






其实原理简单来说,就是要选举leader,会生成一个zxid,然后分发给所有的server(所以这里一台server可以接受多台server给他发送要选举leader的请求),然后各个server根据发送给自己的zxid,选择一个值最大的,然后将这个选择返回给发送这个zxid的server,只要这个server收到的答复大于等于2/n+1个(也就是超过半数的同意票),则表明自己当选为leader,然后会向所有server广播自己已经成为leader。
概述
Zookeeper是Hadoop的一个子项目,它是分布式系统中的协调系统,可提供的服务主要有:配置服务、名字服务、分布式同步、组服务等。
它有如下的一些特点:简单
Zookeeper的核心是一个精简的文件系统,它支持一些简单的操作和一些抽象操作,例如,排序和通知。丰富
Zookeeper的原语操作是很丰富的,可实现一些协调数据结构和协议。例如,分布式队列、分布式锁和一组同级别节点中的“领导者选举”。高可靠
Zookeeper支持集群模式,可以很容易的解决单点故障问题。松耦合交互
不同进程间的交互不需要了解彼此,甚至可以不必同时存在,某进程在zookeeper中留下消息后,该进程结束后其它进程还可以读这条消息。资源库
Zookeeper实现了一个关于通用协调模式的开源共享存储库,能使开发者免于编写这类通用协议。
Getting Started
1.独立模式安装并启动
create it in conf/zoo.cfginitLimit=10
syncLimit=5
tickTime:指定了ZooKeeper的基本时间单位(以毫秒为单位)。
dataDir:存储内存数据快照位置。
clientPort:监听客户端连接端口。
initLimmit:启动zookeeper,从节点至主节点连接超时时间。(上面为10个tickTime)
syncLimit:zookeeper正常运行,若主从同步时间超过syncLimit,则丢弃该从节点。
配置完,启动zookeeperbin/zkServer.sh start
检查是否运行:echo ruok | nc localhost 2181
1.1连接到zookeeper$ bin/zkCli.sh -server 127.0.0.1:2181
在shell命令喊中使用help查看命令列表[zkshell: 0] help
如:
创建一个zookeeper节点:create /zk_test my_data
获取节点数据get /zk_test
修改节点数据set /zk_test junk
删除节点delete /zk_test
2.复制模式启动zookeeper
 tickTime=2000
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
注意:前一个端口用于leader和follower之间数据交换,后一个端口用于leader选举。
ZooKeeper Programmer's Guide
1. zookeeper数据模型
类似于文件系统,所有的节点都是绝对路径,将文件和目录抽象成znode。和Unix中的文件系统路径格式很想,但是只支持绝对路径,不支持相对路径,也不支持点号(”.”和”..”)。
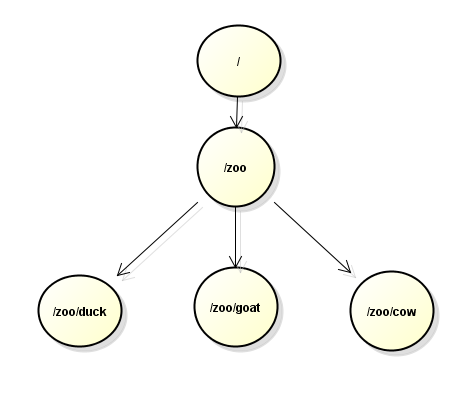
1.1 znode
维护了数据和ACL改变的版本号,每一次数据改变版本号增加,当有一个client去执行update和delete时候,必须提供一个数据变更版本号,如果与数据不符合,则更新失败。
1.2存储小数据
一般不超过1M,大量数据会花费更多的时间和延迟来完成数据拷贝,由于网络的消耗。
1.3 瞬时节点
随着会话结束而删除
When the session ends the znode is deleted. Because
of this behavior ephemeral znodes are not allowed to have children.
1.4操作的原子性
Znode的数据读写是原子的,要么读或写了完整的数据,要么就失败,不会出现只读或写了部分数据。
1.5 顺序znode
名称中包含Zookeeper指定顺序号的znode。若在创建znode时设置了顺序标识,那么该znode被创建后,名字的后边将会附加一串数字,该数字是由一个单调递增的计数器来生成的。例如,创建节点时传入的path是”/aa/bb”,创建后的则可能是”/aa/bb0002”,再次创建后是”/aa/bb0003”。
Znode的创建模式CreateMode有四种,分别是:EPHEMERAL(短暂的znode)、EPHEMERAL_SEQUENTIAL(短暂的顺序znode)、PERSISTENT(持久的znode)和PERSISTENT_SEQUENTIAL(持久的顺序znode)。如果您已经看过了上篇博文,那么这里的api调用应该是很好理解的,见:
2 zookeeper中的时间
Zxid:zookeeper状态的改变都会有事物id自增来维护。
Version numbers :znode的数据和ACL变更维护。
ticks:zookeeper集群部署时的时间单位。
3 zookeepr watches
可以在读操作exists、getChildren和getData上设置观察,在执行写操作create、delete和setData将会触发观察事件,当然,在执行写的操作时,也可以选择是否触发znode上设置的观察器,具体可查看相关的api。
当观察的znode被创建、删除或其数据被更新时,设置在exists上的观察将会被触发;
当观察的znode被删除或数据被更新时,设置在getData上的观察将会被触发;
当观察的znode的子节点被创建、删除或znode自身被删除时,设置在getChildren上的观察将会被触发,可通过观察事件的类型来判断被删除的是znode还是它的子节点。

注意:在收到收到触发事件到执行读操作之间,znode的状态可能会发生状态,这点需要牢记。
4 ACL
ACL权限:
• CREATE: you can create a child node
• READ: you can get data from a node and list its children.
• WRITE: you can set data for a node
• DELETE: you can delete a child node
• ADMIN: you can set permissions
身份验证模式:
• world 无验证
• auth 只能使用sessionID
• digest username:password 验证
• ip 客户端IP验证
• host客户端主机名验证
添加验证
可使用zk对象的addAuthInfo()方法来添加验证模式,如使用digest模式进行身份验证:zk.addAuthInfo(“digest”,”username:passwd”.getBytes());
在zookeeper对象被创建时,初始化会被添加world验证模式。world身份验证模式的验证id是”anyone”。
若该连接创建了znode,那么他将会被添加auth身份验证模式的验证id是””,即空字符串,这里将使用sessionID进行验证。
创建自定义验证:创建ACL对象时,可用ACL类的构造方法ACL(int perms, Id id)
5 zookeeper 内部原理选举领导
集群中所有的zk实例会选举出来一个“领导实例”(leader),其它实例称之为“随从实例”(follower)。如果leader出现故障,其余的实例会选出一台leader,并一起提供服务,若之前的leader恢复正常,便成为follower。选举follower是一个很快的过程,性能影响不明显。
Leader主要功能是协调所有实例实现写操作的原子性,即:所有的写操作都会转发给leader,然后leader会将更新广播给所有的follower,当半数以上的实例都完成写操作后,leader才会提交这个写操作,随后客户端会收到写操作执行成功的响应。原子广播
上边已经说到:所有的写操作都会转发给leader,然后leader会将更新广播给所有的follower,当半数以上的实例都完成写操作后,leader才会提交这个写操作,随后客户端会收到写操作执行成功的响应。这么来的话,就实现了客户端的写操作的原子性,每个写操作要么成功要么失败。逻辑和数据库的两阶段提交协议很像。
Znode的每次写操作都相当于数据库里的一次事务提交,每个写操作都有个全局唯一的ID,称为:zxid(ZooKeeper
Transaction)。ZooKeeper会根据写操作的zxid大小来对操作进行排序,zxid小的操作会先执行。zk下边的这些特性保证了它的数据一致性:顺序一致性
任意客户端的写操作都会按其发送的顺序被提交。如果一个客户端把某znode的值改为a,然后又把值改为b(后面没有其它任何修改),那么任何客户端在读到值为b之后都不会再读到a。原子性
这一点再前面已经说了,写操作只有成功和失败两种状态,不存在只写了百分之多少这么一说。单一系统映像
客户端只会连接host列表中状态最新的那些实例。如果正在连接到的实例挂了,客户端会尝试重新连接到集群中的其他实例,那么此时滞后于故障实例的其它实例都不会接收该连接请求,只有和故障实例版本相同或更新的实例才接收该连接请求。持久性
写操作完成之后将会被持久化存储,不受服务器故障影响。及时性
在对某个znode进行读操作时,应该先执行sync方法,使得读操作的连接所连的zk实例能与leader进行同步,从而能读到最新的类容。
注意:sync调用是异步的,无需等待调用的返回,zk服务器会保证所有后续的操作会在sync操作完成之后才执行,哪怕这些操作是在执行sync之前被提交的。
java构建zookeeper应用
http://www.cnblogs.com/ggjucheng/p/3370359.htmlString create(String path, byte[] data, List acl,CreateMode createMode)创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有四种形式的目录节点,分别是
PERSISTENT:持久化目录节点,这个目录节点存储的数据不会丢失;PERSISTENT_SEQUENTIAL:顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加
1,然后返回给客户端已经成功创建的目录节点名;EPHEMERAL:临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session
超时,这种节点会被自动删除;EPHEMERAL_SEQUENTIAL:临时自动编号节点
Stat exists(String path, boolean watch)判断某个 path 是否存在,并设置是否监控这个目录节点,这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher,exists方法还有一个重载方法,可以指定特定的watcher
Stat exists(String path,Watcher watcher)重载方法,这里给某个目录节点设置特定的 watcher,Watcher 在 ZooKeeper 是一个核心功能,Watcher
可以监控目录节点的数据变化以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置在这个目录节点上的
Watcher,从而每个客户端都很快知道它所关注的目录节点的状态发生变化,而做出相应的反应
void delete(String path, int version)删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据
ListgetChildren(String path, boolean watch)获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态
Stat setData(String path, byte[] data, int version)给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本
byte[] getData(String path, boolean watch, Stat stat)获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态
voidaddAuthInfo(String scheme, byte[] auth)客户端将自己的授权信息提交给服务器,服务器将根据这个授权信息验证客户端的访问权限。
Stat setACL(String path,List acl, int version)给某个目录节点重新设置访问权限,需要注意的是 Zookeeper 中的目录节点权限不具有传递性,父目录节点的权限不能传递给子目录节点。目录节点 ACL 由两部分组成:perms 和 id。
Perms 有 ALL、READ、WRITE、CREATE、DELETE、ADMIN 几种
而 id 标识了访问目录节点的身份列表,默认情况下有以下两种:
ANYONE_ID_UNSAFE = new Id("world", "anyone") 和 AUTH_IDS = new Id("auth", "") 分别表示任何人都可以访问和创建者拥有访问权限。
ListgetACL(String path,Stat stat)获取某个目录节点的访问权限列表
关闭防火墙:Exception in thread “main” org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for
public class TestZk { public static void main(String[] args) throws IOException, KeeperException, InterruptedException { // 创建一个与服务器的连接
ZooKeeper zk = new ZooKeeper("192.168.64.10:2181", ClientBase.CONNECTION_TIMEOUT, new Watcher() { // 监控所有被触发的事件
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
}
}); // 创建一个目录节点 ==>已经触发了 None 事件!
zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); // 创建一个子目录节点
zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT); // testRootData 此处false 不触发事件
System.out.println(new String(zk.getData("/testRootPath", false, null))); // 取出子目录节点列表 ==>[testChildPathOne] 在节点/testRootPath的getChildren上设置观察
System.out.println(zk.getChildren("/testRootPath", true)); // 修改子目录节点数据 由于上面的修改数据不触发观察 这边不执行事件
zk.setData("/testRootPath/testChildPathOne", "modifyChildDataOne".getBytes(), -1); // 目录节点状态:[5,5,1281804532336,1281804532336,0,1,0,0,12,1,6]
System.out.println("目录节点状态:[" + zk.exists("/testRootPath", true) + "]"); // 创建另外一个子目录节点 ==>已经触发了 NodeChildrenChanged 事件!
zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT); // testChildDataTwo
System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo", true, null))); // 删除子目录节点 已经触发了 NodeDeleted 事件!
zk.delete("/testRootPath/testChildPathTwo", -1);
zk.delete("/testRootPath/testChildPathOne", -1); // 删除父目录节点 已经触发了 NodeDeleted 事件!
zk.delete("/testRootPath", -1); // 关闭连接 zk.close();
}
}
运行结果

ZooKeeper 典型的应用场景
Zookeeper
从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper
就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式,关于
Zookeeper 的详细架构等内部细节可以阅读 Zookeeper 的源码
下面详细介绍这些典型的应用场景,也就是 Zookeeper 到底能帮我们解决那些问题?下面将给出答案。
1 统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了
JNDI,没错 Zookeeper 的 Name Service 与 JNDI
能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service
更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。
Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
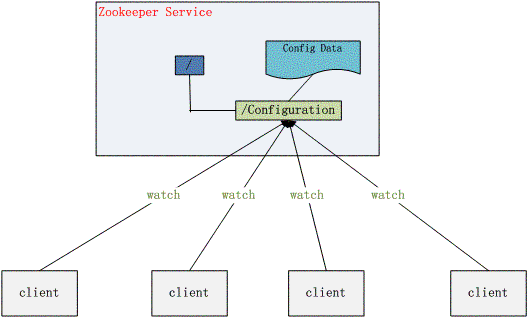
2 配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper
的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从
Zookeeper 获取新的配置信息应用到系统中.
配置管理结构图
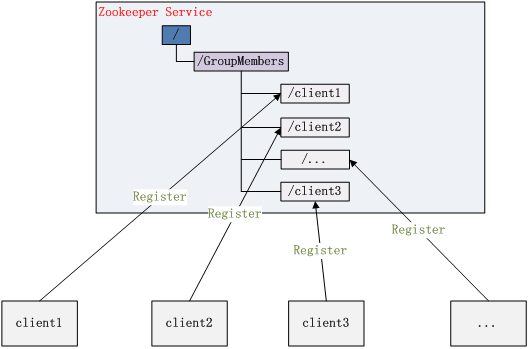
3 集群管理(Group Membership)
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server
组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台
Server,同样也必须让“总管”知道。
Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server
创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL
目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server
编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL
节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前
Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
集群管理结构图
Leader Election 关键代码
package net.xulingbo.zookeeper;
import org.apache.log4j.xml.DOMConfigurator;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;/**
*
* @author gaojiay
* */public class TestMainClient implements Watcher { protected static ZooKeeper zk = null; protected static Integer mutex; int sessionTimeout = 10000; protected String root;
public TestMainClient(String connectString) { if(zk == null){ try {
String configFile = this.getClass().getResource("/").getPath()+"net/xulingbo/zookeeper/log4j/log4j.xml";
DOMConfigurator.configure(configFile);
System.out.println("创建一个新的连接:");
zk = new ZooKeeper(connectString, sessionTimeout, this);
mutex = new Integer(-1);
} catch (IOException e) {
zk = null;
}
}
}
synchronized public void process(WatchedEvent event) {
synchronized (mutex) {
mutex.notify();
}
}
}
public class LeaderElection extends TestMainClient { public static final Logger logger = Logger.getLogger(LeaderElection.class); public LeaderElection(String connectString, String root) { super(connectString); this.root = root; if (zk != null) { try {
Stat s = zk.exists(root, false); if (s == null) {
zk.create(root, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
}
} void findLeader() throws InterruptedException, UnknownHostException, KeeperException { byte[] leader = null; try { //获取leader目录数据
leader = zk.getData(root + "/leader", true, null);
} catch (KeeperException e) { if (e instanceof KeeperException.NoNodeException) {
logger.error(e);
} else { throw e;
}
} if (leader != null) { //如果该集群中存在/leader目录,说明master还没有宕机
following(); //则该连接的主机为从节点
} else { //集群中没有/leader目录,则新建该临时节点(最先执行该方法的zk客户端将创建该leader目录)
String newLeader = null; byte[] localhost = InetAddress.getLocalHost().getAddress(); try {
newLeader = zk.create(root + "/leader", localhost, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (KeeperException e) { if (e instanceof KeeperException.NodeExistsException) {
logger.error(e);
} else { throw e;
}
} if (newLeader != null) {
leading(); //成为leader
} else {
mutex.wait();
}
}
}
@Override public void process(WatchedEvent event) { if (event.getPath().equals(root + "/leader") && event.getType() == Event.EventType.NodeCreated) {
System.out.println("得到通知"); super.process(event);
following();
}
} void leading() {
System.out.println("成为领导者");
} void following() {
System.out.println("成为组成员");
} public static void main(String[] args) {
TestMainServer.start();
String connectString = "localhost:" + TestMainServer.CLIENT_PORT;
LeaderElection le = new LeaderElection(connectString, "/GroupMembers"); try {
le.findLeader();
} catch (Exception e) {
logger.error(e);
}
}
}
4 Zookeeper 实现 Locks
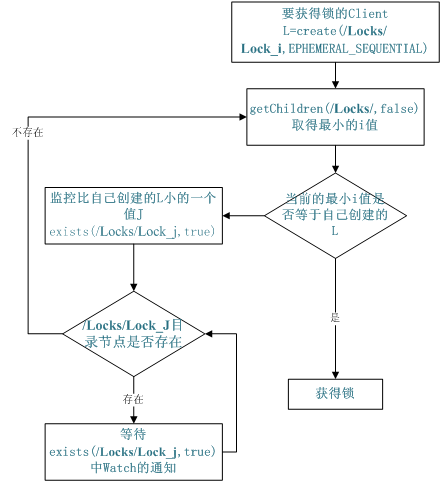
/*
加锁:
ZooKeeper 将按照如下方式实现加锁的操作:
1 ) ZooKeeper 调用 create ()方法来创建一个路径格式为“ _locknode_/lock- ”的节点,此节点类型为sequence (连续)和 ephemeral (临时)。也就是说,创建的节点为临时节点,并且所有的节点连续编号,即“ lock-i ”的格式。
2 )在创建的锁节点上调用 getChildren ()方法,来获取锁目录下的最小编号节点,并且不设置 watch 。
3 )步骤 2 中获取的节点恰好是步骤 1 中客户端创建的节点,那么此客户端获得此种类型的锁,然后退出操作。
4 )客户端在锁目录上调用 exists ()方法,并且设置 watch 来监视锁目录下比自己小一个的连续临时节点的状态。
5 )如果监视节点状态发生变化,则跳转到第 2 步,继续进行后续的操作,直到退出锁竞争。
解锁:
ZooKeeper 解锁操作非常简单,客户端只需要将加锁操作步骤 1 中创建的临时节点删除即可 */public class Locks extends TestMainClient { public static final Logger logger = Logger.getLogger(Locks.class);
String myZnode;
public Locks(String connectString, String root) { super(connectString); this.root = root; if (zk != null) { try { //创建锁节点,并不设置观察
Stat s = zk.exists(root, false); if (s == null) {
zk.create(root, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
}
} void getLock() throws KeeperException, InterruptedException{
List list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]); //对锁目录下 的所有子节点排序 Arrays.sort(nodes); //判断该zkclient创建的临时顺序节点是否为集群中最小的节点
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
} else{
waitForLock(nodes[0]);
}
} //创建zk客户端的临时瞬时节点,并尝试获取锁
void check() throws InterruptedException, KeeperException {
myZnode = zk.create(root + "/lock_" , new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);
getLock();
} void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ //发现最小的目录节点还未被移除,则等待 mutex.wait();
} else{
getLock();
}
}
@Override //发现有节点移除,该等待状态的客户端被notify
public void process(WatchedEvent event) { if(event.getType() == Event.EventType.NodeDeleted){
System.out.println("得到通知"); super.process(event);
doAction();
}
} /**
* 执行其他任务 */
private void doAction(){
System.out.println("同步队列已经得到同步,可以开始执行后面的任务了");
} public static void main(String[] args) {
TestMainServer.start();
String connectString = "localhost:"+TestMainServer.CLIENT_PORT;
Locks lk = new Locks(connectString, "/locks"); try {
lk.check();
} catch (InterruptedException e) {
logger.error(e);
} catch (KeeperException e) {
logger.error(e);
}
}
}
5 同步队列
同步队列用 Zookeeper 实现的实现思路如下:
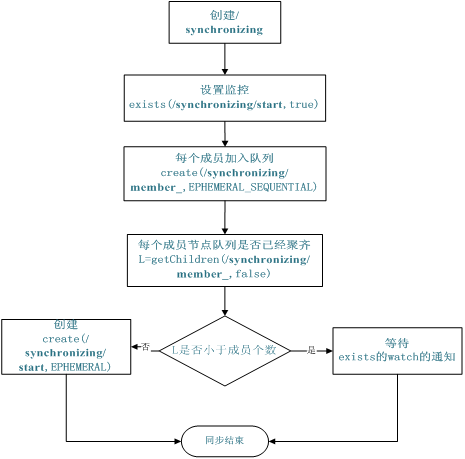
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start
是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 /
synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待
/synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
/**
* 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。 */public class Synchronizing extends TestMainClient { int size;
String name; public static final Logger logger = Logger.getLogger(Synchronizing.class); /**
* 构造函数
*
* @param connectString
* 服务器连接
* @param root
* 根目录
* @param size
* 队列大小 */
Synchronizing(String connectString, String root, int size) { super(connectString); this.root = root; this.size = size; if (zk != null) { try {
Stat s = zk.exists(root, false); if (s == null) {
zk.create(root, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
} try {
name = new String(InetAddress.getLocalHost().getCanonicalHostName()
.toString());
} catch (UnknownHostException e) {
logger.error(e);
}
} /**
* 加入队列
*
* @return
* @throws KeeperException
* @throws InterruptedException */
void addQueue() throws KeeperException, InterruptedException {
zk.exists(root + "/start", true);
zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) {
List list = zk.getChildren(root, false); //如果队列中子节点数小于size,则等待,如果不小于size,则创建start目录,其他client则触发事件,执行doAction
if (list.size()
mutex.wait();
} else {
zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
}
}
@Override public void process(WatchedEvent event) { if (event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated) {
System.out.println("得到通知"); super.process(event);
doAction();
}
} /**
* 执行其他任务 */
private void doAction() {
System.out.println("同步队列已经得到同步,可以开始执行后面的任务了");
} public static void main(String args[]) { // 启动Server TestMainServer.start();
String connectString = "localhost:" + TestMainServer.CLIENT_PORT; int size = 1;
Synchronizing b = new Synchronizing(connectString, "/synchronizing",
size); try {
b.addQueue();
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
}
}
6 FIFO队列(生产者-消费者)
/**
* 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
*
* 实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录
* /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( )
* 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。 */public class FIFOQueue extends TestMainClient { public static final Logger logger = Logger.getLogger(FIFOQueue.class); /**
* Constructor
*
* @param connectString
* @param root */
FIFOQueue(String connectString, String root) { super(connectString); this.root = root; if (zk != null) { try {
Stat s = zk.exists(root, false); if (s == null) {
zk.create(root, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
}
} /**
* 生产者
*
* @param i
* @return
*/
boolean produce(int i) throws KeeperException, InterruptedException {
ByteBuffer b = ByteBuffer.allocate(4); byte[] value;
b.putInt(i);
value = b.array();
zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL); return true;
} /**
* 消费者
*
* @return
* @throws KeeperException
* @throws InterruptedException */
int consume() throws KeeperException, InterruptedException { int retvalue = -1;
Stat stat = null; while (true) { synchronized (mutex) { // 对root的子节点设置监听
List list = zk.getChildren(root, true); // 如果没有任何子节点,则wait
if (list.size() == 0) {
mutex.wait();
} else {
Integer min = new Integer(list.get(0).substring(7)); for (String s : list) {
Integer tempValue = new Integer(s.substring(7)); if (tempValue
min = tempValue;
} byte[] b = zk.getData(root + "/element" + min, false, stat); // 获取到子节点数据之后 执行delete,并触发事件,执行所有cliet的notify
zk.delete(root + "/element" + min, 0);
ByteBuffer buffer = ByteBuffer.wrap(b);
retvalue = buffer.getInt(); return retvalue;
}
}
}
}
@Override public void process(WatchedEvent event) { super.process(event);
} public static void main(String args[]) { // 启动Server TestMainServer.start();
String connectString = "localhost:" + TestMainServer.CLIENT_PORT;
FIFOQueue q = new FIFOQueue(connectString, "/app1"); int i;
Integer max = new Integer(5);
System.out.println("Producer"); for (i = 0; i
q.produce(10 + i);
} catch (KeeperException e) {
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
} for (i = 0; i
System.out.println("Item: " + r);
} catch (KeeperException e) {
i--;
logger.error(e);
} catch (InterruptedException e) {
logger.error(e);
}
}
}
}















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









