







话说爬虫为什么会陷入循环呢?答案很简单,当我们重新去解析一个已经解析过的网页时, 就会陷入无限循环。这意味着我们会重新访问那个网页的所有链接, 然后不久后又会访问到这个网页。最简单的例子就是,网页A包含了网页B的链接, 而网页B又包含了网页A的链接,那它们之间就会形成一个闭环。
那么我们怎样防止访问已经访问过的页面呢,答案也很简单,设置一个标志即可。 整个互联网就是一个图结构,我们通常使用DFS(深度优先搜索)和BFS(广度优先搜索) 进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下
1. 根据 Url 获取相应页面的 Html 代码
2. 利用正则匹配或者 Jsoup 等库解析 Html 代码,提取需要的内容
3. 将获取的内容持久化到数据库中
4. 处理好中文字符的编码问题,可以采用多线程提高效率
爬虫基本原理
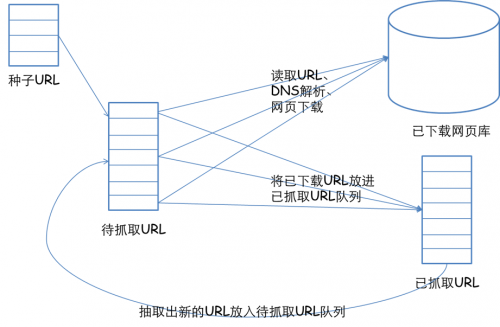
更宽泛意义上的爬虫侧重于如果在大量的 url 中寻找出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析页面里包含的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
来源于 该文章 的一张图
爬虫难点1 环路
网络爬虫有时候会陷入循环或者环路中,比如从页面 A,A 链接到页面 B,B 链接 页面C,页面 C 又会链接到页面 A。这样就陷入到环路中。
环路影响
- 消耗网络带宽,无法获取其他页面
- 对 Web 服务器也是负担,可能击垮该站点,可能阻止正常用户访问该站点
- 即使没有性能影响,但获取大量重复页面也导致数据冗余
解决方案
1. 简单限定爬虫的最大循环次数,对于某 web 站点访问超过一定阈值就跳出,避免无限循环
2. 保存一个已访问 url 列表,记录页面是否被访问过的技术
- 二叉树和散列表,快速判定某个 url 是否访问过
- 存在位图
就是 new int[length],然后把第几个数置为1,表示已经访问过了。可不可以再优化,int 是32位,32位可以表示32个数字。HashCode 会存在冲突的情况,两个 url 映射到同一个存在位上,冲突的后果是某个页面被忽略(这比死循环的恶作用小) - 保存检查
一定要即使把已访问的 url 列表保存在硬盘上,防止爬虫崩溃,内存里的数据会丢失 - 集群 ,分而治之
多台机器一起爬虫,可以根据 url 计算 hashcode,然后根据 hashcode 映射到相应机器的 id (第0台、第1台、第2台等等)
难点2 URL别名
有些 url 名称不一样,但是指向同一个资源。
该表格来自于 《HTTP 权威指南》
| URl 1 | URL 2 | 什么时候是别名 |
|---|---|---|
| www.foo.com/bar.html | www.foo.com:80/bar.html | 默认端口是80 |
| www.foo.com/~fred | www.foo.com/%7Ffred | %7F与~相同 |
| www.foo.com/x.html#top | www.foo.com/x.html#middle | %7F与~相同 |
| https://www.baidu.com/ | https://www.BAIDU.com/ | 服务器是大小写无关 |
| www.foo.com/index.html | www.foo.com | 默认页面为 index.html |
| www.foo.com/index.html | 209.123.123/index.html | ip和域名相同 |
难点3 动态虚拟空间
比如日历程序,它会生成一个指向下一月的链接,真正的用户是不会不停地请求下个月的链接的。但是不了解这内容特性的爬虫蜘蛛可能会不断向这些资源发出无穷的请求。
抓取策略
一般策略是深度优先或者广度优先。有些技术能使得爬虫蜘蛛有更好的表现
- 广度优先的爬行,避免深度优先陷入某个站点的环路中,无法访问其他站点。
- 限制访问次数,限定一段时间内机器人可以从一个 web 站点获取的页面数量
- 内容指纹,根据页面的内容计算出一个校验和,但是动态的内容(日期,评论数目)会阻碍重复检测
- 维护黑名单
- 人工监视,特殊情况发出邮件通知
-
动态变化,根据当前热点新闻等等
-
规划化 url,把一些转义字符、ip 与域名之类的统一
- 限制 url 大小,环路可能会使得 url 长度增加,比如/index.html, /folder/index,html, /folder/folder/index.html …
全文索引
全文索引就是一个数据库,给它一个单词,它可以立刻提供包含那个单词的所有文字。创建了索引之后,就不必对文档自身进行扫描了。
比如 文章 A 包含了 Java、学习、程序员
文章 B 包含了 Java 、Python、面试、招聘
如果搜索 Java,可以知道得到 文章 A 和文章 B,而不必对文章 A、B 全文扫描。



一个复杂的分布式爬虫系统由很多的模块组成,每个模块是一个独立的服务(SOA架构),所有的服务都注册到Zookeeper来统一管理和便于线上扩展。模块之间通过thrift(或是protobuf,或是soup,或是json,等)协议来交互和通讯。

Zookeeper负责管理系统中的所有服务,简单的配置信息的同步,同一服务的不同拷贝之间的负载均衡。它还有一个好处是可以实现服务模块的热插拔。
URLManager是爬虫系统的核心。负责URL的重要性排序,分发,调度,任务分配。单个的爬虫完成一批URL的爬取任务之后,会找 URLManager要一批新的URL。一般来说,一个爬取任务中包含几千到一万个URL,这些URL最好是来自不同的host,这样,不会给一个 host在很短一段时间内造成高峰值。
ContentAcceptor负责收集来自爬虫爬到的页面或是其它内容。爬虫一般将爬取的一批页面,比如,一百个页面,压缩打包成一个文件, 发送给ContentAcceptor。ContentAcceptor收到后,解压,存储到分布式文件系统或是分布式数据库,或是直接交给 ContentParser去分析。
CaptchaHandler负责处理爬虫传过来的captcha,通过自动的captcha识别器,或是之前识别过的captcha的缓存,或是通过人工打码服务,等等,识别出正确的码,回传给爬虫,爬虫按照定义好的爬取逻辑去爬取。
RobotsFileHandler负责处理和分析robots.txt文件,然后缓存下来,给ContentParser和 URLManager提供禁止爬取的信息。一个行为端正的爬虫,原则上是应该遵守robots协议。但是,现在大数据公司,为了得到更多的数据,基本上遵 守这个协议的不多。robots文件的爬取,也是通过URLManager作为一种爬取类型让分布式爬虫去爬取的。
ProxyManager负责管理系统用到的所有Proxy,说白了,负责管理可以用来爬取的IP。爬虫询问ProxyManager,得到一 批Proxy IP,然后每次访问的时候,会采用不同的IP。如果遇到IP被屏蔽,即时反馈给ProxyManager,ProxyManager会根据哪个host屏 蔽了哪个IP做实时的聪明的调度。
Administor负责管理整个分布式爬虫系统。管理者通过这个界面来配置系统,启动和停止某个服务,删除错误的结果,了解系统的运行情况,等等。
各种不同类型的爬取任务,比如,像给一个URL爬取一个页面( NormalCrawler),像需要用户名和密码注册然后才能爬取( SessionCrawler ),像爬取时先要输入验证码( CaptchaCrawler ),像需要模拟用户的行为来爬取( Simulator ),像移动页面和内容爬取( MobileCrawler ),和像App内内容的爬取( AppCrawler),需要不同类型的爬虫来爬取。当然,也可以开发一个通用的爬虫,然后根据不同的类型实施不同的策略,但这样一个程序内的代码复杂, 可扩展性和可维护性不强。
一个爬虫内部的爬取逻辑,通过解释从配置文件 CrawlLogic 来的命令来实现,而不是将爬取逻辑硬编码在爬虫程序里面。对于复杂的爬取逻辑,甚至可以通过用代码写的插件来实现。
ContentParser根据URLExtractionRules来抽取需要继续爬取的URL,因为focus的爬虫只需要爬取需要的数 据,不是网站上的每个URL都需要爬取。ContentParser还会根据FieldExtractionRules来抽取感兴趣的数据,然后将原始数 据结构化。由于动态生成的页面很多,很多数据是通过Javascript显示出来的,需要JavascriptEngine来帮助分析页面。这儿需要提及 下,有些页面大量使用AJAX来实时获取和展示数据,那么,需要一个能解释Javascript的爬虫类型来处理这些有AJAX的情形。
为了监控整个系统的运行情况和性能,需要 Monitor 系统。为了调试系统,保障系统安全有据可循,需要 Logger 系统。有了这些,系统才算比较完备。
所有的数据会存在分布式文件系统或是数据库中,这些数据包括URL( URLRepo),Page( PageRepo )和Field( FieldRepo ),至于选择什么样的存储系统,可以根据自己现有的基础设施和熟悉程度而定。
为了扩大爬虫系统的吞吐量,每个服务都可以横向扩展,包括横向复制,或是按URL来分片(sharding)。由于使用了Zookeeper,给某个服务增加一个copy,只用启动这个服务就可以了,剩下的Zookeeper会自动处理。
这里只是给出了复杂分布式爬虫系统的大框架,具体实现的时候,还有很多的细节需要处理,这时,之前做过爬虫系统,踩过坑的经验就很重要了。















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









