







总体思路
storm编程和hadoop的mapreduce的编程很类似,hadoop的mapreduce需要自己实现map函数,reduce函数,还有一个主类驱动;storm需要自己实现spout,bolt和一个主函数。storm编程为以下三步:
创建一个Spout读取数据
创建bolt处理数据
创建一个主类,在主类中创建拓扑和一个集群对象,将拓扑提交到集群
Topology运行方式
Topology的运行可以分为本地模式和分布式模式,模式的设置可以在配置文件中设定,也可以在代码中设置。本地模式其实什么都不需要安装,有storm jar包就够了
(1)本地运行的提交方式:
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topologyName, conf, topology);
cluster.killTopology(topologyName);
cluster.shutdown();
(2)分布式提交方式:
StormSubmitter.submitTopology(topologyName, topologyConfig, builder.createTopology());
需要注意的是,在Storm代码编写完成之后,需要打包成jar包放到Nimbus中运行,打包的时候,不需要把依赖的jar都打进去,否则如果把依赖的storm.jar包打进去的话,运行时会出现重复的配置文件错误导致Topology无法运行。因为Topology运行之前,会加载本地的storm.yaml配置文件。
在Nimbus运行的命令如下:
storm jar StormTopology.jar maincalss args
Topology运行流程
有几点需要说明的地方:
(1)Storm提交后,会把代码首先存放到Nimbus节点的inbox目录下,之后,会把当前Storm运行的配置生成一个stormconf.ser文件放到Nimbus节点的stormdist目录中,在此目录中同时还有序列化之后的Topology代码文件;
(2)在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的executor数目和task数目,默认情况下,一个Topology的task的总和是和executor的总和一致的。之后,系统根据worker的数目,尽量平均的分配这些task的执行。worker在哪个supervisor节点上运行是由storm本身决定的;
(3)任务分配好之后,Nimbes节点会将任务的信息提交到zookeeper集群,同时在zookeeper集群中会有workerbeats节点,这里存储了当前Topology的所有worker进程的心跳信息;
(4)Supervisor节点会不断的轮询zookeeper集群,在zookeeper的assignments节点中保存了所有Topology的任务分配信息、代码存储目录、任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行;
(5)一个Topology运行之后,就会不断的通过Spouts来发送Stream流,通过Bolts来不断的处理接收到的Stream流,Stream流是无界的。
最后一步会不间断的执行,除非手动结束Topology。
Topology方法调用流程
Topology中的Stream处理时的方法调用过程如下:
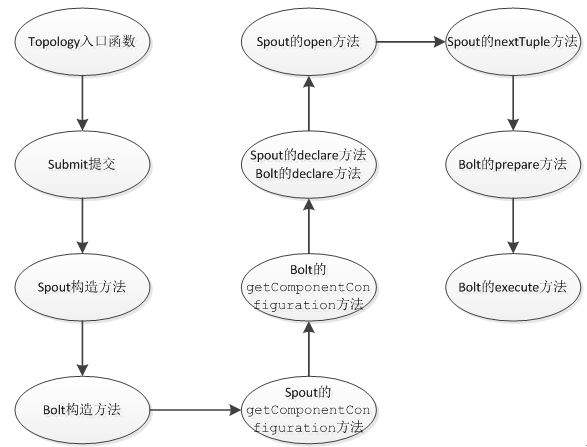 有几点需要说明的地方:
有几点需要说明的地方:
(1)每个组件(Spout或者Bolt)的构造方法和declareOutputFields方法都只被调用一次。
(2)open方法、prepare方法的调用是多次的。入口函数中设定的setSpout或者setBolt里的并行度参数指的是executor的数目,是负责运行组件中的task的线程 的数目,此数目是多少,上述的两个方法就会被调用多少次,在每个executor运行的时候调用一次。相当于一个线程的构造方法。
(3)nextTuple方法、execute方法是一直被运行的,nextTuple方法不断的发射Tuple,Bolt的execute不断的接收Tuple进行处理。只有这样不断地运行,才会产生无界的Tuple流,体现实时性。相当于线程的run方法。
(4)在提交了一个topology之后,Storm就会创建spout/bolt实例并进行序列化。之后,将序列化的component发送给所有的任务所在的机器(即Supervisor节点),在每一个任务上反序列化component。
(5)Spout和Bolt之间、Bolt和Bolt之间的通信,是通过zeroMQ的消息队列实现的。
(6)上图没有列出ack方法和fail方法,在一个Tuple被成功处理之后,需要调用ack方法来标记成功,否则调用fail方法标记失败,重新处理这个Tuple。
Topology并行度
在Topology的执行单元里,有几个和并行度相关的概念。
(1)worker:每个worker都属于一个特定的Topology,每个Supervisor节点的worker可以有多个,每个worker使用一个单独的端口,它对Topology中的每个component运行一个或者多个executor线程来提供task的运行服务。
(2)executor:executor是产生于worker进程内部的线程,会执行同一个component的一个或者多个task。
(3)task:实际的数据处理由task完成,在Topology的生命周期中,每个组件的task数目是不会发生变化的,而executor的数目却不一定。executor数目小于等于task的数目,默认情况下,二者是相等的。
在运行一个Topology时,可以根据具体的情况来设置不同数量的worker、task、executor,而设置的位置也可以在多个地方。
(1)worker设置:
(1.1)可以通过设置yaml中的topology.workers属性
(1.2)在代码中通过Config的setNumWorkers方法设定
(2)executor设置:
通过在Topology的入口类中setBolt、setSpout方法的最后一个参数指定,不指定的话,默认为1;
(3)task设置:
(3.1) 默认情况下,和executor数目一致;
(3.2)在代码中通过TopologyBuilder的setNumTasks方法设定具体某个组件的task数目;
终止Topology
通过在Nimbus节点利用如下命令来终止一个Topology的运行:
storm kill topologyName
kill之后,可以通过UI界面查看topology状态,会首先变成KILLED状态,在清理完本地目录和zookeeper集群中的和当前Topology相关的信息之后,此Topology就会彻底消失了。
Topology跟踪
Topology提交后,可以在Nimbus节点的web界面查看,默认的地址是http://NimbusIp:8080。















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









