






让我们创建一个字库,它使我们可以键入一个字母,该字母可以用SVG path "M 20 -20 L 20 680 700 680 700 -20 20 -20 M 170 130 L 550 130 550 530 170 530"来定义,这是用简洁的方式来说"它看起来像一个矩形,而从中挖去了一个更小的矩形"。我们将使这个形状坐落于波浪号的地点,"~",但是,当我们键入一个完整的单词时它自动地展示出来可能更有用 (如同你能在 symbolset.com上看到的巧妙地演示一般),我们也将使它在我们键入单词"custom"展示出来。
如此碰巧,这个页面在运行一个JavaScript库,它可以构建定制的字库,如同我们上面建议的那个,而且刚刚所说的字库实际已由你的浏览器构建了。这个库也为这个页面加载结果字库作为一个webfont (使用一个@font-face CSS rule和a styling class),因而,让我们看一下你的浏览器是如何制造它的吧!
字符~,现在在应用我们的字符时,会被styled为 ,而且类似地,字符串"custom"也会被styled为。现在,由于这本质上只是in-font魔法,因而在复制-粘贴第一个矩形时应当让你粘贴了纯文本字符串"~",而复制-粘贴第二个矩形时,你应该粘贴了纯文本字符串"custom"。
,而且类似地,字符串"custom"也会被styled为。现在,由于这本质上只是in-font魔法,因而在复制-粘贴第一个矩形时应当让你粘贴了纯文本字符串"~",而复制-粘贴第二个矩形时,你应该粘贴了纯文本字符串"custom"。


这也是图标字体工作的方式
我们有一个字体,它建模了"一个形状",而且我们有一个可以键入的标签,它可以被魔法般地转换成那个形状。基本上这就是你曾见到的每个 (好的) 图标字库工作的方式。但是,它们是如何工作的呢?让我们深入研究一下。
(实际上,它也是,比如,许多重音字母工作的方式。。。)
尽管如é这样的字母可以以"on their own"的方式出现,但它们也可以被写为序列[e´]。实际上智能的字体可以重定位重音,从而使得结合看起来为é,或者它们可以执行一个"ligature"替换,把两个字符[e]+[´]替换为单独的字符[é]。
让我们看一下实际的字体布局
如果你要加载一个 (真正的) 小字体文件的话,下面的两个表是你将常常在一个hex编辑器中看到的两类东西。在左边我们看到了16进制数形式的字库的字节码,而在右边我们看到了“尽可能直观的显示”字母形式的字节表 (基于iso 8859-1 code page)。你可以在右边辨认出一些单词,比如"name"和"License-free",但是它的大部分看起来都是杂乱无章难以辨认的。然而,如果你知道了如何读取一个字体,这个视图也就没有秘密可守了,字体能做的事情就在那里,只是以不同的语言书写罢了。它甚至都没有被混淆或压缩过,它字面上只是一个不同的写下数字的图画的方式。
And try to mouse-over the data: Each block of data has a tooltip title explaining what you're hovered on!
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 4F | 54 | 54 | 4F | 00 | 0A | 00 | 80 | 00 | 03 | 00 | 20 | 43 | 46 | 46 | 20 |
| 0x10 | E5 | 7A | 18 | AA | 00 | 00 | 04 | 04 | 00 | 00 | 00 | D3 | 47 | 53 | 55 | 42 |
| 0x20 | 20 | A5 | 25 | 76 | 00 | 00 | 04 | D8 | 00 | 00 | 00 | 62 | 4F | 53 | 2F | 32 |
| 0x30 | 30 | DB | 24 | DA | 00 | 00 | 01 | 10 | 00 | 00 | 00 | 60 | 63 | 6D | 61 | 70 |
| 0x40 | 01 | 8F | 02 | 5B | 00 | 00 | 03 | 78 | 00 | 00 | 00 | 6A | 68 | 65 | 61 | 64 |
| 0x50 | 0D | 25 | 73 | 26 | 00 | 00 | 00 | AC | 00 | 00 | 00 | 36 | 68 | 68 | 65 | 61 |
| 0x60 | 06 | 96 | 01 | 58 | 00 | 00 | 00 | E4 | 00 | 00 | 00 | 24 | 68 | 6D | 74 | 78 |
| 0x70 | 02 | A8 | 00 | 14 | 00 | 00 | 05 | 3C | 00 | 00 | 00 | 20 | 6D | 61 | 78 | 70 |
| 0x80 | 00 | 08 | 50 | 00 | 00 | 00 | 01 | 08 | 00 | 00 | 00 | 06 | 6E | 61 | 6D | 65 |
| 0x90 | 01 | AD | 5A | FF | 00 | 00 | 01 | 70 | 00 | 00 | 02 | 07 | 70 | 6F | 73 | 74 |
| 0xA0 | 00 | 03 | 00 | 01 | 00 | 00 | 03 | E4 | 00 | 00 | 00 | 20 | 00 | 01 | 00 | 00 |
| 0xB0 | 00 | 01 | 00 | 00 | FE | 3C | 71 | 41 | 5F | 0F | 3C | F5 | 00 | 00 | 04 | 00 |
| 0xC0 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0xD0 | 00 | 14 | FF | EC | 02 | BC | 02 | A8 | 00 | 00 | 00 | 08 | 00 | 02 | 00 | 00 |
| 0xE0 | 00 | 00 | 00 | 00 | 00 | 01 | 00 | 00 | 03 | EC | FE | A8 | 00 | 00 | 02 | A8 |
| 0xF0 | 00 | 00 | 00 | 00 | 02 | A8 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x100 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 08 | 00 | 00 | 50 | 00 | 00 | 08 | 00 | 00 |
| 0x110 | 00 | 03 | 00 | 00 | 01 | 90 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x120 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x130 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 01 | 00 | 00 |
| 0x140 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 20 | 3D | 29 | 20 | 00 | 40 |
| 0x150 | 00 | 63 | 00 | 7E | 02 | A8 | FF | EC | 01 | 44 | 03 | EC | 01 | 58 | 00 | 00 |
| 0x160 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 7E | 00 | 06 |
| 0x170 | 00 | 00 | 00 | 14 | 00 | F6 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 0C |
| 0x180 | 00 | 00 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 01 | 00 | 06 | 00 | 24 | 00 | 01 |
| 0x190 | 00 | 00 | 00 | 00 | 00 | 02 | 00 | 07 | 00 | 36 | 00 | 01 | 00 | 00 | 00 | 00 |
| 0x1A0 | 00 | 03 | 00 | 01 | 00 | 4B | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 04 | 00 | 11 |
| 0x1B0 | 00 | 4E | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 05 | 00 | 0B | 00 | 81 | 00 | 01 |
| 0x1C0 | 00 | 00 | 00 | 00 | 00 | 06 | 00 | 0A | 00 | A2 | 00 | 01 | 00 | 00 | 00 | 00 |
| 0x1D0 | 00 | 07 | 00 | 0E | 00 | C0 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 0D | 00 | 0C |
| 0x1E0 | 00 | EA | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 13 | 00 | 01 | 01 | 0E | 00 | 03 |
| 0x1F0 | 00 | 01 | 04 | 09 | 00 | 00 | 00 | 18 | 00 | 0C | 00 | 03 | 00 | 01 | 04 | 09 |
| 0x200 | 00 | 01 | 00 | 0C | 00 | 2A | 00 | 03 | 00 | 01 | 04 | 09 | 00 | 02 | 00 | 0E |
| 0x210 | 00 | 3D | 00 | 03 | 00 | 01 | 04 | 09 | 00 | 03 | 00 | 02 | 00 | 4C | 00 | 03 |
| 0x220 | 00 | 01 | 04 | 09 | 00 | 04 | 00 | 22 | 00 | 5F | 00 | 03 | 00 | 01 | 04 | 09 |
| 0x230 | 00 | 05 | 00 | 16 | 00 | 8C | 00 | 03 | 00 | 01 | 04 | 09 | 00 | 06 | 00 | 14 |
| 0x240 | 00 | AC | 00 | 03 | 00 | 01 | 04 | 09 | 00 | 07 | 00 | 1C | 00 | CE | 00 | 03 |
| 0x250 | 00 | 01 | 04 | 09 | 00 | 0D | 00 | 18 | 00 | F6 | 00 | 03 | 00 | 01 | 04 | 09 |
| 0x260 | 00 | 13 | 00 | 02 | 01 | 0F | 4C | 69 | 63 | 65 | 6E | 73 | 65 | 2D | 66 | 72 |
| 0x270 | 65 | 65 | 00 | 4C | 00 | 69 | 00 | 63 | 00 | 65 | 00 | 6E | 00 | 73 | 00 | 65 |
| 0x280 | 00 | 2D | 00 | 66 | 00 | 72 | 00 | 65 | 00 | 65 | 43 | 75 | 73 | 74 | 6F | 6D |
| 0x290 | 00 | 43 | 00 | 75 | 00 | 73 | 00 | 74 | 00 | 6F | 00 | 6D | 52 | 65 | 67 | 75 |
| 0x2A0 | 6C | 61 | 72 | 00 | 52 | 00 | 65 | 00 | 67 | 00 | 75 | 00 | 6C | 00 | 61 | 00 |
| 0x2B0 | 72 | 2D | 00 | 2D | 43 | 75 | 73 | 74 | 6F | 6D | 20 | 47 | 6C | 79 | 70 | 68 |
| 0x2C0 | 20 | 46 | 6F | 6E | 74 | 00 | 43 | 00 | 75 | 00 | 73 | 00 | 74 | 00 | 6F | 00 |
| 0x2D0 | 6D | 00 | 20 | 00 | 47 | 00 | 6C | 00 | 79 | 00 | 70 | 00 | 68 | 00 | 20 | 00 |
| 0x2E0 | 46 | 00 | 6F | 00 | 6E | 00 | 74 | 56 | 65 | 72 | 73 | 69 | 6F | 6E | 20 | 31 |
| 0x2F0 | 2E | 30 | 00 | 56 | 00 | 65 | 00 | 72 | 00 | 73 | 00 | 69 | 00 | 6F | 00 | 6E |
| 0x300 | 00 | 20 | 00 | 31 | 00 | 2E | 00 | 30 | 63 | 75 | 73 | 74 | 6F | 6D | 66 | 6F |
| 0x310 | 6E | 74 | 00 | 63 | 00 | 75 | 00 | 73 | 00 | 74 | 00 | 6F | 00 | 6D | 00 | 66 |
| 0x320 | 00 | 6F | 00 | 6E | 00 | 74 | 54 | 72 | 61 | 64 | 65 | 6D | 61 | 72 | 6B | 2D |
| 0x330 | 66 | 72 | 65 | 65 | 00 | 54 | 00 | 72 | 00 | 61 | 00 | 64 | 00 | 65 | 00 | 6D |
| 0x340 | 00 | 61 | 00 | 72 | 00 | 6B | 00 | 2D | 00 | 66 | 00 | 72 | 00 | 65 | 00 | 65 |
| 0x350 | 4C | 69 | 63 | 65 | 6E | 73 | 65 | 2D | 66 | 72 | 65 | 65 | 00 | 4C | 00 | 69 |
| 0x360 | 00 | 63 | 00 | 65 | 00 | 6E | 00 | 73 | 00 | 65 | 00 | 2D | 00 | 66 | 00 | 72 |
| 0x370 | 00 | 65 | 00 | 65 | 7E | 00 | 7E | 00 | 00 | 00 | 00 | 01 | 00 | 03 | 00 | 01 |
| 0x380 | 00 | 00 | 00 | 0C | 00 | 04 | 00 | 5E | 00 | 00 | 00 | 10 | 00 | 10 | 00 | 03 |
| 0x390 | 00 | 00 | 00 | 63 | 00 | 6D | 00 | 6F | 00 | 73 | 00 | 74 | 00 | 75 | 00 | 7E |
| 0x3A0 | FF | FF | 00 | 00 | 00 | 63 | 00 | 6D | 00 | 6F | 00 | 73 | 00 | 74 | 00 | 75 |
| 0x3B0 | 00 | 7E | FF | FF | FF | 9E | FF | 95 | FF | 94 | FF | 91 | FF | 91 | FF | 91 |
| 0x3C0 | FF | 89 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x3D0 | 00 | 00 | 00 | 00 | 00 | 01 | 00 | 02 | 00 | 03 | 00 | 04 | 00 | 05 | 00 | 06 |
| 0x3E0 | 00 | 07 | 00 | 00 | 00 | 03 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x3F0 | 00 | 00 | 00 | 01 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x400 | 00 | 00 | 00 | 00 | 01 | 00 | 04 | 01 | 00 | 01 | 01 | 01 | 0B | 63 | 75 | 73 |
| 0x410 | 74 | 6F | 6D | 66 | 6F | 6E | 74 | 00 | 01 | 01 | 01 | 23 | F8 | 1B | 00 | F8 |
| 0x420 | 1C | 02 | F8 | 1D | 03 | F8 | 19 | 04 | 8C | 0D | 9F | 77 | F9 | 50 | F9 | 3C |
| 0x430 | 05 | F7 | 07 | 0F | F7 | 16 | 10 | F7 | 1F | 11 | 9B | F7 | 57 | 12 | 00 | 0A |
| 0x440 | 01 | 01 | 0C | 1D | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 2A | 56 | 65 | 72 | 73 |
| 0x450 | 69 | 6F | 6E | 20 | 31 | 2E | 30 | 43 | 75 | 73 | 74 | 6F | 6D | 20 | 47 | 6C |
| 0x460 | 79 | 70 | 68 | 20 | 46 | 6F | 6E | 74 | 43 | 75 | 73 | 74 | 6F | 6D | 63 | 6D |
| 0x470 | 6F | 73 | 74 | 75 | 7E | 00 | 00 | 00 | 01 | 8A | 01 | 8B | 01 | 8C | 01 | 8D |
| 0x480 | 01 | 8E | 01 | 8F | 01 | 90 | 00 | 07 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 00 |
| 0x490 | 08 | 01 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 2D | 0E | 0E | 0E | 0E | 0E |
| 0x4A0 | 0E | 0E | 9F | 77 | 15 | 8B | F9 | 50 | 05 | F9 | 3C | 8B | 05 | 8B | FD | 50 |
| 0x4B0 | 05 | FD | 3C | 8B | 05 | F7 | 2A | F7 | 2A | 15 | F8 | 10 | 8B | 05 | 8B | F8 |
| 0x4C0 | 24 | 05 | FC | 10 | 8B | 05 | 0E | 8B | 8B | 06 | 8B | 8B | 08 | 95 | 0A | 95 |
| 0x4D0 | 0B | F9 | 50 | 14 | F9 | 50 | 15 | 00 | 00 | 01 | 00 | 00 | 00 | 0A | 00 | 24 |
| 0x4E0 | 00 | 32 | 00 | 02 | 44 | 46 | 4C | 54 | 00 | 0E | 6C | 61 | 74 | 6E | 00 | 0E |
| 0x4F0 | 00 | 04 | 00 | 00 | 00 | 00 | FF | FF | 00 | 01 | 00 | 00 | 00 | 01 | 6C | 69 |
| 0x500 | 67 | 61 | 00 | 08 | 00 | 00 | 00 | 01 | 00 | 00 | 00 | 01 | 00 | 04 | 00 | 04 |
| 0x510 | 00 | 00 | 00 | 01 | 00 | 08 | 00 | 01 | 00 | 08 | 00 | 01 | 00 | 12 | 00 | 02 |
| 0x520 | 00 | 01 | 00 | 01 | 00 | 01 | 00 | 00 | 00 | 01 | 00 | 04 | 00 | 07 | 00 | 06 |
| 0x530 | 00 | 06 | 00 | 04 | 00 | 05 | 00 | 03 | 00 | 02 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x540 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 |
| 0x550 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 00 | 02 | A8 | 00 | 14 | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | O | T | T | O | | | | | | | C | F | F | | ||
| 0x10 | å | z | ª | | | | | | Ó | G | S | U | B | |||
| 0x20 | | ¥ | % | v | | | Ø | | | | b | O | S | / | 2 | |
| 0x30 | 0 | Û | $ | Ú | | | | | | ` | c | m | a | p | ||
| 0x40 | [ | | | x | | | | j | h | e | a | d | ||||
| 0x50 | | % | s | & | | | | ¬ | | | | 6 | h | h | e | a |
| 0x60 | X | | | | ä | | | | $ | h | m | t | x | |||
| 0x70 | ¨ | | | | < | | | | | m | a | x | p | |||
| 0x80 | | P | | | | | | | n | a | m | e | ||||
| 0x90 | | Z | ÿ | | | p | | | p | o | s | t | ||||
| 0xA0 | | | | | ä | | | | | | | | ||||
| 0xB0 | | | | þ | < | q | A | _ | < | õ | | | | |||
| 0xC0 | | | | | | | | | | | | | | | | |
| 0xD0 | | ÿ | ì | ¼ | ¨ | | | | | | | |||||
| 0xE0 | | | | | | | | ì | þ | ¨ | | | ¨ | |||
| 0xF0 | | | | | ¨ | | | | | | | | | | | |
| 0x100 | | | | | | | | | | P | | | | | ||
| 0x110 | | | | | | | | | | | | | ||||
| 0x120 | | | | | | | | | | | | | | | | |
| 0x130 | | | | | | | | | | | | | | | | |
| 0x140 | | | | | | | | | | | | = | ) | | | @ |
| 0x150 | | c | | ~ | ¨ | ÿ | ì | D | ì | X | | | ||||
| 0x160 | | | | | | | | | | | | | ~ | | ||
| 0x170 | | | | | ö | | | | | | | | | | ||
| 0x180 | | | | | | | | | | | $ | | ||||
| 0x190 | | | | | | | | 6 | | | | | | |||
| 0x1A0 | | | | K | | | | | | | | |||||
| 0x1B0 | | N | | | | | | | | | | | ||||
| 0x1C0 | | | | | | | | | ¢ | | | | | | ||
| 0x1D0 | | | | À | | | | | | | | | | |||
| 0x1E0 | | ê | | | | | | | | | ||||||
| 0x1F0 | | | | | | | | | | | ||||||
| 0x200 | | | | | * | | | | | | ||||||
| 0x210 | | = | | | | | | | L | | ||||||
| 0x220 | | | | | " | | _ | | | | ||||||
| 0x230 | | | | | | | | | ||||||||
| 0x240 | | ¬ | | | | | | | Î | | ||||||
| 0x250 | | | | | | | ö | | | | ||||||
| 0x260 | | | L | i | c | e | n | s | e | - | f | r | ||||
| 0x270 | e | e | | L | | i | | c | | e | | n | | s | | e |
| 0x280 | | - | | f | | r | | e | | e | C | u | s | t | o | m |
| 0x290 | | C | | u | | s | | t | | o | | m | R | e | g | u |
| 0x2A0 | l | a | r | | R | | e | | g | | u | | l | | a | |
| 0x2B0 | r | - | | - | C | u | s | t | o | m | | G | l | y | p | h |
| 0x2C0 | | F | o | n | t | | C | | u | | s | | t | | o | |
| 0x2D0 | m | | | | G | | l | | y | | p | | h | | | |
| 0x2E0 | F | | o | | n | | t | V | e | r | s | i | o | n | | 1 |
| 0x2F0 | . | 0 | | V | | e | | r | | s | | i | | o | | n |
| 0x300 | | | | 1 | | . | | 0 | c | u | s | t | o | m | f | o |
| 0x310 | n | t | | c | | u | | s | | t | | o | | m | | f |
| 0x320 | | o | | n | | t | T | r | a | d | e | m | a | r | k | - |
| 0x330 | f | r | e | e | | T | | r | | a | | d | | e | | m |
| 0x340 | | a | | r | | k | | - | | f | | r | | e | | e |
| 0x350 | L | i | c | e | n | s | e | - | f | r | e | e | | L | | i |
| 0x360 | | c | | e | | n | | s | | e | | - | | f | | r |
| 0x370 | | e | | e | ~ | | ~ | | | | | | | |||
| 0x380 | | | | | | | ^ | | | | | | ||||
| 0x390 | | | | c | | m | | o | | s | | t | | u | | ~ |
| 0x3A0 | ÿ | ÿ | | | | c | | m | | o | | s | | t | | u |
| 0x3B0 | | ~ | ÿ | ÿ | ÿ | ÿ | ÿ | ÿ | ÿ | ÿ | ||||||
| 0x3C0 | ÿ | | | | | | | | | | | | | | ||
| 0x3D0 | | | | | | | | | | | ||||||
| 0x3E0 | | | | | | | | | | | | | | | ||
| 0x3F0 | | | | | | | | | | | | | | | | |
| 0x400 | | | | | | | | c | u | s | ||||||
| 0x410 | t | o | m | f | o | n | t | | # | ø | | ø | ||||
| 0x420 | ø | ø | | w | ù | P | ù | < | ||||||||
| 0x430 | ÷ | ÷ | ÷ | ÷ | W | | | |||||||||
| 0x440 | | # | $ | % | & | ' | ( | ) | * | V | e | r | s | |||
| 0x450 | i | o | n | | 1 | . | 0 | C | u | s | t | o | m | | G | l |
| 0x460 | y | p | h | | F | o | n | t | C | u | s | t | o | m | c | m |
| 0x470 | o | s | t | u | ~ | | | | ||||||||
| 0x480 | | | ||||||||||||||
| 0x490 | - | |||||||||||||||
| 0x4A0 | w | ù | P | ù | < | ý | P | |||||||||
| 0x4B0 | ý | < | ÷ | * | ÷ | * | ø | ø | ||||||||
| 0x4C0 | $ | ü | | |||||||||||||
| 0x4D0 | | ù | P | ù | P | | | | | | | | $ | |||
| 0x4E0 | | 2 | | D | F | L | T | | l | a | t | n | | |||
| 0x4F0 | | | | | | ÿ | ÿ | | | | | l | i | |||
| 0x500 | g | a | | | | | | | | | | |||||
| 0x510 | | | | | | | | | | |||||||
| 0x520 | | | | | | | | | | |||||||
| 0x530 | | | | | | | | | | | | |||||
| 0x540 | | | | | | | | | | | | | | | | |
| 0x550 | | | | | | | | | ¨ | | — | — | — | — | ||
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
这些数字告诉了我们什么?
首先,是一些关于OpenType字体如何工作的东西。一个字体文件实际上是一个"表"的集合,每个都描述了字体的一个不同方面。有些包含了关于 字体的名字,license文本,谁创建了它等 的信息,而另一些则包含了metrics信息,如总体的字符高度是多少,字体中总共有多少个字母等等。一个字体中的所有表(而且这有很多),典型地只有一个表包含你所认为的实际的字母。在这个页面上的这个小字体中,那是"CFF"表(一个"compact font format"表)。看一下字库的字节码,我们可以辨认出(如果你知道如何读它的话),我们的字体占用了1372字节,而只有211个字节(hex值D3,看一下你是否能找到它)由CFF表占用。那...真的不是很多。那地球上的其它部分都是些什么呢?
OpenType描述每一件事
CFF表之于一个OpenType字库,如同一个字体之于书本:是必须的,但真的不是使一个字库变得特殊的部分。使得OpenType字库变得特殊的地方在于,它们描述了在你考虑把字母放在一起形成单词时,你可能想到的每一个方面。除了平淡无奇的"字母看起来的样子"这样的信息,OpenType字库还指定了字库中每个可用的字母的名字,字库实现了多少Unicode标准,什么样的水平和垂直metrics应用于哪个字母,在字库中精确地字母安排方式以便于快速地读出,应用的字库类别(它是一个fantasy字库吗?它是粗体face吗?它是固定宽度吗?等等等),打印机为了能够加载字库所需要的内存分配的种类,等,等,等。

比如,字库中最大的表是"name"表,它包含了所有的字符串,这些字符串描述了诸如字库名字,font family名字,字库的创建者,字库的版本,字库所应用的license(简单的),字库的版权拥有者,字库预览程序所使用的预览文本,及更多这类的事情。这个表总共519字节,几乎占了字库的一半。它之所以这么大的原因是,尽管现在的计算机不需要真地关心你所使用操作系统,但OpenType仍然"不得不"以"Macintosh"和"Windows"格式包含字符串,这真地意味着ASCII格式(它是一种7-bit字符串格式,每个字节一个字母)和UTF16(每个字母它使用两个字节,不幸地是对于那些ASCII中已有的字符也是这样,第一个字节总是0字节,因而它基本上是"填充了0的ASCII")。因此,一个像"Version 1.0"这样的字符串,它的11个字母(包括空格)以一个Macintosh字符串编码将占用11个字节,但由于它还需要以UTF16的形式记录,我们额外有一个"0V0e0r0si0o0n0 010.00"——每个实际的字母前面都有0字节——这意味着一个额外的22字节。如果我们不是不得不将数据编码两次,我们几乎可以不需要三分之二的表。尽管OpenType描述每一件事情很好,但有时它似乎有点过了。
当然,name表这么大的另一个原因不是因为它真的大,而是由于实际上字库本身是如此地小。它只包含了7个字母("c", "u", "s", "t", "o", "m", 和 "~"),因而实际的字库数据很小,但在一个普通的字库中,name表通常都比一个OpenType字库所具有的三个最重要的表小得多:cmap表,用于把你输入的字符映射为字库内部的ids,GSUB表,用于处理glyph替换,及GPOS表,用于处理glyph相互之间的位置。
=> cmap - 字符映射到一个字库
字库实际上不包含字母。这听起来有点怪异,但却不是。它们包含glyphs。字母'A'是一个glyph,符号'.'也是(the full top),变音符"^" (长音符号)也是。字库里有一些glyphs的实现,但没有其它的,这造成了一个问题:字库只是简单地在一个长的连续列表中编码了所有它们实现的glyphs,编号的glyph id 0, glyph id 1, glyph id 2,等等,因而当你输入字母'A'时,它常常有一个十进制码62,那个字母的glyph可能在字库的font-list-position 1中,或120,或17402。为了完成由"计算机所使用的"代码到"字库中所特别使用的"代码的转换,我们有了cmap,或者"字符到glyph映射",表。
cmap表实际是一个集合的集合。不是只有一种方式将外部的字符码映射为字库内的字符码,而是依赖于字库实现它的glyphs的分段(fragmented)或排序方式,有多种编码方案可以用。比如,如果字库是一种老式的256-字符字库,则一个cmap "format 0"是合适的,可被用于建模直接的256个不同的映射,每个字符一个。比如,要找到字母A的glyph id,你将简单地查找format0[62],其中62是字母'A'的数字编码。完成。
然而,如果字库建模了Unicode块 (而且Unicode具有*大量的*字符。上次统计超过一百万),而它只编码了那些中的一部分,实现的字符序列之间有间隔,它可能使用一个format 4或format 12子表。Format 4让你把实现的字符编码为连续代码的"段",从而编码代码25,26,27,28,29,43,44,45,46,47,120,121,122可以使用三个段,{25,29},{43,47}和{120,122}完成。一些额外的值被用于确保,尽管字符代码之间有间隔,但它们映射到的glyph ids是连续的,从而三个给定的段可能被映射到glyph ids {17,21},{22,26},{27,29}。
实际上当前有9种不同的子表格式可用(formats 0, 2, 4, 6, 8, 10, 12, 13, 和14),它们都提供了不同的方式来有效地编码具有特定属性的字符范围。附加,这是集合的集合的部分,你不是一定要只用一个子表来"解释"一个字库的字符。你可以对开始的256个字符使用使用一个format 0子表,为其余的两字节Unicode范围使用一个format 4子表,为其余的4字节Unicode范围使用一个format 12子表。为了使事情更有叙述性(descriptive),cmap表也会根据平台和语言提供线索(keyed),因而你可以给Macintosh字符代码弄一个子表,从一个特定的输入语言,到字库内的glyph ids,另外给Windows字符代码弄一个,从一个特定的输入语言,到字库内的glyph ids。

一个字库越完整,cmap表越大,cmap子表也是。
=> GPOS - glyph定位魔法
一个字库具有GPOS (及在老式的OpenType字库中"kern"表),可以确保字母被正确的定位;不管是就看起来的美观而言 (比如在"AV"中把一个V向A移近一点,以使它们之间看起来不会有"太多的"空白),还是要确保文本的实际正确,比如要通过结合base字母"o"和两个使它成为正确的字母所需要的组合字符(diacritic marks)来形成越南语的字母ở。
实际上GPOS表可以以相当多的不同方式执行这些(重)定位。它可以:调整一个单独的glyph的位置,调整一对glyphs的位置,附接(attach) cursive glyphs,附接一个combining mark到一个base glyph,附接一个combining mark到一个ligature,附接一个combining mark到另一个mark,在上下文中放置一个或多个glyphs,在链式 (chained)上下文中放置一个或多个gyphs。

=> GSUB - glyph替换魔法
一个字库可能也需要glyph替换,这正是用到GSUB表的地方。比如,一个使用了GSUB的字库可能包含两种不同的数字0到9的集合,一个集合用于"普通的输入",而另一个用于"历史上使用的版本(when historically used versions)"。在"从前"你将需要使用两个不同的字库,老式风格数字的字库应用于你的文本中的每个数字,但通过一个现代的OpenType字库,字库本身可以执行替换而你不需要担心是否所有的数字都被正确地styled了。然而,GSUB表也可以被用于以单个或多个字母替换单个的字母,或多个字母,而且它可以被用于根据字母在一个单词中的位置来改变它的外观。那可能听起来有点怪异,但是阿拉伯语对于每一个字母都具有4种不同的形状,依赖于它是单独使用(比如,处于隔离状态如引用字母"A"),用于单词的起始处,中间或结尾处。试着通过一系列不同的字库为一个单词中的每个位置做到那一点,则祝好运。

=> 做那些事的代价有多少?
我们的小字库只有一个真实的字母,因而它不使用GPOS表(我们想要重定位什么呢?),但用于映射七个字母和"c", "u", "s", "t", "o", "m",和"~"的cmap占用了106个字节 (多亏了高度碎片化的字符代码),而GSUB表,只用于把字符串"custom"替换为"~"的glyph,占用了至少98个字节。那几乎是CFF表大小的一半了。我们知道了cmap表为什么如此的大 (我们实际实现的字母越多,来填充这个字库所清晰地具有的间隔,则比例将下降),但为什么GSUB表也是如此的大呢?
Scripts,features,lookups,噢,我的天哪!
现代字库的一个更重要的方面是,它们不仅仅为了"styling字母",它们还styling完整的字符串,针对特定的scripts,在特定的上下文中,以这样一种方式,即 使一个字库指定在不同的的scripts和不同的上下文中做什么。你可能想你实际需要在那个字库中指定的是一个字处理器,没有字处理器哪里能自动地完整地做那些。
比如,中文和日文都使用了Unicode定义的字符集"CJK Unified Ideographs"。然而,尽管子本质上它们使用相同的字符,但在这两种语言中它们看起来却不总是相同。因此,一个现代的OpenType字库可能包含了指令,在字库被用于一个中文script上下文时应用某一规则,在用于一个日文script上下文时使用其它规则。甚至是在相同的script,我们也可能有以不同的方式style文本的需要。按照亚洲的语言,中文和日文都可以水平 (自左向右,一行在前一行的下面) 书写,或竖直书写 (自上向下,一行在前一行的左边)。依赖于字库所有被使用的书写模式,字库的字符metrics将是不同的。因而对于GSUB和GPOS表,思想是"应用于styling的东西"被编码为"lookups" (比如,GSUB lookup 4编码了如何把多个字母转为一个单独的其它字母,比如把字母序列"custom"转为一个矩形),而且"features"可以链接一个或多个lookups;比如features被标记为"liga",编码了"字库中有一些ligatures"的概念,然后指向可被用于特定的实际替换的lookups。最后,字库将有一个所支持的script的列表 (包括一个"DFLT" script在没有其它东西应用时使用),每个都表示一个或多个features应该被激活。比如,你可能想要为English scripts激活一些小型大写字母替换,但不想为Greek和Coptic激活这些。
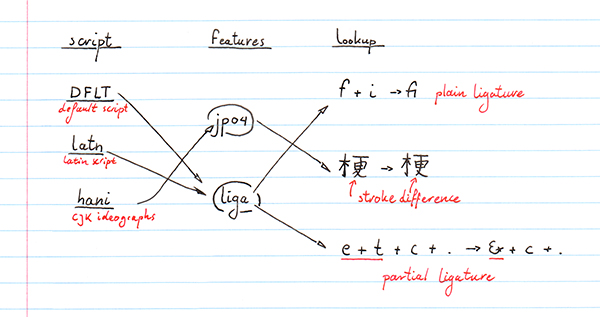
在这个简单的字库中,只是把单词"custom"替换为了我们的小方框,我们需要定义一个GSUB lookup,具有一个称为"liga"的feature指向那个lookup,一个featureset只包含了那个单独的feature,及两个scripts——DFLT script及一个"latn" script,它们涵盖了大多数的西方书写字符——他们都指向相同的featureset。很清晰地是,script/feature/lookup的概念相当有用,但也相当复杂,对于像 一个单独的替换规则 这样简单的东西,可能有点杀鸡用牛刀的感觉。
TrueType还是OpenType?苹果还是橘子。
OpenType字库另一个值得考量的地方是要使用哪种outline描述。你可能听说过TrueType字库,特别是对比OpenType字库,但实际上TrueType之于OpenType就如同Ford或Porsche之于轿车一样:OpenType是"事物",而TrueType只是OpenType字库的一种类型。其它主要的还有"Type 2"或"CFF"类型。
不同之处在哪里呢?历史上TrueType是Microsoft建模outline形状的方式,它是一种描述绘制字母所需的线段和曲线相对直观的方式。用它定义形状比较容易,但不幸地是,它的简单性有一个代价:它也不是一种描述outline非常高效的方式。另一方面,CFF使用了Adobe的"type 2 charstrings",具有一个非常丰富的指令集来描述outline图形。这些东西在描述富形状方面极其高效,但它们也可能复杂地可怕。通常如果你的字库建模相对较少的字符,或它们的形状不需要特别多的复杂outline图形,则TrueType类型的OpenType字库是一个好主意。然而,对于那些字符集非常大(比如东亚字库)或具有非常细致的图形字符的字库,CFF种类的OpenType字库可能是一个更好的选择。
尽管在这个页面上我们的字库使用了一种相对简单的图形,我们仍然使用了一个CFF字库。为什么?因为相对于我们使用TrueType outlines而言,这样做让我们可以看到更多字库如何工作的东西。实际上,TrutType数据主要只是一个outline指令的表,有另一个表来解析字符代码为"在outline块中的哪个位置是这个字符的数据" (分别是"glyf"和"loca"表),CFF块本身是一个完整的字库。尽管它从没有被设计为独立使用(总是在一个包含了所有meta数据的wrapper内),一个CFF块几乎具有一切使它有资格成为一个字库的东西:它知道它支持哪种字符,它有它们的outline,它有关于字符metrics的通用metadata、字库名字和版本,甚至是它是一个细体或粗体字库。那使它看起来有趣得多,Type 2 charstring指令不仅用于outlines,它几乎是一种图形的编程语言。现在想起来,是"几乎"。Type 2 charstrings是真的,真的非常强大。
掀起CFF的盖头来
让我们更近距离地看一下CFF表,由于它本身是一个完整的字库,而不像OpenType字库那样描述尽可能少的东西以确保没有浪费空间。结合所有已经存放在OpenType表中的metadata,这可能是一个非常好的胜利的结合。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 01 | 00 | 04 | 01 | 00 | 01 | 01 | 01 | 0B | 63 | 75 | 73 | 74 | 6F | 6D | 66 |
| 0x10 | 6F | 6E | 74 | 00 | 01 | 01 | 01 | 23 | F8 | 1B | 00 | F8 | 1C | 02 | F8 | 1D |
| 0x20 | 03 | F8 | 19 | 04 | 8C | 0D | 9F | 77 | F9 | 50 | F9 | 3C | 05 | F7 | 07 | 0F |
| 0x30 | F7 | 16 | 10 | F7 | 1F | 11 | 9B | F7 | 57 | 12 | 00 | 0A | 01 | 01 | 0C | 1D |
| 0x40 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 2A | 56 | 65 | 72 | 73 | 69 | 6F | 6E | 20 |
| 0x50 | 31 | 2E | 30 | 43 | 75 | 73 | 74 | 6F | 6D | 20 | 47 | 6C | 79 | 70 | 68 | 20 |
| 0x60 | 46 | 6F | 6E | 74 | 43 | 75 | 73 | 74 | 6F | 6D | 63 | 6D | 6F | 73 | 74 | 75 |
| 0x70 | 7E | 00 | 00 | 00 | 01 | 8A | 01 | 8B | 01 | 8C | 01 | 8D | 01 | 8E | 01 | 8F |
| 0x80 | 01 | 90 | 00 | 07 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 00 | 08 | 01 | 01 | 02 |
| 0x90 | 03 | 04 | 05 | 06 | 07 | 08 | 2D | 0E | 0E | 0E | 0E | 0E | 0E | 0E | 9F | 77 |
| 0xA0 | 15 | 8B | F9 | 50 | 05 | F9 | 3C | 8B | 05 | 8B | FD | 50 | 05 | FD | 3C | 8B |
| 0xB0 | 05 | F7 | 2A | F7 | 2A | 15 | F8 | 10 | 8B | 05 | 8B | F8 | 24 | 05 | FC | 10 |
| 0xC0 | 8B | 05 | 0E | 8B | 8B | 06 | 8B | 8B | 08 | 95 | 0A | 95 | 0B | F9 | 50 | 14 |
| 0xD0 | F9 | 50 | 15 | — | — | — | — | — | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | | | | c | u | s | t | o | m | f | ||||||
| 0x10 | o | n | t | | # | ø | | ø | ø | |||||||
| 0x20 | ø | | w | ù | P | ù | < | ÷ | ||||||||
| 0x30 | ÷ | ÷ | ÷ | W | | | | |||||||||
| 0x40 | # | $ | % | & | ' | ( | ) | * | V | e | r | s | i | o | n | |
| 0x50 | 1 | . | 0 | C | u | s | t | o | m | | G | l | y | p | h | |
| 0x60 | F | o | n | t | C | u | s | t | o | m | c | m | o | s | t | u |
| 0x70 | ~ | | | | ||||||||||||
| 0x80 | | | ||||||||||||||
| 0x90 | - | w | ||||||||||||||
| 0xA0 | ù | P | ù | < | ý | P | ý | < | ||||||||
| 0xB0 | ÷ | * | ÷ | * | ø | ø | $ | ü | ||||||||
| 0xC0 | | | ù | P | ||||||||||||
| 0xD0 | ù | P | — | — | — | — | — | — | — | — | — | — | — | — | — | |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
每个CFF定义由多个固定的段组成,每个具有合理地尽可能少的字节:
1. Header的所有4个字节:
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 01 | 00 | 04 | 01 | — | — | — | — | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- 主版本号 1(01)
- 次版本号 0 (00)
- "header的4字节" (04,它有点傻,v1.0的CFF header具有固定的长度),而且
- '1'表示在这个块中的偏移,它 - 对于大多数部分 - 使用适合1个字节(01)的值。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 01 | 01 | 01 | 0B | 63 | 75 | 73 | 74 | 6F | 6D | 66 | 6F | 6E | 74 | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- 1个name字符串 (00 01),
- 在这个段中offsets使用了1个字节 (01),
- 到独立的name字符串的偏移量(第一个字符串是01,0B是列表的终点),而且
- 第一个name字符串:"cutsomfont",ASCII编码的。
3. 主"DICT"结构。它包含了一些关于CFF字库的metadata,及一些指向CFF数据中的"charset","encoding","charstrings"和"private DICTs"的指针。你问这些是什么?随后就会说明。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 01 | 01 | 01 | 23 | F8 | 1B | 00 | F8 | 1C | 02 | F8 | 1D | 03 | F8 | 19 |
| 0x10 | 04 | 8C | 0D | 9F | 77 | F9 | 50 | F9 | 3C | 05 | F7 | 07 | 0F | F7 | 16 | 10 |
| 0x20 | F7 | 1F | 11 | 9B | F7 | 57 | 12 | — | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- 1 dictionary (00 01)
- 在这个段中offset使用一个字节 (01)
- offsets to individual dictionaries (01 for first dictionary, 23 for end of list)到独立的dictionaries的offset (第一个dictionary是01,23是列表的最后一个)
- 字节编码的dictionary数据 (在CFF文档中解释)
4. "string"索引 (index),它是仅有的有字符串出现的地方 (除了name索引(index)外)。所有使用字符串的东西指向这个段中的索引。还有390个"标准-定义的"字符串,但都没有被编码进这个字库。那意味着首个定制字符串在这个index中的索引为391,第二个是392,等等等。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 0A | 01 | 01 | 0C | 1D | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 2A | 56 | 65 |
| 0x10 | 72 | 73 | 69 | 6F | 6E | 20 | 31 | 2E | 30 | 43 | 75 | 73 | 74 | 6F | 6D | 20 |
| 0x20 | 47 | 6C | 79 | 70 | 68 | 20 | 46 | 6F | 6E | 74 | 43 | 75 | 73 | 74 | 6F | 6D |
| 0x30 | 63 | 6D | 6F | 73 | 74 | 75 | 7E | — | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- 10个字符串 (0A),
- 这个段中的offsets使用了一个字节 (01),
- 到独立的dictionaries的偏移量(01, 0C, 1D, 23, 24, 25, 26, 27, 28, 29; 2A是列表的结尾),及
- 我们的10个字符串:"Version 1.0", "Custom Glyph Font", "Custom", "c", "m", "o", s", "t", "u", 及"~",它们都以ASCII编码。
5. 全局可访问"subroutines"的列表。Subroutines是CFF字库的真正强大之处之一:所有的outline定义可以包含指令从全局subroutines列表获取"一些数据",并在有"fetch"
指令的地方把它插入outline的定义。那可能发生在任何时间。在一个行(line)指令的中间?是。甚至在我们开始之前?当然。Subroutines是一种从字库获取所有charstrings的方式,go "which of them share any substrings that are more than two or three bytes long", and then rip those out, store them as a subroutine instead, and replace them in the original charstrings with "drop into subroutine XYZ here"。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 00 | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- There are 0 global subroutines (00 00)
6. 然后是"charset"。这与"cmap"表有点像,除了它不操心平台或一种编码或任何那样的东西 (事实上,编码是在后面的一节描述的)。charset使你能够说明这个字库支持哪些字符。甚至有一些是CFF规范简单地预定义的,因而如果你实现了所有那些字符,你甚至都不需要在这个表中存储任何东西,除了,例如"这个字库使用预定义字符集2"这样。很紧凑!
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 01 | 8A | 01 | 8B | 01 | 8C | 01 | 8D | 01 | 8E | 01 | 8F | 01 | 90 | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- charset format 0 (00)
- The list of implemented glyphs, taking note that there are 390 predefined strings in CFF. Instead of using those, we're going to point to our own, so that for instance "c" is string 390 + 4 (because 'c' is the 4th string in the string index, listed above). Each glyph is references by string ID, and each id is stored as a two-byte value, so 'c', which has id 394, is stored as (01 8A).
7. 在charset之后是"encoding",它给了每个被编码的字符名字。当然,实际的字符串位于string index中,因而典型地这个部分看起来像"我有X个字母。它们的名字是:396,397,398,399,400,401,...",它们真得很紧凑。每个字母名字一个数字。而且如果你使用了一个预定义的字符集,你甚至都不需要列出这些名字,因为字符已经基于一个预定义的列表,以 使你找到它们的名字更简单的方式排列了。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 07 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- There are seven characters that need to map to internal glyph ids (00 07)
- The first glyph from the charset will have internal id 1 (01), the second will have id 2 (02), etc.
8. 但是:不是必须的,由于我们可以访问subroutines。更精确地说,这是一个引擎开始查找一个字符的outline的地方,而且它找到的数据可能将它导到不同的地方。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 00 | 08 | 01 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 2D | 0E | 0E | 0E | 0E |
| 0x10 | 0E | 0E | 0E | 9F | 77 | 15 | 8B | F9 | 50 | 05 | F9 | 3C | 8B | 05 | 8B | FD |
| 0x20 | 50 | 05 | FD | 3C | 8B | 05 | F7 | 2A | F7 | 2A | 15 | F8 | 10 | 8B | 05 | 8B |
| 0x30 | F8 | 24 | 05 | FC | 10 | 8B | 05 | 0E | — | — | — | — | — | — | — | — |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- There are 8 outlines defined (00 08)
- We'll be using 1 byte for offsets (01, because this is very little data)
- The offsets to the outlines per glyph. For glyph zero (.notdef), offset 1 (01), and 'c', 'm', 'o', 's', 't' and 'u' are all 1 byte further, because they'll all implement the same thing as the .notdef character. Only '~' has a "real" outline, starting at offset 8 (08) and ending at offset 45 (2D)
- eight outlines, of which the first seven are basically blank (0E). The eight outline is a Type2 charstring for a rectangle with another, smaller, rectangle cutout.
9. 最后,我们发现了"private dict"段。这里放了更多它所属的字符的集合特有的metadata,及只有那些字符可访问的"本地的"subroutines。它非常有意义,比如,要为Latin字符包含不同的subroutines集合,及为东亚字符包含另一个private dict。如果我们想要,我们可以定义一个CFF字库为一个多段(multiple-sectioned)的字库,使用"font dicts",每个font dict都指向它自己的charstrings和private dict,放置它自己的subroutines。Private dicts也描述更老的,Type 1 features,比如蓝区 (Blue zones),它也用于对齐目的。如果你需要结合多个charstrings,且你有蓝区 (blue zones),各种各样的极其精确的数学可能发生的事情。
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x0 | 8B | 8B | 06 | 8B | 8B | 08 | 95 | 0A | 95 | 0B | F9 | 50 | 14 | F9 | 50 | 15 |
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- three bytes to say the "blue values" are [0, 0] (8B 8B, 06 is the 'blue values' identifier),
- three bytes to say the "family blues" are also [0, 0] (8B 8B, 08 is the 'family' identifier),
- standard hw value of 10 (95, 0A is the StdHW identifier),
- standard vw value of 10 (95, 0B is the StdVW identifier),
- a default width value of 700 (F9 50, 14 is the default width identifier), and
- a nominal width value of 700 (F9 50, 15 is the nominal width identifier).
所有的这些数字使用Adboe的"数字"编码,它是一个可变的字节编码,它用一个字节编码[-107,107],用2个字节编码[-1131,1131](明显的不包含1个字节的范围),用3字节编码[-32768,32767],及5字节的[-2³¹, 2³¹⁻¹]。
但这决不是组织这些数据仅有的方式
The CFF specification in fact allows for a number of variations here that will efficiently encode different kinds of fonts (e.g. fonts that conform to a default character set, freeform fonts like this page's tiny font, huge unicode-spanning fonts, etc.) and lets you be either very verbose in terms of how accurately your outlines need to be rendered depending on the point size they're being rendered at. Effectively, CFF is an elaborate way to organise everything you need to make sure the Type 2 charstrings get rendered exactly the way the typeface designer(s) and font engineer(s) meant them to be rendered.
实际上CFF规范在这里允许非常多的高效编码不同种类的字库的变更 (比如,与一个默认的字符集一致的字库,像这个页面的小字库一样的自由组织字库,巨大的unicode-spanning字库,等等),及使你
Did I mention that Type 2 charstrings also let you write PostScript inside of them? Because just in case the designers and engineers didn't have enough power yet, you can also say "okay, you know what, we need to do things that Type2 can't do on its own. Here is a program that will actually do that thing. Run it when you read in this character". There are of course some safeguards here: the PostScript instructions that you can use don't let you do things like open files, it's just for manipulating numbers, and you can't do infinite recursion, your program stack can only contain 48 "things" before it's full, but it does mean you can do an insane amount of plotting instructions simply by knowing how to implement them in PostScript. Make the PostScript program a global subroutine, and now all your characters can make use of it. Fonts really are amazingly rich things.
我们的字体作为结构化的对象
We can also look at the font as a structured object, similar to a JSON or C "struct". While this isn't necessarily a very useful view, it's actually really useful when you're debugging a font. I'm note quite sure how to make this view work for you yet, but I'm working on it!
Done。
原文。















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









