







1.在编写mapreduce程序之前要先找齐maven依赖或所需要的jar包
maven依赖pom.xml:
<?xml version="1.0"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>lct</groupId>
<artifactId>cleaner</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<groupId>lct</groupId>
<artifactId>hadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hadoop</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<resources>
<resource>
<directory>resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<!-- execution元素包含了插件执行需要的信息 -->
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source> <!-- 源代码使用的开发版本 -->
<target>1.7</target> <!-- 需要生成的目标class文件的编译版本 -->
<!-- 一般而言,target与source是保持一致的,但是,有时候为了让程序能在其他版本的jdk中运行(对于低版本目标jdk,源代码中需要没有使用低版本jdk中不支持的语法),会存在target不同于source的情况 -->
</configuration>
</plugin>
</plugins>
<defaultGoal>compile</defaultGoal>
</build>
</project>
源代码:
Map:
package lct_mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapTest extends Mapper<LongWritable, Text, Text, LongWritable>{
//map端从文件中读取数据时,一次读一行,行号作为key(k1),该行的内容作为value(v1)
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
Text k2 = new Text();
LongWritable v2 = new LongWritable();
String line = value.toString();
String[] splits = line.split("\t");
for (String str : splits) {
//被切分后,一行中可能包含多个值,每个值都要写到HDFS上。要根据具体情况调整程序的逻辑结构
k2.set(str);
v2.set(1L);
context.write(k2, v2);
}
}
}
Reduce:
package lct_mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceTest extends Reducer<Text, LongWritable,Text, LongWritable>{
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//分组gropups、排序sort、分区partitions都是在reduce端完成的。
LongWritable v3 = new LongWritable();
long sum=0;
for (LongWritable lg : v2) {
sum+=lg.get();
}
v3.set(sum);
//把reduce端处理好的结果写到我们指定的目录下面
context.write(k2, v3);
}
}
App:
package lct_mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestApp {
public static void main(String[] args) throws Exception {
//获取输入输出路径
String inputPath=args[0];
Path outputDir=new Path(args[1]);
//加载配置文件
Configuration configs = new Configuration();
//如果输出路径已经存在,则删除已经存在的路径,因为输出路径已经存在,会报错
outputDir.getFileSystem(configs).delete(outputDir, true);
//获取一个作业对象
Job job = Job.getInstance(configs, TestApp.class.getSimpleName());
//设置打jar包必须的语句
job.setJarByClass(TestApp.class);
//设置待处理文件的输入路径
FileInputFormat.setInputPaths(job, inputPath);
//设置处理后的结果输出路径
FileOutputFormat.setOutputPath(job, outputDir);
//设置自定义的map
job.setMapperClass(MapTest.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置自定义的reduce
job.setReducerClass(ReduceTest.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//提交作业运行
job.waitForCompletion(true);
}
}
打包操作:
1.选中要打包的包或类,这里是一个包

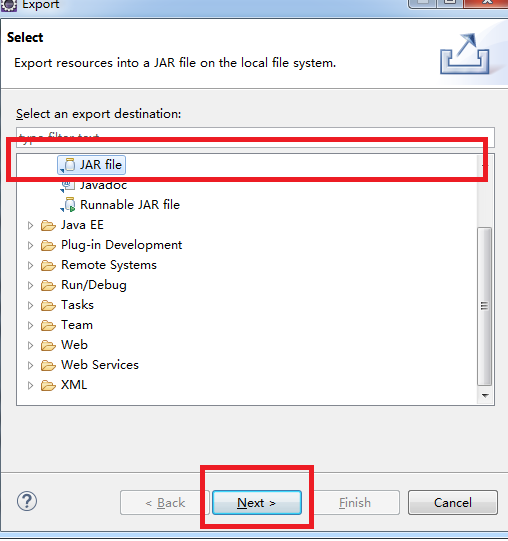
2.选中JAR file,然后next
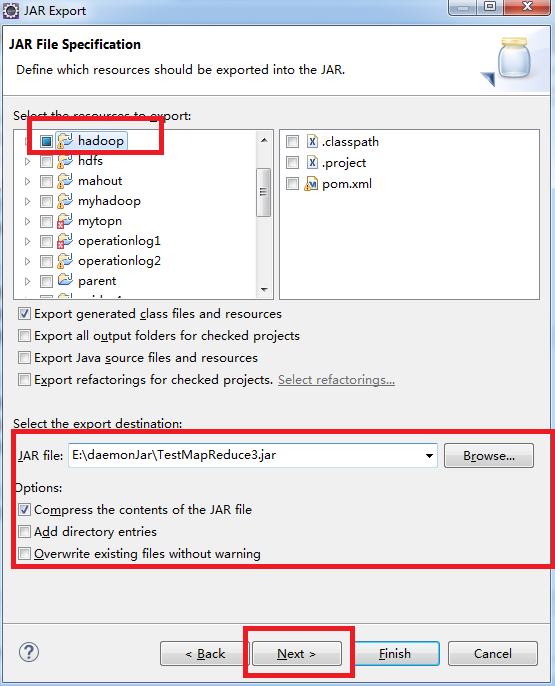
3.选中待打jar包要放的位置和填写jar的名称,然后next
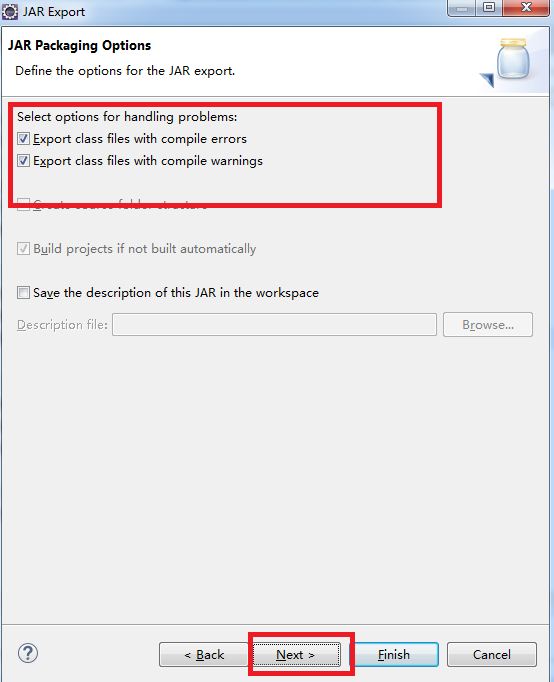
4.默认是勾选的
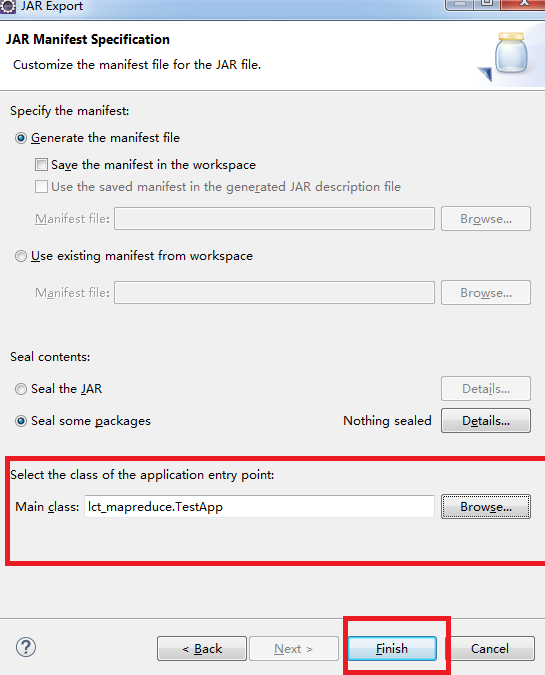
注意下面的选择主类框
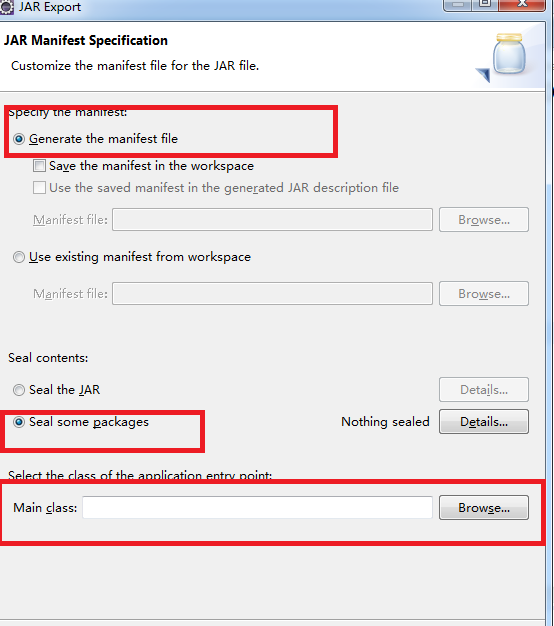
5.选择jar包执行时的主类,然后finish就可以了
jar包在hadoop集群上执行
1.要想jar包在Hadoop执行,要先保证Hadoop集群中相应的服务要开启;
如;namenode,datanode,resourcemanage,nodemanage,这些服务要保证正常运行。
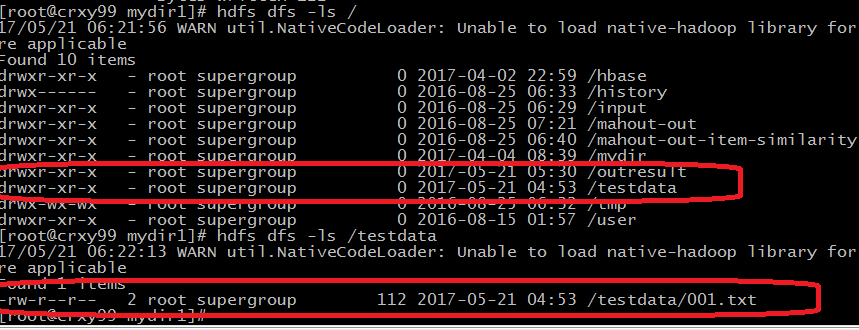
2.然后把生成的jar包放到Linux本地的某个目录下面,把待处理的数据上传到HDFS上的某个目录下面
3.执行jar
/testdata/001.txt:待处理的数据所在的位置
/outresult :结果输出的目录

hadoop jar TestMapReduce3.jar /testdata/001.txt /outresult
或
yarn jar TestMapReduce3.jar /testdata/001.txt /outresult
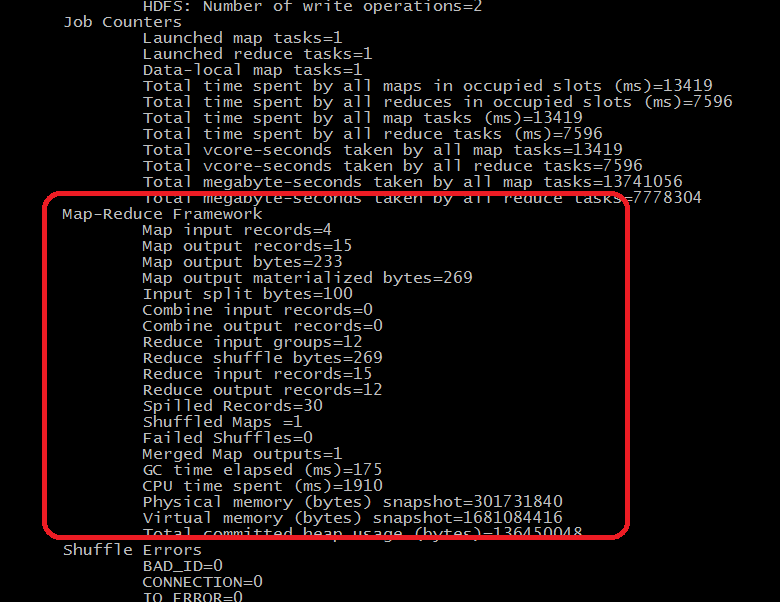
MapReduce执行的过程显示:















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









