






近期拿caffe来做图片分类。遇到不少问题,同一时候也吸取不少教训和获得不少经验。
先看样例再总结经验。
这是一个2类分类器。分的是条纹衣服和纯色衣服。
先看几张图片。
条纹衣服:



纯色衣服:



肉眼也非常easy辨认出来。
训练出来的模型眼下的准确率是0.75。
为了可视化特征抽取。我把某一层的特征图和权重图也画出来了,这层是当中一个全连接层。
条纹衣服的特征图:

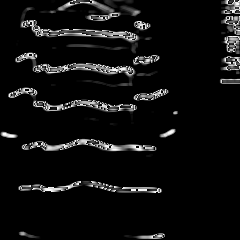

纯色衣服的特征图:



看条纹衣服的特征图比較有意思,把“条纹”特征给抽取出来了。
或许这就是神经网络奇妙的地方,在没有人的干扰的情况下,居然能学习出来“条纹”特征。
当中一个channel的权重图:

这个就看不出来什么了。以前有一个数据集,训练的是裙子的模型。当我看到权重图是一个裙子轮廓的图。
好了。说了这么多。总结一下经验吧。
1 数据集要保证质量。以前玩过一字领和polo领的分类,刚開始效果非常差,后来发现有一些“错误”的标签。于是把那些样本给去掉。效果好了非常多。
2 learning rate要调整。
有一次训练了非常久。准确率差点儿不变,于是我降低了lr,发现好了非常多。
3 均值化图片。实践证明,均值化后再训练收敛速度更快。准确率更高。
对于深度学习的困惑:感觉准确率是个大问题啊,事实上这也是全部机器学习算法的通病。
对于别人研究提供的数据集,比方imagenet,cifa10,lenet,效果非常好。
可是自己收集的数据集,效果就不是非常理想了。
也就是说,算法不是万能的,仅仅是对于某些数据集有效。
我们能做的。是什么?
1 对于哪些数据集。深度学习比較适合?
2 对于效果差的数据集。怎样能提高准确率?
以前脑海里闪过一个念头。是由上面提到的权重图想到的。
当时看到权重图是一个裙子轮廓的图,心里就想。
这是神经网络自己主动调整出来的权重图,
假设人为加上干预,是否能实现优化呢?
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/31773811
















 3890
3890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









