
// 从配置文件中获取该 Servlet 的 URL 路径
String druidStatUrl = ConfigHelper.getString("druid.stat.url");
// 若该 URL 路径不存在,则使用默认值
if (StringUtil.isEmpty(druidStatUrl)) {
druidStatUrl = DRUID_STAT_URL;
}
// 向 Servlet 中添加 URL 路径
druidServlet.addMapping(druidStatUrl);
}
}
上面使用了 Servlet 3.0 API 完成 Servlet 的注册,这样一来 web.xml 才是所谓的“零配置”。当发送 /druid/ 请求时就能看到 Druid 提供的统计页面了。
现在的代码结构看起来是不是更加丰满了呢?

既然已经有好几个 DataSourceFactory 的具体实现了,那么如何确保让 Smart 默认使用 DefaultDataSourceFactory,而通过配置的方式就能替换为第三方插件所提供的 DataSourceFactory 实现呢?
最后一步:提供定制特性
实现这个功能并不难,无非就是先从配置文件中读取实现类(类的字符串),然后通过反射去尝试实例化一个对象,若该对象不存在,则使用默认的实现去实例化。
Smart 提供了一个名为“实例工厂”的类 InstanceFactory:
<!-- lang: java -->
/**
* 实例工厂
*
* @author huangyong
* @since 2.3
*/
public class InstanceFactory {
/**
* 用于缓存对应的实例
*/
private static final Map<String, Object> cache = new ConcurrentHashMap<String, Object>();
/**
* ClassScanner
*/
private static final String CLASS_SCANNER = "smart.framework.custom.class_scanner";
/**
* DataSourceFactory
*/
private static final String DS_FACTORY = "smart.framework.custom.ds_factory";
/**
* 获取 ClassScanner
*/
public static ClassScanner getClassScanner() {
return getInstance(CLASS_SCANNER, DefaultClassScanner.class);
}
/**
* 获取 DataSourceFactory
*/
public static DataSourceFactory getDataSourceFactory() {
return getInstance(DS_FACTORY, DefaultDataSourceFactory.class);
}
@SuppressWarnings("unchecked")
public static <T> T getInstance(String cacheKey, Class<T> defaultImplClass) {
// 若缓存中存在对应的实例,则返回该实例
if (cache.containsKey(cacheKey)) {
return (T) cache.get(cacheKey);
}
// 从配置文件中获取相应的接口实现类配置
String implClassName = ConfigHelper.getString(cacheKey);
// 若实现类配置不存在,则使用默认实现类
if (StringUtil.isEmpty(implClassName)) {
implClassName = defaultImplClass.getName();
}
// 通过反射创建该实现类对应的实例
T instance = ObjectUtil.newInstance(implClassName);
// 若该实例不为空,则将其放入缓存
if (instance != null) {
cache.put(cacheKey, instance);
}
// 返回该实例
return instance;
}
}
以上代码不仅对之前提到的 ClassScanner 做了实例化,而且也对现在的 DataSourceFactory 进行了实例化。使用了同一段逻辑完成了这个实例化过程(见 getInstance 方法),此外,还使用了一个基于 Map 的 cache 来缓存已创建的实例,这样下次可直接从 cache 中获取实例,而无需再次实例化了。
这样我们只需在 smart.properties 文件中稍作配置,即可使用第三方实现,同时禁用默认实现。
<!-- lang: java -->
smart.framework.custom.ds_factory=org.smart4j.plugin.druid.DruidDataSourceFactory
此时,DruidDataSourceFactory 生效了,DefaultDataSourceFactory 失效了。
将来这个 InstanceFactory 还会干更多的活,后续我会与大家继续分享。
欢迎下载 Smart 源码:
http://git.oschina.net/huangyong/smart
欢迎阅读 Smart 博文:
http://my.oschina.net/huangyong/blog/158380














 1530
1530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









