






面向对象的程序设计(2019)第一单元总结
I 对问题的初体验
在开土动工之前,确定第一单元的作业和多项式的处理有关。解决方案需要包括输入-处理-输出三个部分。对于输入部分,我不希望使用类似编译的递归下降分析方法处理,这样若出现错误会较为分散,所以选取正则表达式匹配的方式提取其中的关键元素。在处理部分,确定求导之前之后的表达式可以使用同样的数据结构存储,所以只需要合理维护一个在特定数据结构上进行求导运算的工具即可。对于输出而言,每一项的简化方式固定,可以在自动测试时遍历所有分支保证正确性,也可以在后几次作业中延续先前的输出模式。
II 三次的设计思路
A 仅包含常数和幂函数的多项式求导
由于多项式具有极强的规律,因而采取正则表达式的方式进行处理。处理思路是首先使用正则表达式判断输入串的合法性,在合法的基础上,进行替换使得输入字符串易于同一格式化处理。
识别包含空格和制表符的正则表达式:


^[ \t]*[-+]?[ \t]*([ \t]*[-+]?[0-9]+[ \t]*\*[ \t]*x[ \t]*(\^[ \t]*[+-]?[0-9]+)?|[ \t]*[-+]?[ \t]*x([ \t]*\^[ \t]*[+-]?[0-9]+)?|[ \t]*[-+]?[0-9]+)([ \t]*[-+][ \t]*([-+]?[0-9]+[ \t]*\*[ \t]*x([ \t]*\^[ \t]*[+-]?[0-9]+)?|[-+]?[ \t]*x([ \t]*\^[ \t]*[+-]?[0-9]+)?|[-+]?[0-9]+))*[ \t]*$
在正确匹配正则表达式之后,为了后续的统一化处理,进行批量的替换。在第一次作业中,首先去除无用的空格和制表符,之后批量替换掉连续存在的符号为一个统一的符号,最后对前缀为1/-1的省略情况进行补充。经过处理的输入串可以被如下正则表达式提取项:
([-+]?[0-9]+)\*x\^([+-]?[0-9]+)|([-+]?[0-9]+)\*x|([-+]?[0-9]+)
通过匹配的Group可以判断具体的情况并处理。
为了能够处理大于普通数字的长整数,引入 BigInteger 类进行处理。表达式的数据结构方面,由于目前仅存在带有常数的幂函数项(常数可以看做幂为0的特殊情况),所以设计时采用HashMap进行存储,定义为: private Map<BigInteger, BigInteger> valuePair = new HashMap<>(); ,其中 valuePair.key 代表项的幂指数, valuePair.value 代表项的系数。这样的实现可以在处理过程中合并指数相同的项,便于处理。
在数据结构建立起来之后,求导仅仅是遍历一次并对应处理的过程。
优化 由于在处理过程中已经将同类项合并,所以可行的优化就是省略系数为0的项,令系数+1/-1为+/-,幂指数为1或0时进行省略。除此之外还可以将正项提前到首位以省略一个符号。
B 包含常数、幂函数与简单三角幂函数多项式的求导
由于这次作业还时没有出现嵌套型的结构,因而还是可以通过正则表达式进行通配再分项处理。和之前作业的区别也只在于项不仅仅可以是 x,还可以是 sin(x)/cos(x)。因为正则表达式的长度增加,加上自己先前表达式的描述过于繁琐,因而对于过长的输入会出现爆栈的情况。为了解决这个问题,可以将 String polyRegex = "..." 修改为 final String polyRegex= "..." 就可以显著的提升程序运行的效率,增加爆栈表达式的长度。当然去除括号和无用字符也会很有效的提高速度。当然只做这些还是不能消除过长表达式的爆栈问题,所以在识别输入时应当按项识别,超出长度则直接返回防止出现问题。
为了完成此次作业,我增加了一个因子类,用来记录所有因子的幂指数。其他处理和第一次作业类似,不再赘述。
优化
因为三角函数的特殊性,会存在可优化的环节。诸如 sin(x)2+cos(x)2=1 或 cos(x)2-sin(x)2=2*cos(x)2-1 这种可以显著缩短长度的优化,可以提高性能分。但是因为情况较为复杂,单单枚举出几种特殊情况可能不足以有效的改善输出情况。因而我采取了暴力搜索的方法。首先提取出x的幂指数相等的项作为一个优化单位,因为不同幂指数的项在三角函数计算过程中不可能会变得更短。对于幂指数相同的元组,取这个元组的计算基准最大值为所有三角幂函数中的最大值,最小值同理,确定对每个幂指数迭代的数据范围,设为[a,b]。每一项sin(x)m*cos(x)n,分别将 sin(x)2 和 cos(x)2 替换为 (1-cos(x)2) 与 (1-sin(x)2) 进行计算并统计长度,保留记录下的长度最短项合并为最终表达式。
为了防止暴力搜索过程中造成的爆栈和超时问题,分别对迭代的深度和迭代进行的时间进行了控制。若搜索时间过长则直接返回当前搜索到的最长串。在编写爆搜迭代的过程中我也对Java传递对象有了更深入的了解。
C 包含常数、项、幂函数与嵌套三角幂函数多项式的求导
当进行到第三次作业的时候,由于表达式的递归嵌套特性,使得正则表达式在匹配括号的过程中遇到了很严重的问题。为了解决这个问题,我的同学提出了通过扫描的方法确定最外层括号,替换括号符号为特殊匹配符号的方法逐层递归下降匹配表达式。这个方案在实行的过程中被认为是最高效的匹配方案。在正确匹配最外层表达式之后,遵循之前的设计模式,会替换特定的内容。但是由于此时内层括号尚未匹配完毕,替换仅可以在最外层进行。为了实现这个操作,对之前替换的部分追加排除正则表达式,形如(使用<与>作为标志符号): String ignoreRegex = "(?=[^>]*(<|$))"; 替换时只要加上条件即可忽略括号内的内容。
为了合理的分配和存储不同层次的数据,我建立了一个抽象语法树用于保存语法成分便于求导。顶层模块主要分为三个类(Expression, Term与Factor),分别表示表达式,项和因子。Expression 内部数据结构为 Set<Term> exp ,表示为项的集合;Term 内部数据包括 BigInteger coeff 与 Term term ,记录项的系数与所有因子;Factor 内部数据包含三种不同的因子, Map<Expression, BigInteger> sinFactor, cosFactor, varFactor 分别代表sin(...),cos(...)与(...)因子的内容和指数。选取对应的数据结构为Set与Map,因为他们容易扩充,通过key的equals()与hashcode()方法进行判断便于去重。
设计过程即按层次递归下降分析。对于识别到的元素保存到对应的结构中。较为特殊的是,当识别到此项中仅包含x作为因子时,应该标记并返回,防止无限递归下降没有终点。
优化
在这次作业中,最基础的操作即为合并同类项。但是因为嵌套层次的原因,合并同类项也需要递归下降的分析。通过重载 Expression,Term 与 Factor 类的 equals() 与hashcode() 方法,可以实现对相同表达式的合并。对于 Expression 类中的集合,我采用较为暴力的方法,判断两个集合中的元素是否互相包含。若互相包含则判断为相等。对于 Term 中的因子,直接使用因子中的判等函数。对于 Factor 而言,分别判断Map中的key和value是否严格包含且相同。这样就实现了相同表达式的合并。
但是在实现之后发现,表达式时常因为层次不同的相同表达式干扰无法合并。举例而言对于 (x+(((x))))+((x)+((x)))一类的表达式就无法合理的合并同类项。分析结构发现,这一类的表达式有两个特征。第一种是存在冗余的 Factor (Outside) -> Expression -> Term (.size() == 1) -> Factor (Inside) 的无用序列。可以通过合并 Factor (Outside) 与 Factor (Inside) 减少括号层次;第二种是存在无用的 Expression -> Term (.size() > 1) (Outside) -> Factor (sinFactor.empty() && cosFactor.empty() && varFactor.size() == 1) -> Term (Inside) 的冗余序列,可以将 Term (Outside) 与 Term (Inside) 合并以减少层次。在进行括号层次化简之后,再进行求导会得到更简短的表达式。
在进行上述优化时,我错误的将x项也提升到外部括号,导致原本在sin(x)中的因子变为sin()*x,产生错误,故化简层次时需要特殊判断一下。
III 解决方案的评估
A 捕获的错误
第一次作业时由于忽略x位于整个符号串开始的情况,忘记替换为+1*x导致出错;由于复杂的正则表达式,导致过长的字符串会出现爆栈问题,通过上述多种方法修复。
第二次作业时由于cos(x)求导过程遗漏负号导致了出错。
第三次作业时正则表达式识别的架构都完全继承下来,导致在第三次的前缀单位符号的统一化处理时忽略了+()/-()替换的情况造成的出错。
B 自动化测试
在编写自动化测试程序时,尝试过使用 Python 的 eval() 方法进行自动化测试,但是会面临数值过大溢出的问题,而且正则表达式在层次过于复杂的情况下速度会显著下降。因为我转而使用 Mathematica 软件包提供的 Wolfram Script 功能运行 Java 程序生成多项式,并输入目标程序测试评估。这样可以利用 Shell Script 批量执行结果。
批量运行脚本:
1 #!/bin/sh 2 while true 3 do 4 target=$(java PATH/TO/Generator) 5 result=$(java PATH/TO/Main '"'"${target}"'"') 6 out=$(./run.wls '"'"${target}"'"' '"'"${result}"'"') 7 if [ "$out" -eq '1' ]; then 8 echo -e "\r[-] Success: $target\c" 9 else 10 echo "[!] Failed: $target with Derivation $result" 11 fi; 12 done
Wolfram Script 代码:
1 #!/usr/bin/env wolframscript 2 3 (* Compare Two Inputs *) 4 source = ToExpression[$ScriptCommandLine[[2]]]; 5 reference = ToString[$ScriptCommandLine[[2]]]; 6 standard = ToExpression[$ScriptCommandLine[[3]]]; 7 8 diff = D[source, x] 9 failed = False; 10 For[x=-10,x<=10,x+=0.1, 11 If[Abs[standard-diff]>0.000001 && !failed, 12 Print["0"];failed = True;]] 13 If[!failed,Print["1"]]
在自动化测试的过程中,我忽略了首先检查结果是否符合规范的步骤,导致最后作业中出现错误。
C 度量评估
因为作业几乎一脉相承,所以分析最后一次作业就可以大致对单元作业给出评估。首先分析 CK 度量组,基于类设计的六种度量:
- 类的有权方法 (WMC)
- 类的继承树深度 (DIT)
- 类的孩子个数 (NOC)
- 对象类之间的耦合 (CBO)
- 类的响应 (RFC)
- 类中方法缺乏内聚的程度 (LCOM)

由于我在实现中较少的使用了类之间的继承等特性,所以基于这个度量的类间特性的数据都较低。
所以我转而对类内部的复杂度进行分析。类内部的复杂度一般分为三种度量:
- 方法或类的结构化复杂度 ev(G)
- 方法或类调用其他方法的紧密程度 iv(G)
- 方法或类的循环复杂度 v(G) - OCavg(平均循环复杂度) - WMC(总循环复杂度)

可以看到,类内部的循环复杂度还是很高的,进一步查看 Tree 内部的方法复杂度:

发现求导过程以及优化的复杂度较高。分析原因,初步假设是因为在合并相同项时需要递归调用 equals() 方法至底部判断相等,对每一项都需要进行判断故复杂度较高。展开 equals() 方法的循环进行检查:

发现的确是由于 equals() 方法导致的复杂度升高,可以考虑进行速度优化。
最后基于 UML 度量工具进行类图的绘制:
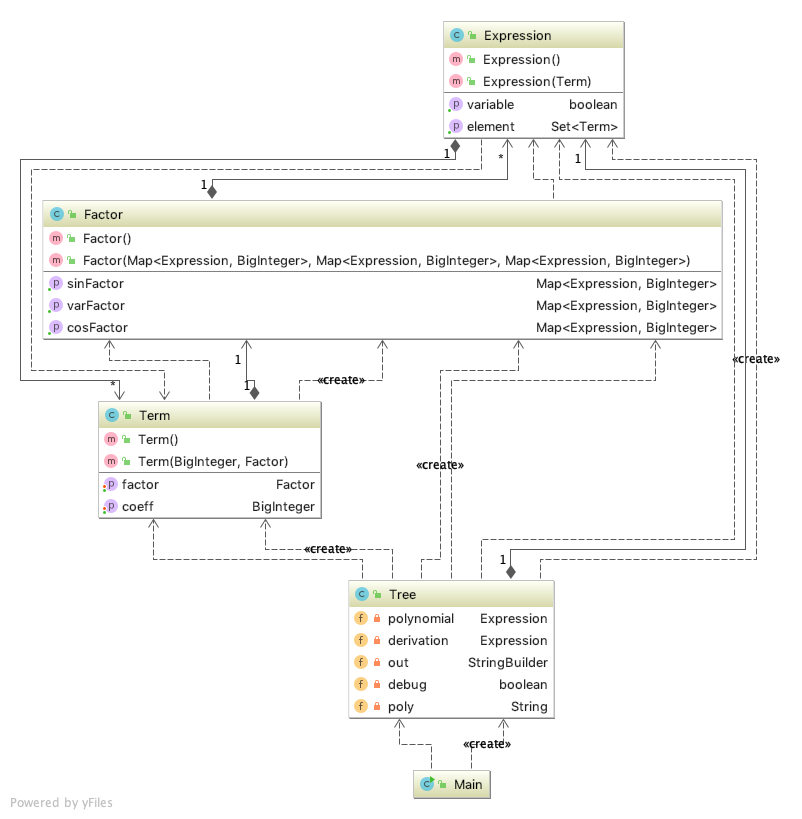
可以看出,类的整体结构是一个递归调用的环。在应用度量手段分析之后,发现自己对创建设计模式不是特别了解。在之后的作业中也会开始尝试使用设计模式简化设计的步骤。
IV 应用设计模式
先前的对于项的实现,我没有使用抽象类来实现一个项的定义,导致 Factor 类中出现三个结构相同的 Map,且对于处理不同类型的项还需要分别判断,这使得我的程序总要写很多重复但有细微区别的代码。应用创建型模式中的工厂方法,定义一个创建对象的接口,让子类决定实例化那个类可以大大简化代码的复杂程度。具体而言,重构的案例为:
1 abstract class Factor { 2 public Factor(){ 3 4 } 5 abstract void derivate(); 6 } 7 8 public class sinFactor extends Factor { 9 public sinFactor() { 10 ... 11 } 12 } 13 14 public class cosFactor extends Factor{ 15 public cosFactor(){ 16 ... 17 } 18 } 19 20 public class varFactor extends Factor{ 21 public varFactor(){ 22 ... 23 } 24 } 25 26 27 public class Factory { 28 public Factor createFactor(int type) { 29 switch (type) { 30 case sin: 31 return new sinFactor(); 32 33 case cos: 34 return new cosFactor(); 35 36 default: 37 return new varFactor(); 38 } 39 return null; 40 } 41 } 42 43 public class Usage { 44 public static void main(String[] args) { 45 Factory factory = new Factory(); 46 Factor cos = factory.createFactor(cos); 47 Factor sin = factory.createFactor(sin); 48 } 49 }
重构后的代码也可以降低复杂度,改善之前遍历 Map 时的速度。
在输出 AST 语法树的过程中,可以采用建造者模式,统一化接口。具体而言重构细节如下:
1 public class Tree{ 2 public void Construct(Builder builder){ 3 builder.check(); 4 builder.build(); 5 } 6 ... 7 } 8 9 public class Builder { 10 public void check(); 11 public void build(); 12 public void print(); 13 } 14 15 public class Builder Pattern{ 16 public static void main(String[] args){ 17 ... 18 Tree tree = new Tree(); 19 Builder builder = new Builder(string); 20 tree.Construct(builder); 21 builder.print(); 22 } 23 }
这样可以将语法树的建立和不同的运算操作分离开,使得模块间的隔离程度更强,鲁棒性更高。
V 总结
此次作业在最初设计时,为了简便快速的完成任务所以省略了很多抽象层的定义。这些所谓的省时在之后的作业发布之后都被迫一一补全。匹配需求的过程中还是没有很好的应用面向对象的设计模式,自己应该在之后的作业中勤加练习。若有遗漏或错误的叙述,还望多多指教!














 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









