







LinkedHashMap 底层存储结构分析
HashMap 是无序的kv键值对容器,TreeMap 则是根据key进行排序的kv键值对容器,而LinkedHashMap同样也是一个有序的kv键值对容器,区别是其排序方式依据的是进入Map的先后顺序
LinkedHashMap 继承自 HashMap, 直接看其内部方法,并没有覆盖HashMap的增删查询接口,连tables数组也没有重新覆盖,所以数据结构基本没啥变化
1.继承体系
首先看继承体系如下

public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
看到这里,有个地方比较有意思,HashMap 既然已经实现了Map接口,为什么 LinkedHashMap 也要另外实现 Map 接口?
- 首先不显示添加这个实现是没有问题的,从继承体系来讲集成了
HashMap类,必然是实现了Map接口的 - 非功能角度出发,这样有什么好处?
- 继承体系一目了然,从源码上就可以看出这个是Map接口的一个实现
- 从源码中很清楚就可以得知Map中的方法,LinkedHashMap 可以直接使用,如果没有显示加上,则需要向上查找父类中的提供的方法
从个人角度触发,这应该是一种编程习惯的问题
2. 数据结构
同样从put(k,v)方法出发,通过查看新增一个kv对,数据是如何保存的来确定数据存储结构,因为 LinkedHashMap 并没有覆盖 put() 方法,所以可以确定底层的存储结构一致,那么有序是如何保证的呢?
查看源码,发现新增了两个成员
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
上面两个维护的是一个双向链表的头尾,这个链表根据插入Map的顺序来维护Node节点的,以此保证了顺序
3. 双向链表的维护
既然LinkedHashMap在HashMap的基础上维护了一个双向链表,那么这个链表的增删修改的逻辑是怎样的?
LinkedHashMap 扩展了 Entry类,新增了before, after, 分别指向该节点在链表中的前后节点
新创建一个节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将新增的节点放在链表的最后面
linkNodeLast(p);
return p;
}
依然以put(k,v)作为研究对象,分析链表的关系维护
主要方法: java.util.HashMap#putVal
1. 新增一个Map中已经存在的kv对
当插入已经存在的kv对时,不会创建新的Node节点,而会调用下面的方法
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
accessOrder true表示链表的顺序根据访问顺序来,false表示根据插入顺序来
默认会设置为false,此时上面的逻辑基本上不走到,即表示插入一个已存在的kv对,不会修改链表的顺序
如果显示设置 accessOrder为true,则会将修改的节点,放在链表的最后
2. 新增一个Map中不存在,且没有hash碰撞
新增一个不存在的kv对,首先是调用上面的方法,创建一个Node节点: LinkedHashMap.Entry<K,V>, 在创建节点的同时,就已经将节点放在了链表的最后, 实现逻辑如下
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
3. 新增一个Map中不存在,但出现hash碰撞
同上
小结
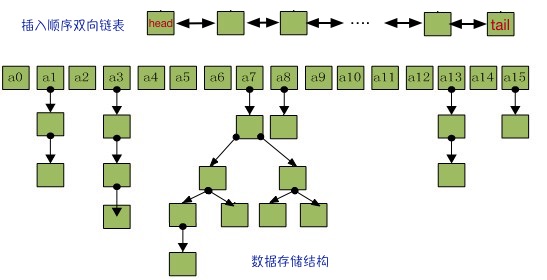
LinkedHashMap存储结构和HashMap相同,依然是数组+链表+红黑树LinkedHashMap额外持有一个双向链表,维护插入节点的顺序- 最终的数据结构如下图
- 实际的元素存储与HashMap一致,依然是数组+链表+红黑树的形式
- 区别在于:
- 除了维护数组+链表的结构之外,还根据插入Map先后顺序维护了一个双向链表的头尾head,tail
- Node基本结构,相比较HashMap而言,还增加了 before,after 两个分别指向双向链表中前后节点的属性
- 即下图中的双向链表中的节点,其实值依然是下面的数组+链表结构中的元素
相关博文
- JDK容器学习之HashMap (一) : 底层存储结构分析
- JDK容器学习之HashMap (二) : 读写逻辑详解
- JDK容器学习之HashMap (三) : 迭代器实现
- JDK容器学习之TreeMap (一) : 底层数据结构
- JDK容器学习之TreeMap (二) : 使用说明
关注更多
扫一扫二维码,关注小灰灰blog
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









