







# -*- coding: UTF-8 -*-
#!/usr/bin/env python
from collections import Counter
import collections
import jieba.analyse
import jieba
import time
import re
import sys
#去除停用词
#stopwords = {}.fromkeys(['的', '包括', '等', '是'])
stopwords = {}.fromkeys([ line.strip() for line in open("stopwords.txt") ])
#读取文件路径
bill_path = r'article_nohtml.txt'
#写入文件路径
bill_result_path = r'result.txt'
#读取文件
with open(bill_path,'r') as fr:
all_the_text = fr.read()
#处理特殊字符
all_the_text = re.sub("\"|,|\.", "", all_the_text)
#分词
data = jieba.cut(all_the_text)
#计算频率
data = dict(Counter(data))
#以词频排序
def sort_by_count(d):
#字典排序
d = collections.OrderedDict(sorted(d.items(), key = lambda t: -t[1]))
return d
data = sort_by_count(data)
#将结果集写入文件
with open(bill_result_path,'w') as fw:
for k,v in data.items():
k = k.encode('utf-8')
#处理停用词
if k not in stopwords:
#写入结果
#fw.write(str(k)+':'+str(v)+'\n')
#fw.write("%s,%d\n" % (k,v))
fw.write(str(k)+':%d'%v + '\n')
#关闭流
fw.close()
运行结果图
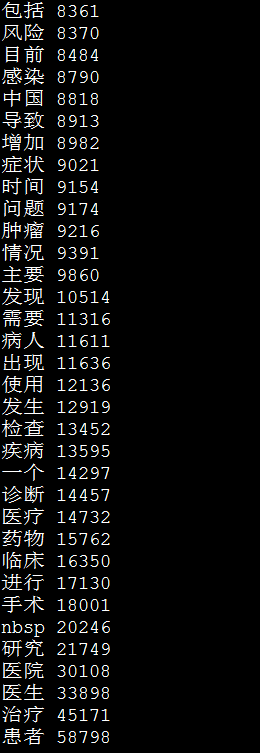















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









