







年前在生产环境中后台出现内存使用率过高,CPU使用持续过载的情况。怀疑出现了JVM的内存泄露。于是开始排查版本代码提交。
整个过程花费了一个星期时间,其中用到的命令工具包括:
#查看进程中哪个线程的CPU使用率过高
top -Hp <jvmPid>
#根据上一步查询的PID的十六进制查看堆栈中,发现是GC线程
jstack -l <jvmPid>
#查看fgc次数一直在增加,频繁的进行FGC,很有可能是内存泄露
jstat -gcutil <jvmPid>
#导出堆内存
jmap -dump:format=b,file=heap.bin <jvmPid>
#通过MAT工具分析leak suspect
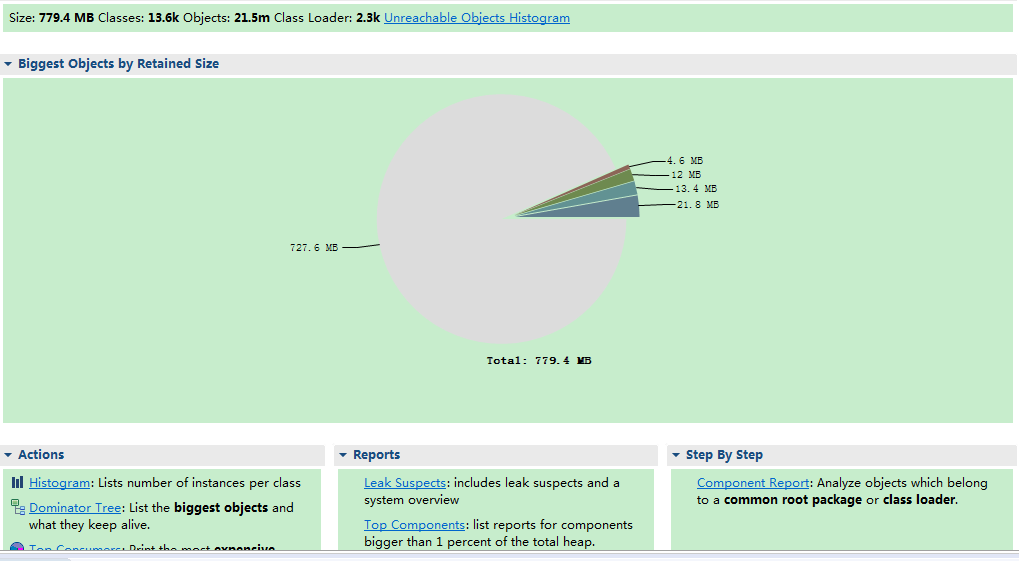
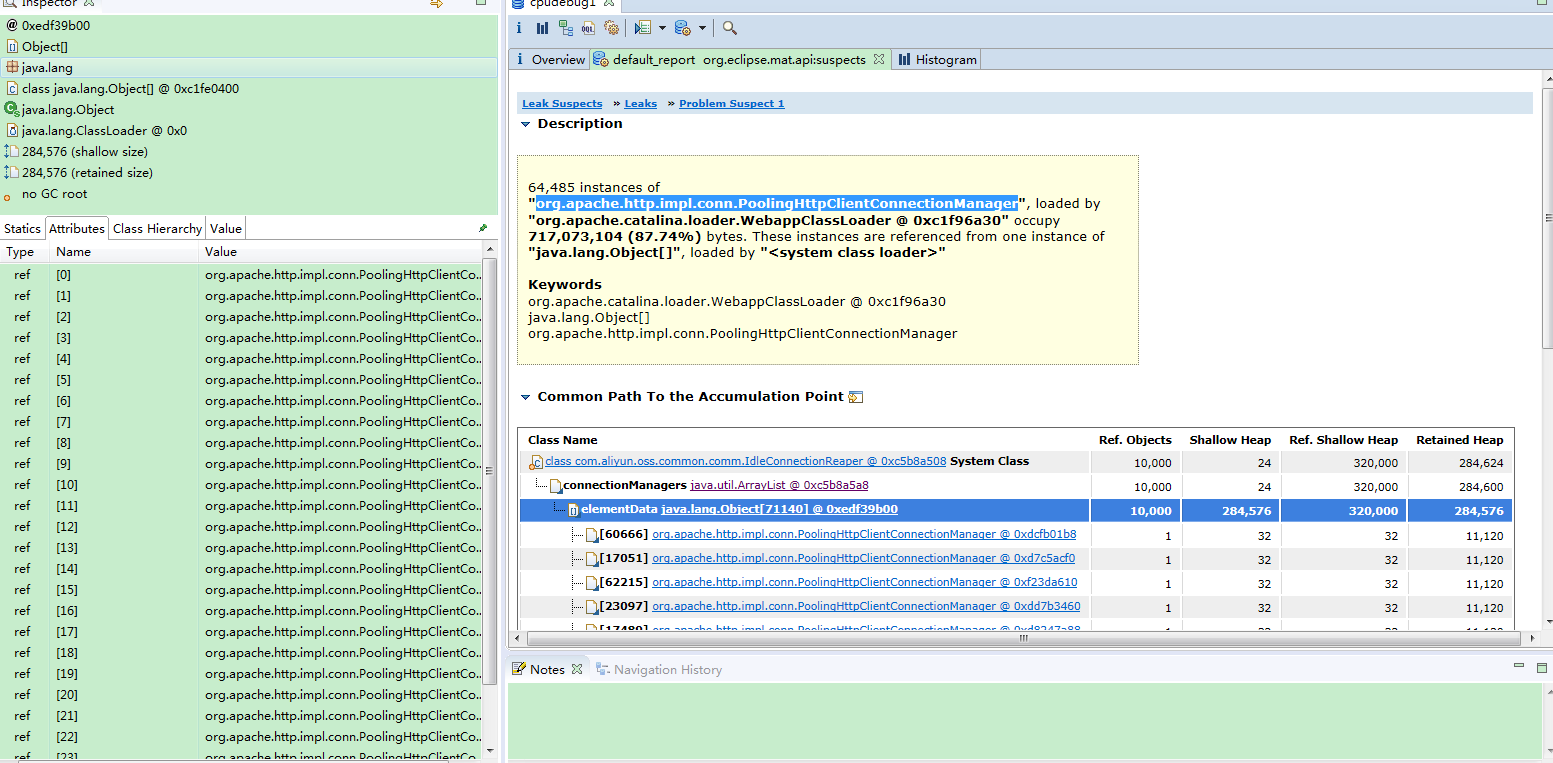
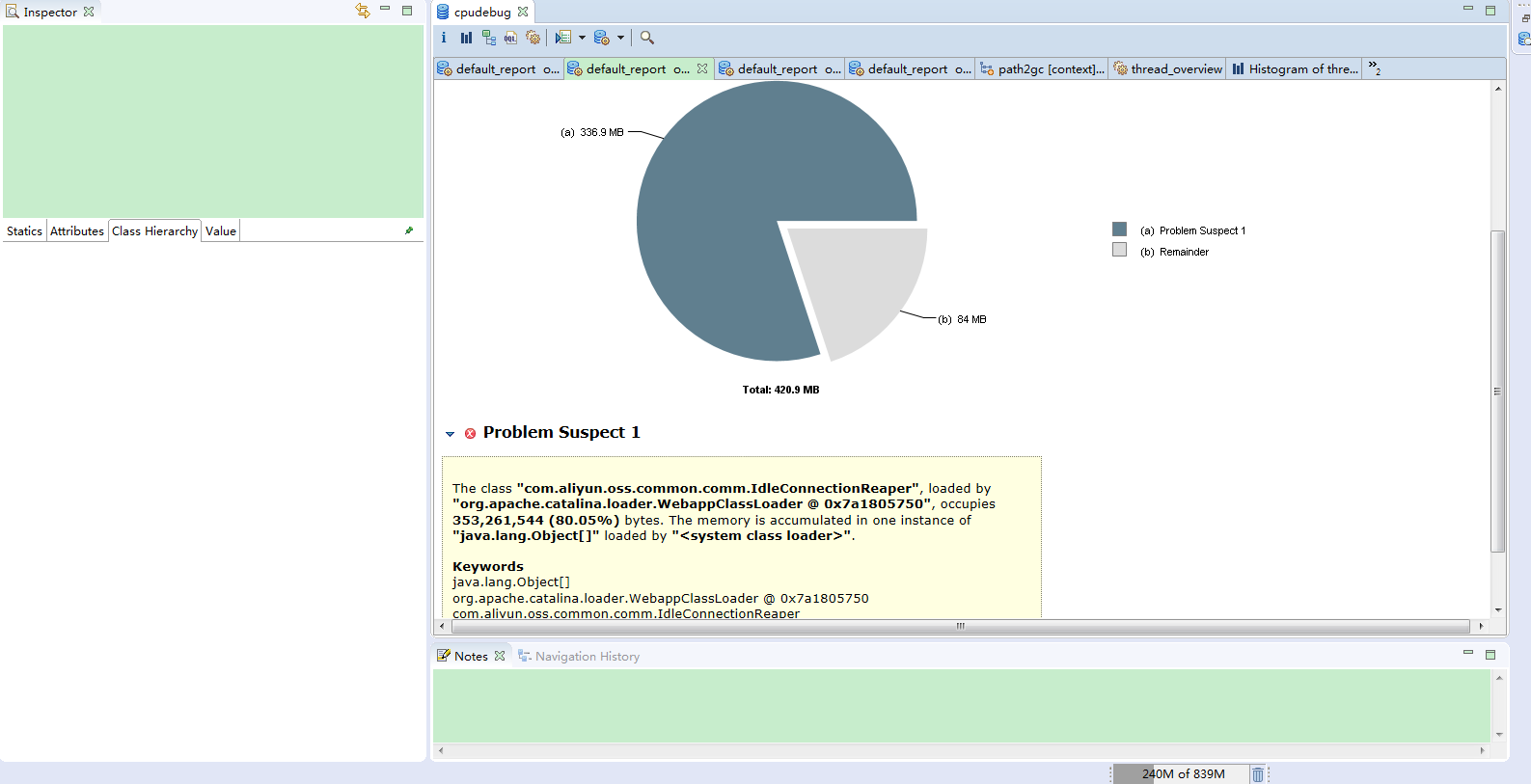
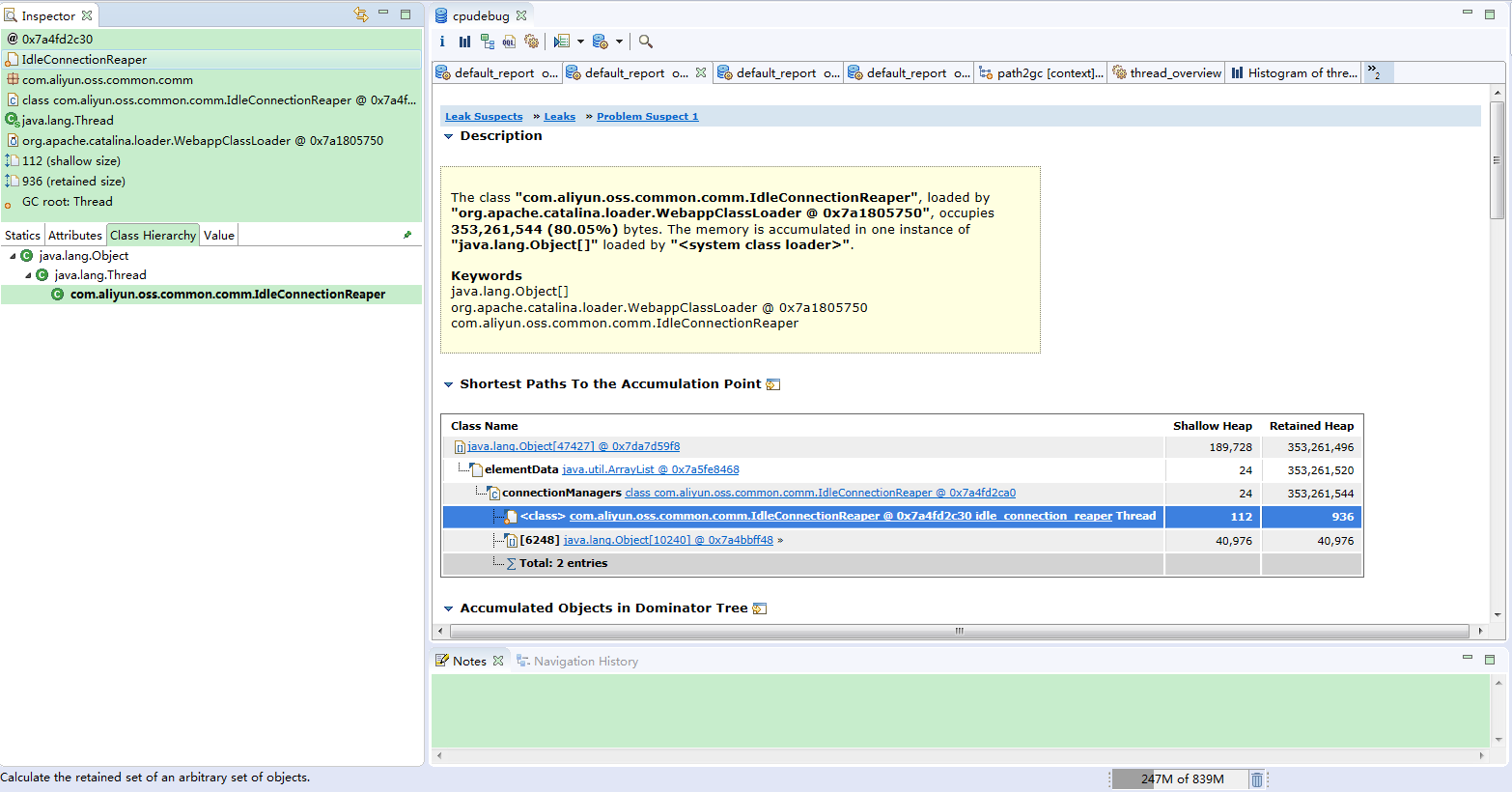
以下是整个过程记录:
1. 通过MAT工具分析之后,可以看到内存主要是被org.apache.http.impl.conn.PoolingHttpClientConnectionManager和com.aliyun.oss.common.comm.IdleConnectionReaper实例占用。
通过搜索发现类似的问题不少,原因都是在使用阿里云OSS存储时,OSS客户端专门建立了一个线程来管理其所需要的HTTP连接。在项目业务中考虑到并发比较大,每次都会创建一个新的OSS客户端对象,那么每次也都会往该List中添加新的连接。由于这些连接对象一直被持有,未正常关闭,所占用的内存无法释放,时间一长,创建的对象越来越多,占用的内存越来越大,一直到内存被使用完为止。
2. 既然是由于client未关闭导致的,于是在项目中主要关注的是OSS的工厂方法中的client对象是否有调用shutdown()方法释放对象,第一次排查之后,将方法中未调用shutdown()的地方都添加try finally进行关闭。且对照上线的前后两个版本,发现涉及OSS client调用的修改只有一处,对应方法中已经包含try finally的关闭操作。比较困惑为什么连接还是未关闭。于是试图在开发环境中复现该问题,通过模拟并发测试,运行了一天也没有出现类似的错误。于是开始怀疑是否是上一版本就已存在的老问题导致,进一步排查至所有大并发操作和其他OSS的工厂方法。可惜的是一直未有进展。这样花费了2-3天时间。
3. 项目在生产环境中采用的是前后台分离,都是多实例部署,且后台实例是无状态的,于是新买一台服务器部署后台实例,这样对服务影响比较小。通过在生产环境中直接部署添加了shutdown()的war包,看是否还会出现内存溢出的问题。经过1-2天时间,发现现象一样,且dump内存下来后,通过MAT分析发现还是一样。当然这需要持续关注内存、cpu情况,以免影响正常业务。
4. 开始怀疑是否修改未生效,毕竟这种直接修改代码未经过测试直接部署在生产环境的方式不是特别妥当。于是还是决定仔细review代码,项目中调用OSS的工厂方法都封装在一个类中,我们应该对类中每个方法的每一行代码进行排查。最终在如下代码中:
public static String getFileUrl(String key){
String result = "";
if(key == null || "".equals(key)) {
return result;
}
try {
result = client.generatePresignedUrl(...);
} catch(Exception e) {
logger.error(...);
} finally {
try {
client.shutdown()
} catch(Exception e1){
logger.error(...);
}
}
return result;
}发现如果key不存在或者为“”时,直接return而未进入try finally块中,这种情况下client对象未进行关闭,一直被持有,从而导致内存泄露。
5. 结合业务分析,上一个版本合入的功能,调用getFileUrl时需要先获取redis中的数据,由于平台先于APP上线,该redis中的数据目前是空,所以导致后续的client未进行正常关闭。修改也是比较简单,只需要将if判断语句移入try块中,确保finally中client.shutdown()正确被执行到。
当然通过部署在生产环境中的war包添加日志打印,且在每次进行new client()时,打印堆栈信息,可以查看是哪些业务功能在调用OSS。这样也可以定位出问题,毕竟在生产环境直接部署的方法不是什么时候都可以用的。
public class OssFileClientFactory {
......
private int callCount;
public OSSClient getClient(){
if(callCount < 200) {
callCount++;
StackTraceElement[] stacks = new Throwable().getStackTrace();
StringBuilder sb = new StringBuilder();
for (StackTraceElement stack : stacks) {
sb.append(stack.getClassName()).append(" ").append(stack.getMethodName())
.append(" ").append(stack.getLineNumber()).append("\n");
}
logger.error(sb.toString());
}
return new OSSClient(....);
}
.......
}6. 本地开发环境为什么没有复现,是因为开发环境中的redis中存在这些数据,只需要将对应的redis数据清除,再模拟该请求,并发量100左右时,通过命令可以看到CPU使用率持续在升高,且通过jstat -gcutil <jvmPid>发现FGC次数在升高。
7. 通过以上分析,修改后部署至生产环境,跑了一天左右,dump内存下来发现未有问题。
总结: 1. 代码中包含I/O流操作,OSS client操作等涉及资源关闭时,需要格外注意,必须加上close()或者shutdown()进行流关闭或资源释放操作。确认是否有try finally块,是否有未在try中的return代码。本文就是因为return代码未包含在try finally块中导致资源未释放的内存泄露问题。
2. 排查问题时,应该主要关注新合入代码,而排查代码时,没有仔细认真比对每一行代码,只是检查是否有finally块,是否调用了shutdown()方法,而忽略了异常情况下,直接return的代码块。
3. 本文除了使用jdk提供的一些工具可以下载内存,第三方工具MAT分析内存泄露原因等,还利用了logger.error()和打印堆栈信息,可以很快确定哪些业务调用了OSS相关方法。
4. 本文分析过程中还结合了项目中接口请求统计功能,查看了合入代码每10分钟内调用次数等信息,对排查问题也有一定的帮助。
5. 不建议在生产环境中直接部署修改后的代码进行验证。















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









