






语法规则的书写
通过前面的学习,我们已经知道语法规则是使用 上下文无关文法来表示的。而 上下文无关文法 是由一组 替换规则(又叫产生式)组成的。具体看看下面的形式:
add -> mul | add + mul
mul -> pri | mul * pri
pri -> Id | Num | (add)
add -> mul | add + mul:加法表达式add可以替换成一个 乘法表达式mul ,或者替换成一个 加法表达式add 加上一个 乘法表达式mul。
mul -> pri | mul * pri :乘法表达式mul 可以替换成一个 基础表达式pri ,或者替换成一个 乘法表达式mul 乘上一个 基础表达式pri。
pri -> Id | Num | (add) :基础表达式pri 可以替换成一个 数字字面量Num,或者一个 变量 Id,或者一个括号带上加法表达式(add)。
对于 “2+3*5”,算术表达式的推导过程为例:
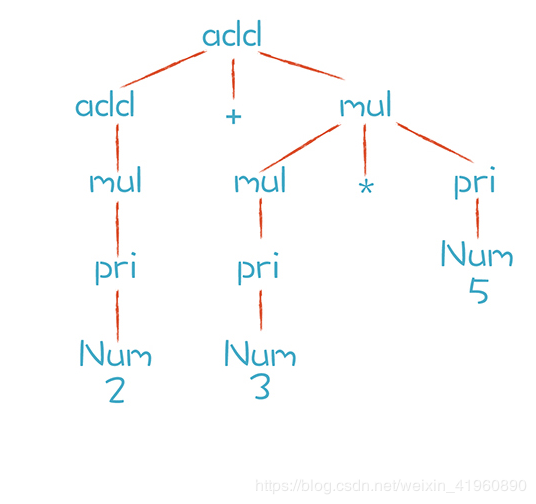
通过上图的推导过程,我们可以清楚地看到这两个表达式是怎样生成的。而分析过程中形成的这棵树,其实就是AST。我们通过观察发现,上图中的的叶子节点都是一个一个Token,如 “*”,“+”,还有 Num数字字面量。这些叶子节点称为 终结符,而那些非叶子节点称为 非终结符,因为它还可以继续往下替换。
我们常使用 巴克斯范式(BNF)来书写语法规则。意思跟前面是一样的,只是写法的形式不一样而已。
add ::= mul | add + mul
mul ::= pri | mul * pri
pri ::= Id | Num | (add)
有时候,我们也会接触到 扩展巴克斯范式(EBNF)。它在 巴克斯范式的基础上加入了类似正则表达式的写法。
add -> mul (+ mul)*
这种写法跟标准的 BNF 写法是等价的,但是更简洁。同时,我们可以再次说明:上下文无关文法包含了正则文法,比正则文法能做更多的事情。
如何确保优先级?
我们在做计算器的时候,已经知道由加法规则推导到乘法规则,这种方式保证了 AST 中的乘法节点一定会在加法节点的下层,也就保证了乘法计算优先于加法计算。
因此,我们应该把 关系运算(>、=、
exp -> or | or = exp
or -> and | or || and
and -> equal | and && equal
equal -> rel | equal == rel | equal != rel
rel -> add | rel > add | rel < add | rel >= add | rel <= add
add -> mul | add + mul | add - mul
mul -> pri | mul * pri | mul / pri
优先级从低到高:赋值运算、逻辑运算(or)、逻辑运算(and)、相等比较(equal)、大小比较(rel)、加法运算(add)、乘法运算(mul)和 基础表达式(pri)。
但是在实际中,情况可能会比较复杂,比如加上括号后,优先级就会发生改变。
其实,我们在最低层,也就是优先级最高的基础表达式(pri)这里,用括号把表达式包裹起来,递归地引用表达式就可以了。这样的话,只要在解析表达式的时候遇到括号,那么就知道这个是最优先的。这样的话就实现了优先级的改变:
pri -> Id | Literal | (exp)
那么到目前为止,我们已经能够解决表达式优先级的问题了。
如何确保结合性?
之前我们在写计算器的时候,在那里写的加法表达式的结合性是错误的,因为 “2 + 3 + 4” 表达式的计算顺序是 先计算了 “3 + 4”,然后才计算了 “ 2 + 7”,计算顺序并不是左结合。我们使用了错误的右递归文法,最终生成了错误的 AST,也即是下图:
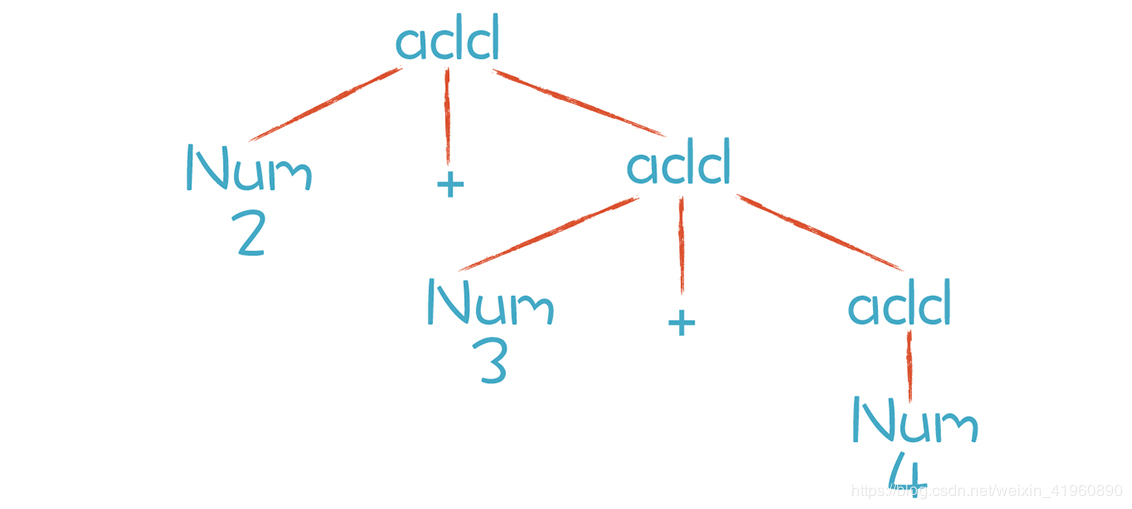
同样优先级的运算符是从左到右计算还是从右到左计算叫做结合性。我们常见的加减乘除等算术运算是左结合的,“.”符号也是左结合的。
因此,我们需要针对运算符是 左结合 还是 右结合 来决定 递归项 的位置。对于左结合的运算符,递归项要放在左边;而右结合的运算符,递归项放在右边。
所以加法应该这样书写:
add -> mul | add + mul
那么问题来了,大多数二元运算都是左结合的,那岂不是都要面临左递归问题?不用担心,我们可以通过改写左递归的文法,解决这个问题。
消除左递归问题
消除左递归,用一个标准的方法,就能够 把左递归文法改写成非左递归的文法。
以加法表达式规则为例,原来的文法是“add -> add + mul”,现在我们改写成:
add -> mul add'
add' -> + mul add' | ε
add -> mul add':加法可以替换成 乘法跟上一个 add'
add' -> + mul add' | ε:add' 可以替换为 + 乘法 或者是一个空集。
文法中,ε是空集的意思。
我们希望得到:
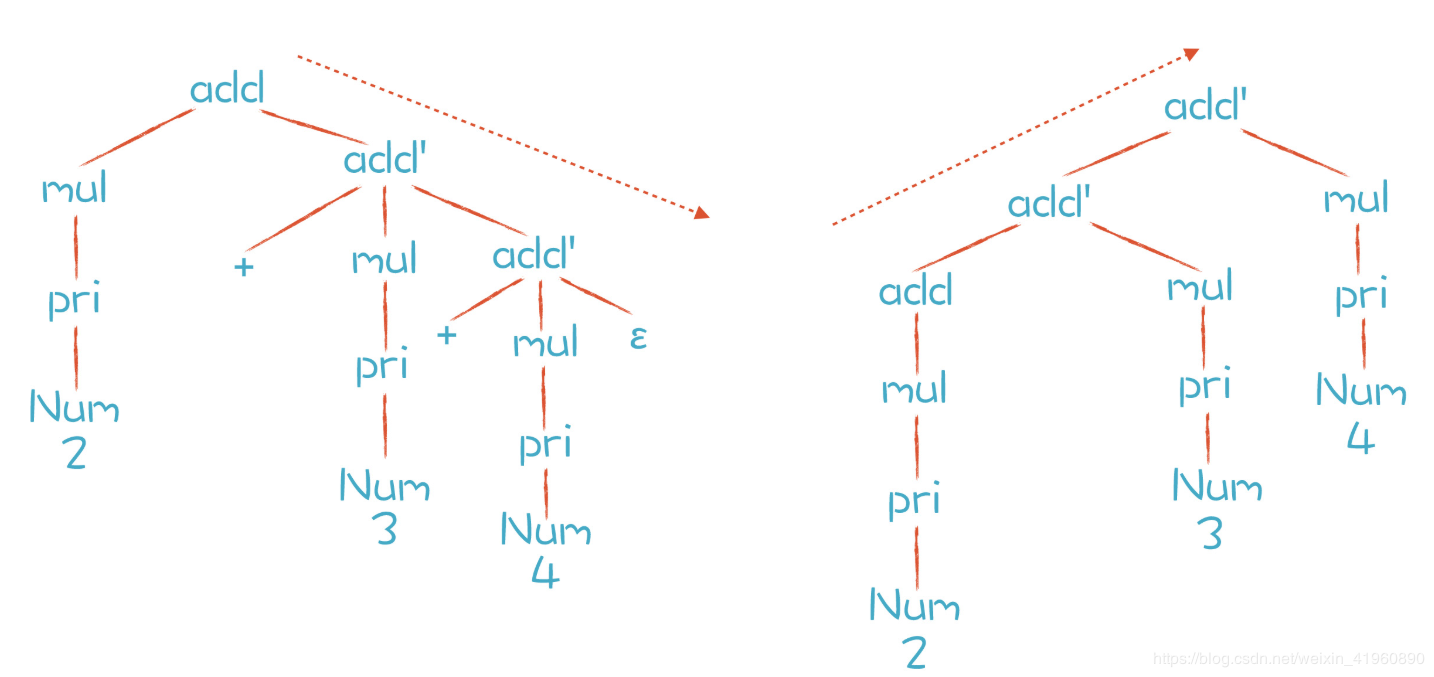
也就是说,在匹配加法表达式的时候,先匹配一个乘法表达式(继续往下可以推基础表达式),然后再看后面的加号和后面的乘法表达式。
但是还是出现了问题。由于 add’的规则是右递归的(在加号的右边),如果用标准的递归下降算法,我们会跟上一讲一样,又会出现运算符结合性的错误。我们期待的 AST 是右边的那棵,它的结合性才是正确的。那么有没有解决办法呢?
答案是有的。我们仔细分析一下上面语法规则的推导过程。只有第一步是按照 add 规则推导,之后都是按照 add’规则推导,一直到结束。如果用 EBNF 方式表达,也就是允许用 * 号和 + 号表示重复,上面两条规则可以合并成一条:
add -> mul (+ mul)*
能够优化我们写算法的思路。对于 (+ mul)* 这部分,我们其实可以写成一个循环,而不是一次次的递归调用。
mul();
while(next token is +){
mul()
createAddNode
}
在研究递归函数的时候,有一个概念叫做 尾递归,尾递归函数的最后一句是递归地调用自身(经典的尾递归就是斐波那契数列)。
编译程序通常都会把尾递归转化为一个循环语句,使用的原理跟上面的伪代码是一样的。相对于递归调用来说,循环语句对系统资源的开销更低,因此,把尾递归转化为循环语句也是一种编译优化技术。
于是对于加法表达式,我们可以更改代码:
private SimpleASTNode additive(TokenReader tokens) throws Exception {
SimpleASTNode child1 = multiplicative(tokens); //应用add规则
SimpleASTNode node = child1;
if (child1 != null) {
while (true) { //循环应用add'
Token token = tokens.peek();
if (token != null && (token.getType() == TokenType.Plus || token.getType() == TokenType.Minus)) {
token = tokens.read(); //读出加号
SimpleASTNode child2 = multiplicative(tokens); //计算下级节点
node = new SimpleASTNode(ASTNodeType.Additive, token.getText());
node.addChild(child1); //注意,新节点在顶层,保证正确的结合性
node.addChild(child2);
child1 = node;
} else {
break;
}
}
}
return node;
}
这样,我们就把左递归问题 解决了。
总结
优先级是通过在语法推导中的层次来决定的,优先级越低的,越先尝试推导。
结合性 是跟左递归还是右递归有关的,左递归导致左结合,右递归导致右结合。
左递归可以通过改写语法规则来避免,而改写后的语法又可以表达成简洁的 EBNF 格式,从而启发我们用循环代替右递归。















 4593
4593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









