







最近公司发生了一些暴力破解密码的事件,很多用户的账号因此被盗。后来给所有登录入口都加上了验证码,但是仍然偶尔会出现了某些IP频繁登录的情况。是不是验证码被攻破了?本着相信科学的态度,因为以前也学过模式识别方面的东西,不妨从验证码识别技术开始来分析这些可能性。
起源
验证码英文叫CAPTCHA,全称是"Completely Automated Public Turing test to tell Computers and Humans Apart"。图灵测试(Turing test)是计算机科学的祖师爷阿兰.图灵提出来的,也是人工智能领域最著名的实验,意思就是:给你一个人A,一台计算机B,然后把另一个人(考官)放在另一个房间里,考官出题,然后通过A和B的回答,判断谁是计算机。如果考官分不出来哪个是计算机,B就算是通过了图灵测试,也就意味着拥有了真正意义的智能了。这是人工智能的终极目标,目前没有计算机通过呢。所以CAPTCHA的意思呢就是说,它是一种自动化的区别人和计算机的图灵测试。
CAPTCHA出现的意义是划时代的,它是目前防范各种机器人最有效的解决方案。但是就像人工智能界总是在不断发展,挑战图灵测试一样,验证码也受到一些模式识别技术的挑战。2008年的时候,yahoo发明的EZ-Gimpy宣布被破解,达到92%的破解率。同期的微软、google等公司的验证码破解率也达到20%~40%不等。那么不同的验证码为什么安全程度会有差异呢?差异到底在哪里?先从验证码识别的技术说起。
 图1:EZ-Gimpy
图1:EZ-Gimpy
验证码识别
目前大部分验证码都是文字的序列,因此现有的识别方法,大都来自OCR(光学字符识别)的技术。 OCR用于印刷体扫描后文字的识别,一般分为三个步骤:
1、预处理
因为有些印刷文字会存在字迹不清、污点、颜色不统一等问题,所以在最开始都要对图像进行预处理。这些处理包括边缘检测、二值化等操作。边缘检测就是根据颜色和图形的特征,检测出一个文字的边缘,这样就可以得到文字的轮廓。而二值化就是将图片变成黑白的,有些验证码将背景和文字变为不同颜色,实际上在这一步会被识别出来。如果验证码的设计要增加预处理的难度,就需要增加更大的噪点、使用色彩渐变等方式使文字更加难以分辨,但是这样做也同时增加了人识别的难度。而这部分来说,计算机和人的识别能力差不多,甚至要优于人的识别力。所以在这方面做的工作效果并不好。
2、字符分割
我们人类阅读经常说“一目十行”,但是计算机识别大段的文字,却只能按照一个一个文字进行识别。字符分割就是将文字拆分成一个个的字符,以便于单独进行识别的过程。为什么要这么做呢?这要从OCR的核心:图像识别技术说起。
图像识别 的基本原理都是一样的:给计算机一个图像集合A,告诉计算机这些图像分别对应的含义,等它“学懂”后,然后再让它去判断新的图像b,跟集合A中的哪个图像(或者哪类图像)更相似,再借此判断它的含义。这个过程又有个很形象的名字叫“机器学习”。在机器学习的术语里,集合A称为“训练集(training set)”,A的含义叫做“标记(label)”,学习的过程叫做“训练(training)”,推断A的含义的过程叫做“分类(classify)”或者“标注(labeling)”,而把图像转化成计算机能理解的过程叫做“特征提取(feature extract)”。
这个过程有个很大的问题,在于训练集的规模。 计算机的存储能力是很强的,推理能力却是很弱的,给它一个"abcd"组合的图片,告诉它"这是abcd",如果算法足够强大,它以后能够识别出所有"abcd"组合的图片,但是它绝无可能识别出一个"acbd"组合的图片。这种情况下,如果要识别“acbd”,那么必须再设计一套"acbd"组合的图片。如果是6位的验证码,每位由大小写和数字组成,那么一共有(26*2+10)^62=56,800,235,584种可能,就需要设计这么多种图片让计算机去学习。这显然是难以实现的。还有一种做法是将图片拆开,拆成一个个小区域,一次只识别一个字母,这样每个区域需要识别的类型就大大减少。仍以验证码为例,此时仅需要52张图片作为训练即可。
所以,字符分割可以大大降低验证码识别的难度。字符分割方面用到的技术更多,不过在这方面,人却比计算机有较大的优势。目前一种较安全的验证码设计方式就是直接在所有字母中加一条横线,对人类阅读几乎无影响,对计算机切分就比较困难了。还有一种做法是将所有字母变化并重合在一起,这样也能起到难以分割的效果。
 横线分割的验证码
横线分割的验证码
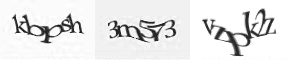 扭曲的验证码
扭曲的验证码
3、字符识别
字符识别使用的就是上面说到的图像识别方法。只要切分成功,那么图像识别的任务就是识别一个区域的图像对应的字母。很多验证码技术都对字母进行了变形,最常见的就是扭曲。但是破解者同样可以将扭曲后的文字作为训练集交给计算机。假设一种文字有100种扭曲方法,那么实际上也只有6200种情况需要计算机来判断,这实在是小菜一碟。
怎样设计一个安全的验证码
这里有一个项目PWNtcha对目前的一些验证码实现进行了分析和破解http://caca.zoy.org/wiki/PWNtcha 。目前主流的验证码,都是基于字符重合和扭曲来实现的。同时,好的验证码必须保证输出的多样性,输出的变化越多越好。
国内各大网站的验证码
![]() 新浪
新浪
 QQ空间
QQ空间
![]() 豆瓣
豆瓣
![]() 人人网
人人网
一些新的思路
使用单词 目前有一些网站使用词语来作为验证码,这样对于用户来说,即使某个字母不认识也可以根据已有语言知识拼写出来,对于用户体验来说是很有帮助的。初到大众点评时,看到这个词组的验证码,不免有点眼前一亮的感觉。但是这种方式,必须有一个足够大的词库,否则,即使不采用图像识别,仅仅使用暴力破解的方法,仍然能达到一定成功率(理论上成功率达到1%的验证码就不能使用了)。其次,可以使用隐式马尔科夫模型等利用前后字母的信息,增加识别成功率。(隐式马尔科夫模型也是一种模式识别的工具,它根据前面某几个词语来预测后面的内容,在语音识别领域有广泛应用。这个不属于本文内容,就不细说了)
![]() 豆瓣
豆瓣
使用汉字 汉字验证码是个很有趣的尝试,因为汉字数量众多,以GB2312为例,一共有3755个常用汉字,加上变换的情况,基本上是一个很庞大的数字。同时国内破解验证码的研究基本停留在照抄国外技术的阶段,国外没有汉字验证码的研究啊,所以使用汉字还是比较让人放心的。目前点评使用的汉字验证码,但是词库比较小,还是有一点风险的。使用汉字验证码可能有个缺点就是:汉字本身的多样性可能给用户识别带来的困难,需要细心挑选汉字字库。不过目前没有发现这方面更多的使用,也难以评价。
 点评团购
点评团购
使用问答 有些网站的验证码是出一道题目让人填答案什么的,乍一看,计算机必定不具备思考能力,肯定识别不出来。但是别忘了,计算机没有思考能力,必然也不会有出题能力,就那么几道题目,只能人工制定,反而给破解者带来便利。所以这种技术非常难以使用,必须制定大量题库并且随时更新。有些网站注册设置了这种验证码,但是就博主看来其实只是为了考验人类的智商而已,计算机可是会“背答案”的!
 小木虫
小木虫
使用图片交互 下图是个很有趣的尝试,要求读图片之后回答问题,这么做很多图片识别技术就无能为力了。不过还是那句话,题库需要足够大,题目足够随机,防止计算机“背答案”。国内某些“验证码广告”,其实题库就那么几个,完全只是广告而已。 http://www.picatcha.com/
http://www.picatcha.com/
reCaptcha 最后提到一个有趣的项目,google的reCAPTCHA。这个验证码的特点是:它由两个单词组成,一个单词A是计算机知道答案的,而另外一个B是从古籍里面扫描出来,机器难以识别的。它通过A是否验证正确,来判断B的结果的有效性,并将多个有效结果结合起来,组成一个正确结果。基本上这系列的验证码以“难以识别”著称。当然这是指计算机难以识别,但是就我目前测试来看,人类识别也好不到哪去...
















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









