







一、序列化和反序列化的概念
- 把对象转换为字节序列的过程称为对象的序列化。
- 把字节序列恢复为对象的过程称为对象的反序列化。
对象序列化之后得到的字节序列,主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
1.在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
2.当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
二、JDK类库中的序列化API
- java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
- java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以采用默认的序列化方式 。
对象序列化包括如下步骤:
1) 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2) 通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2) 通过对象输入流的readObject()方法读取对象。
对象序列化和反序列范例:
定义一个Person类,实现Serializable接口
public class Person implements Serializable {
private static final long serialVersionUID = -5809782578272943999L;
private int age;
private String name;
private String sex;
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getSex() {
return sex;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public void setSex(String sex) {
this.sex = sex;
}
}序列化和反序列化Person类对象:
package com.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.text.MessageFormat;
public class TestObjSerializeAndDeserialize {
public static void main(String[] args) throws Exception {
SerializePerson();//序列化Person对象
Person p = DeserializePerson();//反序列Perons对象
System.out.println(MessageFormat.format("name={0},age={1},sex={2}", p.getName(), p.getAge(), p.getSex()));
}
private static void SerializePerson() throws FileNotFoundException, IOException {
Person person = new Person();
person.setName("gacl");
person.setAge(25);
person.setSex("男");
// ObjectOutputStream 对象输出流,将Person对象存储到E盘的Person.txt文件中,完成对Person对象的序列化操作
ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(new File("E:/Person.txt")));
oo.writeObject(person);
System.out.println("Person对象序列化成功!");
oo.close();
}
private static Person DeserializePerson() throws Exception, IOException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("E:/Person.txt")));
Person person = (Person) ois.readObject();
System.out.println("Person对象反序列化成功!");
return person;
}
}代码运行结果如下:
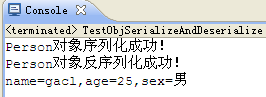

序列化Person成功后在E盘生成了一个Person.txt文件,而反序列化Person是读取E盘的Person.txt后生成了一个Person对象
三、serialVersionUID的作用
serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:
private static final long serialVersionUID
实现Serializable接口的类如果类中没有添加serialVersionUID,那么就会出现如下的警告提示
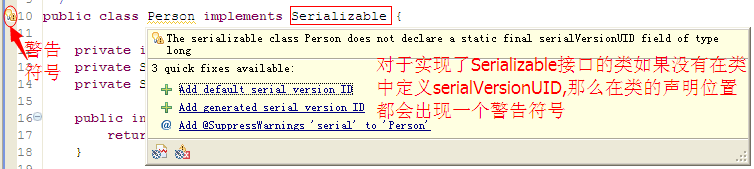
用鼠标点击![]() 就会弹出生成serialVersionUID的对话框,如下图所示:
就会弹出生成serialVersionUID的对话框,如下图所示:
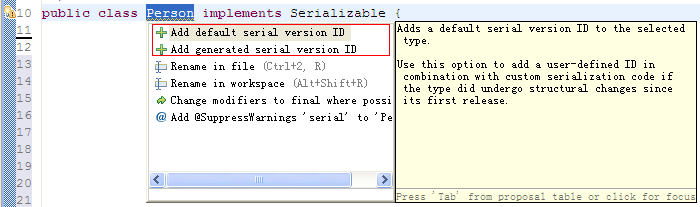
serialVersionUID有两种生成方式:
采用![]() 这种方式生成的serialVersionUID是1L,例如:
这种方式生成的serialVersionUID是1L,例如:
private static final long serialVersionUID = 1L;
采用![]() 这种方式生成的serialVersionUID是根据类名,接口名,方法和属性等来生成的,例如:
这种方式生成的serialVersionUID是根据类名,接口名,方法和属性等来生成的,例如:
private static final long serialVersionUID = 4603642343377807741L;
添加了之后就不会出现那个警告提示了,如下所示:

那么serialVersionUID(序列化版本号)到底有什么用呢,我们用如下的例子来说明一下serialVersionUID的作用,看下面的代码:
package com.io;
import java.io.Serializable;
public class Customer implements Serializable {
//不添加serialVersionUID
private String name;
private int age;
public Customer(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}
package com.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class TestSerialversionUID {
public static void main(String[] args) throws Exception {
SerializeCustomer();// 序列化Customer对象
Customer customer = DeserializeCustomer();// 反序列Customer对象
System.out.println(customer);
}
private static void SerializeCustomer() throws FileNotFoundException, IOException {
Customer customer = new Customer("gacl", 25);
// ObjectOutputStream 对象输出流
ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(new File("E:/Customer.txt")));
oo.writeObject(customer);
System.out.println("Customer对象序列化成功!");
oo.close();
}
private static Customer DeserializeCustomer() throws Exception, IOException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("E:/Customer.txt")));
Customer customer = (Customer) ois.readObject();
System.out.println("Customer对象反序列化成功!");
return customer;
}
}运行结果:
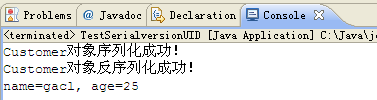
此时,序列化和反序列化也能成功。
下面我们修改一下Customer类,添加多一个sex属性,如下:
package com.io;
import java.io.Serializable;
public class Customer implements Serializable {
//不添加serialVersionUID
private String name;
private int age;
//新添加的sex属性
private String sex;
public Customer(String name, int age) {
this.name = name;
this.age = age;
}
public Customer(String name, int age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}然后执行反序列操作,此时就会抛出如下的异常信息:
Exception in thread "main" java.io.InvalidClassException: Customer; local class incompatible: stream classdesc serialVersionUID = -88175599799432325, local class serialVersionUID = -5182532647273106745
文件流中的class 和classpath中的 class,也就是修改过后的class 不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。
没有指定Customer类的serialVersionUID的,那么java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件多一个空格,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,添加了一个字段后,由于没有显指定 serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。
那么如果有需求要在序列化后添加一个字段或者方法呢?此时就应当自己去指定serialVersionUID。此时就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
下面继续修改Customer类,给Customer指定一个serialVersionUID,修改后的代码如下:
package com.io;
import java.io.Serializable;
public class Customer implements Serializable {
private static final long serialVersionUID = -5182532647273106745L;
private String name;
private int age;
public Customer(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}重新执行序列化操作,将Customer对象序列化到本地硬盘的Customer.txt文件存储。
然后修改Customer类,添加sex属性,修改后的Customer类代码如下:
package com.io;
import java.io.Serializable;
public class Customer implements Serializable {
private static final long serialVersionUID = -5182532647273106745L;
private String name;
private int age;
//新添加的sex属性
private String sex;
public Customer(String name, int age) {
this.name = name;
this.age = age;
}
public Customer(String name, int age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}}执行反序列操作,这次就可以反序列成功了,如下所示:
![]()
四、serialVersionUID的取值
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的 serialVersionUID,也有可能相同。
为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
显式地定义serialVersionUID有两种用途:
1、 在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID。此时,serialVersionUID 一般取值为 1L。
2、 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。此时,每次修改类的成员属性都需要修改serialVersionUID值。
五、对象序列化技术比较
java提供了序列化接口,只要实现了Serializable接口,就可将java对象序列化成字节,以流的形式传输,然后在远端再反序列化成对象,这就达到了传输消息的目的。
但是这种序列化存在一些缺陷:
1.不能跨语言
2.序列化体积大
为了支持跨语言,并提高序列效率,减少传输时的码流大小,好多公司或者大神开发了各种序列化库,hession,protostuff,kryo,jackson,xml等。
json也可以算是一种序列化方式。严格来说并不是一种序列化,它只是一种通用的信息描述方式,一组json信息,可能对应不同的对象模式。由于可以将一组 json 转换成 java bean 对象,也可以转换成map,形式具有不确定性。所以一般的远程调用不会采用json来作为序列化实现.
| 序列类型 | 是否跨语言 | 优缺点 |
| hession | 支持 | 跨语言,序列化后体积小,速度较快 |
| protostuff | 支持 | 跨语言,序列化后体积小,速度快,但是需要Schema,可以动态生成 |
| jackson | 支持 | 跨语言,序列化后体积小,速度较快,且具有不确定性 |
| fastjson | 支持 | 跨语言支持较困难,序列化后体积小,速度较快,只支持java,c# |
| kryo | 支持 | 跨语言支持较困难,序列化后体积小,速度较快 |
| fst | 不支持 | 跨语言支持较困难,序列化后体积小,速度较快,兼容jdk |
各个序列化库比较
0.准备依赖
<!-- protostuff -->
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.0.8</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.0.8</version>
</dependency>
<!-- objenesis(support protostuff,可以使用无参构造方法) -->
<dependency>
<groupId>org.objenesis</groupId>
<artifactId>objenesis</artifactId>
<version>2.1</version>
</dependency>
<!-- hessian -->
<dependency>
<groupId>com.caucho</groupId>
<artifactId>hessian</artifactId>
<version>4.0.38</version>
</dependency>
<!-- jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.0</version>
</dependency>
<!-- fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<!-- kryo -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.0</version>
</dependency>
<!-- fst -->
<dependency>
<groupId>de.ruedigermoeller</groupId>
<artifactId>fst</artifactId>
<version>2.57</version>
</dependency>
1.编写序列化接口
public interface Serializer {
<T> byte[] serialize(T obj);
<T> Object deserialize(byte[] bytes, Class<T> clazz);
}
2.实现接口
hession实现
public class HessianSerializer implements Serializer {
@Override
public <T> byte[] serialize(T obj){
ByteArrayOutputStream os = new ByteArrayOutputStream();
HessianOutput ho = new HessianOutput(os);
try {
ho.writeObject(obj);
} catch (IOException e) {
throw new IllegalStateException(e.getMessage(), e);
}
return os.toByteArray();
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
ByteArrayInputStream is = new ByteArrayInputStream(bytes);
HessianInput hi = new HessianInput(is);
try {
return hi.readObject();
} catch (IOException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}jackson实现
public class JacksonSerializer implements Serializer {
private final static ObjectMapper objectMapper = new ObjectMapper();
@Override
public <T> byte[] serialize(T obj) {
try {
return objectMapper.writeValueAsBytes(obj);
} catch (JsonProcessingException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
try {
return objectMapper.readValue(bytes, clazz);
} catch (JsonParseException e) {
throw new IllegalStateException(e.getMessage(), e);
} catch (JsonMappingException e) {
throw new IllegalStateException(e.getMessage(), e);
} catch (IOException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}fastjson实现
import com.alibaba.fastjson.JSON;
public class FastJsonSerializer implements Serializer {
@Override
public <T> byte[] serialize(T obj) {
try {
return JSON.toJSONBytes(obj);
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
try {
return JSON.parseObject(bytes, clazz);
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}prostfuff实现
public class ProtostuffSerializer implements Serializer {
private static Objenesis objenesis = new ObjenesisStd(true);
private static Map<Class<?>, Schema<?>> cachedSchema = new ConcurrentHashMap<Class<?>, Schema<?>>();
private static <T> Schema<T> getSchema(Class<T> cls) {
@SuppressWarnings("unchecked")
Schema<T> schema = (Schema<T>) cachedSchema.get(cls);
if (schema == null) {
schema = RuntimeSchema.createFrom(cls);
if (schema != null) {
cachedSchema.put(cls, schema);
}
}
return schema;
}
@Override
public <T> byte[] serialize(T obj) {
@SuppressWarnings("unchecked")
Class<T> cls = (Class<T>) obj.getClass();
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
try {
Schema<T> schema = getSchema(cls);
return ProtostuffIOUtil.toByteArray(obj, schema, buffer);
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
} finally {
buffer.clear();
}
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
try {
T message = (T) objenesis.newInstance(clazz);
Schema<T> schema = getSchema(clazz);
ProtostuffIOUtil.mergeFrom(bytes, message, schema);
return message;
} catch (Exception e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
}kryo实现
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import com.esotericsoftware.kryo.pool.KryoFactory;
import com.esotericsoftware.kryo.pool.KryoPool;
public class KryoSerializer implements Serializer {
/**
* kryo 不是线程安全的,所以使用池控制
*/
private static final KryoPool kryoPool = new KryoPool.Builder(
new KryoFactory() {
public Kryo create() {
Kryo kryo = new Kryo();
return kryo;
}
}).build();
@Override
public <T> byte[] serialize(T obj) throws Exception {
try (
Output output = new Output(new ByteArrayOutputStream())) {
Kryo kryo = kryoPool.borrow();
kryo.writeObject(output, obj);
kryoPool.release(kryo);
output.flush();
return ((ByteArrayOutputStream) output.getOutputStream()).toByteArray();
}
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz)
throws Exception {
try (Input input = new Input(new ByteArrayInputStream(bytes))) {
Kryo kryo = kryoPool.borrow();
T res = kryo.readObject(input, clazz);
kryoPool.release(kryo);
return res;
}
}
}jdk实现
public class JdkSerializer implements Serializer {
@Override
public <T> byte[] serialize(T obj) {
try {
ByteArrayOutputStream byteArr = new ByteArrayOutputStream();
ObjectOutputStream out=new ObjectOutputStream(byteArr);
out.writeObject(obj);
out.flush();
return byteArr.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
try {
ObjectInputStream input=new ObjectInputStream(new ByteArrayInputStream(bytes));
return input.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}fst实现
import org.nustaq.serialization.FSTConfiguration;
public class FstSerializer implements Serializer {
private static final FSTConfiguration configuration = FSTConfiguration
.createStructConfiguration();
@Override
public <T> byte[] serialize(T obj) {
return configuration.asByteArray(obj);
}
@Override
public <T> Object deserialize(byte[] bytes, Class<T> clazz) {
return configuration.asObject(bytes);
}
}
3.准备序列对象
hession需要实现Serializable 和 有默认的无参构造方法;
jackson需要实现Serializable
jdk实现 需要实现Serializable
public class User implements Serializable{
private String name;
private String address;
private Integer age;
public User() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public User(String name, String address, Integer age) {
super();
this.name = name;
this.address = address;
this.age = age;
}
}
4.序列化速度比较
public class SerTest {
public static void main(String[] args) {
int len=10;
test(new HessianSerializer(), "hession",len);
test(new JacksonSerializer(), "jackson",len);
test(new ProtostuffSerializer(), "protostu",len);
test(new JdkSerializer(),"jdk",len);
test(new KryoSerializer(),"kryo",len);
test(new FstSerializer(),"fst",len);
test(new FastJsonSerializer(),"fastjson",len);
}
public static void test(Serializer s,String tag,int len){
long cap=0;
long sumTime=0;
for(int i=0;i<len;i++){
User u=new User("taoyuan"+i, i+"addr", i);
long start=System.currentTimeMillis();
byte[] serialize = s.serialize(u);
cap+=serialize.length;
s.deserialize(serialize, User.class);
long cal= System.currentTimeMillis()-start;
sumTime+=cal;
}
System.out.println(tag+"-->["+len+"]对象序列总体积大小:"+cap);
System.out.println(tag+"->["+len+"]对象总消耗时间为:"+sumTime);
}
}结果:
hession–>[100]对象序列总体积大小:7780
hession->[100]对象总消耗时间为:197
jackson–>[100]对象序列总体积大小:4770
jackson->[100]对象总消耗时间为:122
protostu–>[100]对象序列总体积大小:2080
protostu->[100]对象总消耗时间为:102
jdk–>[100]对象序列总体积大小:21380
jdk->[100]对象总消耗时间为:122
kryo–>[100]对象序列总体积大小:2016
kryo->[100]对象总消耗时间为:47
fst–>[100]对象序列总体积大小:4880
fst->[100]对象总消耗时间为:35
fastjson–>[100]对象序列总体积大小:4770
fastjson->[100]对象总消耗时间为:206
5.结论
从以上结果来看,序列化综合性能比较好的是protostuff和kryo,
jdk的序列化速度比较快,就是序列体积较大.
所以当我们的需要开发一套rpc服务时,可以采用kryo来序列化对象,提高传输效率
6. rpc服务实现原理
rpc简单来说就是序列化+传输协议+调用实现+服务管理。
- 序列化是基础,也决定了rpc是否支持跨语言。
- 传输协议可以选择tcp,http,udp等协议,
- 调用实现即rpc服务的业务实现,
- 服务管理即是在以上基础之上的优化管理层次,负载均衡,调用追踪等。















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









