







目录
5.3 使用 qemu-img 和 qemu-kvm 命令行方式安装
5.4 通过 OpenStack Nova 使用 libvirt API 通过编程方式来创建虚机 (后面会介绍)
1.1 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
1.2. 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
2.3 KSM (Kernel SamePage Merging 或者 Kernel Shared Memory)
2.4 KVM Huge Page Backed Memory (巨页内存技术)
2. 准虚拟化 (Para-virtualizaiton) I/O 驱动 virtio
2.3 使用 virtio 设备 (以 virtio-net 为例)
2.4 vhost-net (kernel-level virtio server)
2.7 RedHat 的 多队列 Virtio (multi-queue)
1. PCI/PCI-E 设备直接分配给虚机 (PCI Pass-through)
1.2 在 RedHat Linux 6 上使用 virt-manger 分配一个光纤卡给虚机
1.3 在 RedHat Linux 6 上使用 qemu-kvm 分配一个光纤卡给虚机
3.3 Virtio 和 Pass-Through 的详细比较
(6):Nova 通过 libvirt 管理 QEMU/KVM 虚机
2.2 添加 volume 到虚机 (nova volume-attach)
2.3 添加连接到新的网络的 interface 给虚机 (nova interface-attach)
(7):使用 libvirt 做 QEMU/KVM 快照和 Nova 实例的快照
(8):使用 libvirt 迁移 QEMU/KVM 虚机和 Nova 虚机
2. OpenStack Nova QEMU/KVM 实例动态迁移的环境配置
3.1 静态迁移(migrate 或者 resize 不使用新的 flavor)
(1):简介及安装
1. KVM 介绍
1.0 虚拟化简史

其中,KVM 全称是 基于内核的虚拟机(Kernel-based Virtual Machine),它是一个 Linux 的一个内核模块,该内核模块使得 Linux 变成了一个 Hypervisor:
- 它由 Quramnet 开发,该公司于 2008年被 Red Hat 收购。
- 它支持 x86 (32 and 64 位), s390, Powerpc 等 CPU。
- 它从 Linux 2.6.20 起就作为一模块被包含在 Linux 内核中。
- 它需要支持虚拟化扩展的 CPU。
- 它是完全开源的。官网。
本文介绍的是基于 X86 CPU 的 KVM。
1.1 KVM 架构
KVM 是基于虚拟化扩展(Intel VT 或者 AMD-V)的 X86 硬件的开源的 Linux 原生的全虚拟化解决方案。KVM 中,虚拟机被实现为常规的 Linux 进程,由标准 Linux 调度程序进行调度;虚机的每个虚拟 CPU 被实现为一个常规的 Linux 进程。这使得 KMV 能够使用 Linux 内核的已有功能。
但是,KVM 本身不执行任何硬件模拟,需要客户空间程序通过 /dev/kvm 接口设置一个客户机虚拟服务器的地址空间,向它提供模拟的 I/O,并将它的视频显示映射回宿主的显示屏。目前这个应用程序是 QEMU。
Linux 上的用户空间、内核空间和虚机:
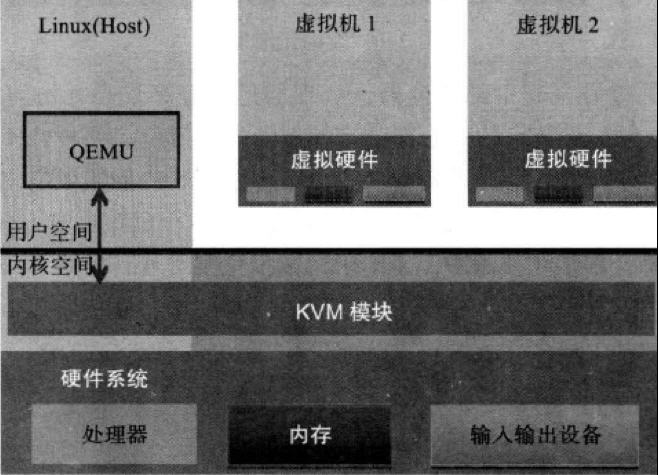
- Guest:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
- KVM:运行在内核空间,提供CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
- QEMU:修改过的为 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
KVM 是实现拦截虚机的 I/O 请求的原理:
现代 CPU 本身了对特殊指令的截获和重定向的硬件支持,甚至新的硬件会提供额外的资源来帮助软件实现对关键硬件资源的虚拟化从而提高性能。以 X86 平台为例,支持虚拟化技术的 CPU 带有特别优化过的指令集来控制虚拟化过程。通过这些指令集,VMM 很容易将客户机置于一种受限制的模式下运行,一旦客户机视图访问物理资源,硬件会暂停客户机的运行,将控制权交回给 VMM 处理。VMM 还可以利用硬件的虚级化增强机制,将客户机在受限模式下对一些特定资源的访问,完全由硬件重定向到 VMM 指定的虚拟资源,整个过程不需要暂停客户机的运行和 VMM 的参与。由于虚拟化硬件提供全新的架构,支持操作系统直接在上面运行,无需进行二进制转换,减少了相关的性能开销,极大简化了VMM的设计,使得VMM性能更加强大。从 2005 年开始,Intel 在其处理器产品线中推广 Intel Virtualization Technology 即 IntelVT 技术。
QEMU-KVM:
其实 QEMU 原本不是 KVM 的一部分,它自己就是一个纯软件实现的虚拟化系统,所以其性能低下。但是,QEMU 代码中包含整套的虚拟机实现,包括处理器虚拟化,内存虚拟化,以及 KVM需要使用到的虚拟设备模拟(网卡、显卡、存储控制器和硬盘等)。
为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。遇到虚机进行 I/O 操作,KVM 会从上次的系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。
从 QEMU 的角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行说依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
KVM:
KVM 内核模块在运行时按需加载进入内核空间运行。KVM 本身不执行任何设备模拟,需要 QEMU 通过 /dev/kvm 接口设置一个 GUEST OS 的地址空间,向它提供模拟的 I/O 设备,并将它的视频显示映射回宿主机的显示屏。它是KVM 虚机的核心部分,其主要功能是初始化 CPU 硬件,打开虚拟化模式,然后将虚拟客户机运行在虚拟机模式下,并对虚机的运行提供一定的支持。以在 Intel 上运行为例,KVM 模块被加载的时候,它:
- 首先初始化内部的数据结构;
- 做好准备后,KVM 模块检测当前的 CPU,然后打开 CPU 控制及存取 CR4 的虚拟化模式开关,并通过执行 VMXON 指令将宿主操作系统置于虚拟化模式的根模式;
- 最后,KVM 模块创建特殊设备文件 /dev/kvm 并等待来自用户空间的指令。
接下来的虚机的创建和运行将是 QEMU 和 KVM 相互配合的过程。两者的通信接口主要是一系列针对特殊设备文件 dev/kvm 的 IOCTL 调用。其中最重要的是创建虚机。它可以理解成KVM 为了某个特定的虚机创建对应的内核数据结构,同时,KVM 返回一个文件句柄来代表所创建的虚机。
针对该句柄的调用可以对虚机做相应地管理,比如创建用户空间虚拟地址和客户机物理地址、真实物理地址之间的映射关系,再比如创建多个 vCPU。KVM 为每一个 vCPU 生成对应的文件句柄,对其相应地 IOCTL 调用,就可以对vCPU进行管理。其中最重要的就是“执行虚拟处理器”。通过它,虚机在 KVM 的支持下,被置于虚拟化模式的非根模式下,开始执行二进制指令。在非根模式下,所有敏感的二进制指令都被CPU捕捉到,CPU 在保存现场之后自动切换到根模式,由 KVM 决定如何处理。
除了 CPU 的虚拟化,内存虚拟化也由 KVM 实现。实际上,内存虚拟化往往是一个虚机实现中最复杂的部分。CPU 中的内存管理单元 MMU 是通过页表的形式将程序运行的虚拟地址转换成实际物理地址。在虚拟机模式下,MMU 的页表则必须在一次查询的时候完成两次地址转换。因为除了将客户机程序的虚拟地址转换了客户机的物理地址外,还要将客户机物理地址转化成真实物理地址。
2. KVM 的功能列表
KVM 所支持的功能包括:
- 支持CPU 和 memory 超分(Overcommit)
- 支持半虚拟化I/O (virtio)
- 支持热插拔 (cpu,块设备、网络设备等)
- 支持对称多处理(Symmetric Multi-Processing,缩写为 SMP )
- 支持实时迁移(Live Migration)
- 支持 PCI 设备直接分配和 单根I/O 虚拟化 (SR-IOV)
- 支持 内核同页合并 (KSM )
- 支持 NUMA (Non-Uniform Memory Access,非一致存储访问结构 )
3. KVM 工具集合
- libvirt:操作和管理KVM虚机的虚拟化 API,使用 C 语言编写,可以由 Python,Ruby, Perl, PHP, Java 等语言调用。可以操作包括 KVM,vmware,XEN,Hyper-v, LXC 等 Hypervisor。
- Virsh:基于 libvirt 的 命令行工具 (CLI)
- Virt-Manager:基于 libvirt 的 GUI 工具
- virt-v2v:虚机格式迁移工具
- virt-* 工具:包括 Virt-install (创建KVM虚机的命令行工具), Virt-viewer (连接到虚机屏幕的工具),Virt-clone(虚机克隆工具),virt-top 等
- sVirt:安全工具
4. RedHat Linux KVM 安装
RedHat 有两款产品提供 KVM 虚拟化:
1. Red Hat Enterprise Linux:适用于小的环境,提供数目较少的KVM虚机。最新的版本包括 6.5 和 7.0.
2. Red Hat Enterprise Virtualization (RHEV):提供企业规模的KVM虚拟化环境,包括更简单的管理、HA,性能优化和其它高级功能。最新的版本是 3.0.
RedHat Linux KVM:
- KVM 由 libvirt API 和基于该 API的一组工具进行管理和控制。
- KVM 支持系统资源超分,包括内存和CPU的超分。RedHat Linux 最多支持物理 CPU 内核总数的10倍数目的虚拟CPU,但是不支持在一个虚机上分配超过物理CPU内核总数的虚拟CPU。
- 支持 KSM (Kenerl Same-page Merging 内核同页合并)
RedHat Linux KVM 有如下两种安装方式:
4.1 在安装 RedHat Linux 时安装 KVM
选择安装类型为 Virtualizaiton Host :

可以选择具体的 KVM 客户端、平台和工具:

4.2 在已有的 RedHat Linux 中安装 KVM
这种安装方式要求该系统已经被注册,否则会报错:
-
[root@rh65 ~]# yum install qemu-kvm qemu-img -
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager -
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register. -
Setting up Install Process -
Nothing to do
你至少需要安装 qemu-kvm qemu-img 这两个包。
# yum install qemu-kvm qemu-img你还可以安装其它工具包:
# yum install virt-manager libvirt libvirt-python python-virtinst libvirt-client4.3 QEMU/KVM 代码下载编译安装
4.3.1 QEMU/KVM 的代码结构
QEMU/KVM 的代码包括几个部分:
(1)KVM 内核模块是 Linux 内核的一部分。通常 Linux 比较新的发行版(2.6.20+)都包含了 KVM 内核,也可以从这里得到。比如在我的RedHat 6.5 上:
-
[root@rh65 isoimages]# uname -r 2.6.32-431.el6.x86_64 -
[root@rh65 isoimages]# modprobe -l | grep kvm -
kernel/arch/x86/kvm/kvm.ko -
kernel/arch/x86/kvm/kvm-intel.ko -
kernel/arch/x86/kvm/kvm-amd.ko
(2)用户空间的工具即 qemu-kvm。qemu-kvm 是 KVM 项目从 QEMU 新拉出的一个分支(看这篇文章)。在 QEMU 1.3 版本之前,QEMU 和 QEMU-KVM 是有区别的,但是从 2012 年底 GA 的 QEMU 1.3 版本开始,两者就完全一样了。
(3)Linux Guest OS virtio 驱动,也是较新的Linux 内核的一部分了。
(4)Windows Guest OS virtio 驱动,可以从这里下载。
4.3.2 安装 QEMU
RedHat 6.5 上自带的 QEMU 太老,0.12.0 版本,最新版本都到了 2.* 了。
(1). 参考 这篇文章,将 RedHat 6.5 的 ISO 文件当作本地源
-
mount -o loop soft/rhel-server-6.4-x86_64-dvd.iso /mnt/rhel6/ -
vim /etc/fstab -
=> /root/isoimages/soft/RHEL6.5-20131111.0-Server-x86_64-DVD1.iso /mnt/rhel6 iso9660 ro,loop
[root@rh65 qemu-2.3.0]# cat /etc/yum.repos.d/local.repo
[local]
name=local
baseurl=file:///mnt/rhel6/
enabled=1
gpgcjeck=0
| 1 | yum clean all |
(2). 安装依赖包包
-
yum install gcc -
yum install autoconf -
yum install autoconf automake libtool -
yum install -y glib* yum install zlib*
(3). 从 http://wiki.qemu.org/Download 下载代码,上传到我的编译环境 RedHat 6.5.
-
tar -jzvf qemu-2.3.0.tar.bz2 -
cd qemu-2.3.0 ./configure -
make -j 4 make install
(4). 安装完成
-
[root@rh65 qemu-2.3.0]# /usr/local/bin/qemu-x86_64 -version -
qemu-x86_64 version 2.3.0, Copyright (c) 2003-2008 Fabrice Bellard
(5). 为方便起见,创建一个link
ln -s /usr/bin/qemu-system-x86_64 /usr/bin/qemu-kvm4.3.3 安装 libvirt
可以从 libvirt 官网下载安装包。最新的版本是 0.10.2.
5. 创建 KVM 虚机的几种方式
5.1 使用 virt-install 命令
virt-install \ --name=guest1-rhel5-64 \ --file=/var/lib/libvirt/images/guest1-rhel5-64.dsk \ --file-size=8 \ --nonsparse --graphics spice \ --vcpus=2 --ram=2048 \ --location=http://example1.com/installation_tree/RHEL5.6-Serverx86_64/os \ --network bridge=br0 \ --os-type=linux \ --os-variant=rhel5.45.2 使用 virt-manager 工具


使用 VMM GUI 创建的虚机的xml 定义文件在 /etc/libvirt/qemu/ 目录中。
5.3 使用 qemu-img 和 qemu-kvm 命令行方式安装
(1)创建一个空的qcow2格式的镜像文件
qemu-img create -f qcow2 windows-master.qcow2 10G(2)启动一个虚机,将系统安装盘挂到 cdrom,安装操作系统
qemu-kvm -hda windows-master.qcow2 -m 512 -boot d -cdrom /home/user/isos/en_winxp_pro_with_sp2.iso(3)现在你就拥有了一个带操作系统的镜像文件。你可以以它为模板创建新的镜像文件。使用模板的好处是,它会被设置为只读所以可以免于破坏。
qemu-img create -b windows-master.qcow2 -f qcow2 windows-clone.qcow2(4)你可以在新的镜像文件上启动虚机了
qemu-kvm -hda windows-clone.qcow2 -m 4005.4 通过 OpenStack Nova 使用 libvirt API 通过编程方式来创建虚机 (后面会介绍)
(2):CPU 和内存虚拟化
1. 为什么需要 CPU 虚拟化
X86 操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件。x86 架构提供四个特权级别给操作系统和应用程序来访问硬件。 Ring 是指 CPU 的运行级别,Ring 0是最高级别,Ring1次之,Ring2更次之…… 就 Linux+x86 来说,
- 操作系统(内核)需要直接访问硬件和内存,因此它的代码需要运行在最高运行级别 Ring0上,这样它可以使用特权指令,控制中断、修改页表、访问设备等等。
- 应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。
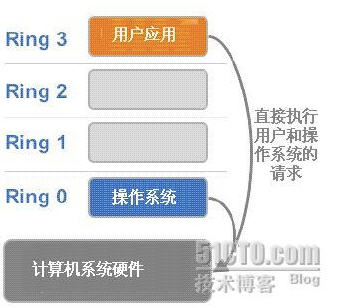
那么,虚拟化在这里就遇到了一个难题,因为宿主操作系统是工作在 ring0 的,客户操作系统就不能也在 ring0 了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,但是没有执行权限是会出错的。所以这时候虚拟机管理程序(VMM)需要避免这件事情发生。 虚机怎么通过 VMM 实现 Guest CPU 对硬件的访问,根据其原理不同有三种实现技术:
1. 全虚拟化
2. 半虚拟化
3. 硬件辅助的虚拟化
1.1 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
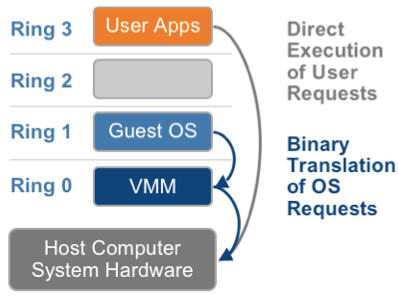
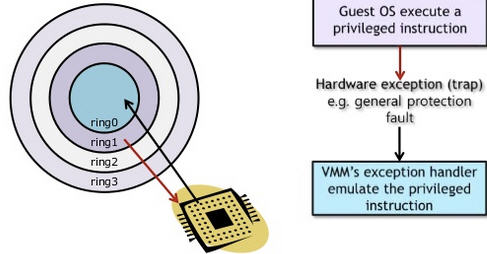
客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
异常 “捕获(trap)-翻译(handle)-模拟(emulate)” 过程:
1.2. 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
半虚拟化的思想就是,修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor 同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。
这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。

1.3. 硬件辅助的全虚拟化
2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了。 Intel 引入了 Intel-VT (Virtualization Technology)技术。 这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 共 4 个运行级别。这样,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。
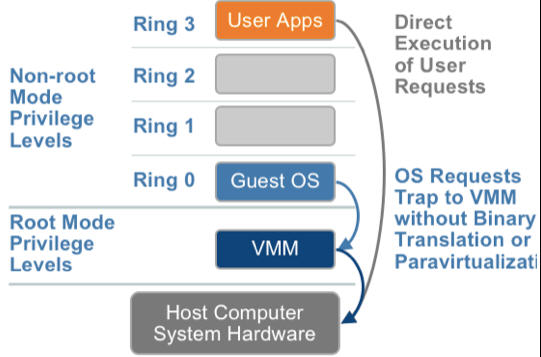
而且两种操作模式可以互相转换。运行在 VMX root operation 模式下的 VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。Guest OS 运行过程中遇到需要 VMM 处理的事件,例如外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行,这种转换称为 VM exit。VMX root operation 模式下软件的行为与在没有 VT-x 技术的处理器上的行为基本一致;而VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。
也就说,硬件这层就做了些区分,这样全虚拟化下,那些靠“捕获异常-翻译-模拟”的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势。
|
| 利用二进制翻译的全虚拟化 | 硬件辅助虚拟化 | 操作系统协助/半虚拟化 |
| 实现技术 | BT和直接执行 | 遇到特权指令转到root模式执行 | Hypercall |
| 客户操作系统修改/兼容性 | 无需修改客户操作系统,最佳兼容性 | 无需修改客户操作系统,最佳兼容性 | 客户操作系统需要修改来支持hypercall,因此它不能运行在物理硬件本身或其他的hypervisor上,兼容性差,不支持Windows |
| 性能 | 差 | 全虚拟化下,CPU需要在两种模式之间切换,带来性能开销;但是,其性能在逐渐逼近半虚拟化。 | 好。半虚拟化下CPU性能开销几乎为0,虚机的性能接近于物理机。 |
| 应用厂商 | VMware Workstation/QEMU/Virtual PC | VMware ESXi/Microsoft Hyper-V/Xen 3.0/KVM | Xen |
2. KVM CPU 虚拟化
KVM 是基于CPU 辅助的全虚拟化方案,它需要CPU虚拟化特性的支持。
2.1. CPU 物理特性
这个命令查看主机上的CPU 物理情况:
-
[s1@rh65 ~]$ numactl --hardware -
available: 2 nodes (0-1) //2颗CPU node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17 //这颗 CPU 有8个内核 node 0 size: 12276 MB -
node 0 free: 7060 MB -
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23 node 1 size: 8192 MB -
node 1 free: 6773 MB -
node distances: -
node 0 1 0: 10 21 1: 21 10
要支持 KVM, Intel CPU 的 vmx 或者 AMD CPU 的 svm 扩展必须生效了:
-
[root@rh65 s1]# egrep "(vmx|svm)" /proc/cpuinfo -
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 popcnt aes lahf_lm arat epb dts tpr_shadow vnmi flexpriority ept vpid
2.2 多 CPU 服务器架构:SMP,NMP,NUMA
从系统架构来看,目前的商用服务器大体可以分为三类:
- 多处理器结构 (SMP : Symmetric Multi-Processor):所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。SMP 服务器的主要问题,那就是它的扩展能力非常有限。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
- 海量并行处理结构 (MPP : Massive Parallel Processing) :NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。在一个物理服务器内可以支持上百个 CPU 。但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
- MPP 模式则是一种分布式存储器模式,能够将更多的处理器纳入一个系统的存储器。一个分布式存储器模式具有多个节点,每个节点都有自己的存储器,可以配置为SMP模式,也可以配置为非SMP模式。单个的节点相互连接起来就形成了一个总系统。MPP可以近似理解成一个SMP的横向扩展集群,MPP一般要依靠软件实现。
- 非一致存储访问结构 (NUMA : Non-Uniform Memory Access):它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ) ,是一种完全无共享 (Share Nothing) 结构。
详细描述可以参考 SMP、NUMA、MPP体系结构介绍。
查看你的服务器的 CPU 架构:
-
[root@rh65 s1]# uname -a -
Linux rh65 2.6.32-431.el6.x86_64 #1 SMP Sun Nov 10 22:19:54 EST 2013 x86_64 x86_64 x86_64 GNU/Linux #这服务器是 SMP 架构
2.2 KVM CPU 虚拟化
2.2.1 KVM 虚机的创建过程

可见:
(1)qemu-kvm 通过对 /dev/kvm 的 一系列 ICOTL 命令控制虚机,比如
open("/dev/kvm", O_RDWR|O_LARGEFILE) = 3 ioctl(3, KVM_GET_API_VERSION, 0) = 12 ioctl(3, KVM_CHECK_EXTENSION, 0x19) = 0 ioctl(3, KVM_CREATE_VM, 0) = 4 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0x4) = 1 ioctl(4, KVM_SET_TSS_ADDR, 0xfffbd000) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x25) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xb) = 1 ioctl(4, KVM_CREATE_PIT, 0xb) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0xf) = 2 ioctl(3, KVM_CHECK_EXTENSION, 0x3) = 1 ioctl(3, KVM_CHECK_EXTENSION, 0) = 1 ioctl(4, KVM_CREATE_IRQCHIP, 0) = 0 ioctl(3, KVM_CHECK_EXTENSION, 0x1a) = 0(2)一个 KVM 虚机即一个 Linux qemu-kvm 进程,与其他 Linux 进程一样被Linux 进程调度器调度。
(3)KVM 虚机包括虚拟内存、虚拟CPU和虚机 I/O设备,其中,内存和 CPU 的虚拟化由 KVM 内核模块负责实现,I/O 设备的虚拟化由 QEMU 负责实现。
(3)KVM户机系统的内存是 qumu-kvm 进程的地址空间的一部分。
(4)KVM 虚机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中。
vCPU、QEMU 进程、LInux 进程调度和物理CPU之间的逻辑关系:

2.2.2 因为 CPU 中的虚拟化功能的支持,并不存在虚拟的 CPU,KVM Guest 代码是运行在物理 CPU 之上
根据上面的 1.3 章节,支持虚拟化的 CPU 中都增加了新的功能。以 Intel VT 技术为例,它增加了两种运行模式:VMX root 模式和 VMX nonroot 模式。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。因为两个模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。
对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚级化成虚拟的 CPU 给客户机使用。
这篇文章 是关于 vSphere 中 CPU 虚拟化的,我觉得它和 KVM CPU 虚拟化存在很大的一致。下图是使用 2 socket 2 core 共 4 个 vCPU 的情形:

几个概念:socket (颗,CPU 的物理单位),core (核,每个 CPU 中的物理内核),thread (超线程,通常来说,一个 CPU core 只提供一个 thread,这时客户机就只看到一个 CPU;但是,超线程技术实现了 CPU 核的虚拟化,一个核被虚拟化出多个逻辑 CPU,可以同时运行多个线程)。
上图分三层,他们分别是是VM层,VMKernel层和物理层。对于物理服务器而言,所有的CPU资源都分配给单独的操作系统和上面运行的应用。应用将请求先发送给操作系统,然后操作系统调度物理的CPU资源。在虚拟化平台比如 KVM 中,在VM层和物理层之间加入了VMkernel层,从而允许所有的VM共享物理层的资源。VM上的应用将请求发送给VM上的操作系统,然后操纵系统调度Virtual CPU资源(操作系统认为Virtual CPU和物理 CPU是一样的),然后VMkernel层对多个物理CPU Core进行资源调度,从而满足Virtual CPU的需要。在虚拟化平台中OS CPU Scheduler和Hyperviisor CPU Scheduler都在各自的领域内进行资源调度。
KVM 中,可以指定 socket,core 和 thread 的数目,比如 设置 “-smp 5,sockets=5,cores=1,threads=1”,则 vCPU 的数目为 5*1*1 = 5。客户机看到的是基于 KVM vCPU 的 CPU 核,而 vCPU 作为 QEMU 线程被 Linux 作为普通的线程/轻量级进程调度到物理的 CPU 核上。至于你是该使用多 socket 和 多core,这篇文章 有仔细的分析,其结论是在 VMware ESXi 上,性能没什么区别,只是某些客户机操作系统会限制物理 CPU 的数目,这种情况下,可以使用少 socket 多 core。
2.2.3 客户机系统的代码是如何运行的
一个普通的 Linux 内核有两种执行模式:内核模式(Kenerl)和用户模式 (User)。为了支持带有虚拟化功能的 CPU,KVM 向 Linux 内核增加了第三种模式即客户机模式(Guest),该模式对应于 CPU 的 VMX non-root mode。

KVM 内核模块作为 User mode 和 Guest mode 之间的桥梁:
- User mode 中的 QEMU-KVM 会通过 ICOTL 命令来运行虚拟机
- KVM 内核模块收到该请求后,它先做一些准备工作,比如将 VCPU 上下文加载到 VMCS (virtual machine control structure)等,然后驱动 CPU 进入 VMX non-root 模式,开始执行客户机代码
三种模式的分工为:
- Guest 模式:执行客户机系统非 I/O 代码,并在需要的时候驱动 CPU 退出该模式
- Kernel 模式:负责将 CPU 切换到 Guest mode 执行 Guest OS 代码,并在 CPU 退出 Guest mode 时回到 Kenerl 模式
- User 模式:代表客户机系统执行 I/O 操作

(来源)
QEMU-KVM 相比原生 QEMU 的改动:
- 原生的 QEMU 通过指令翻译实现 CPU 的完全虚拟化,但是修改后的 QEMU-KVM 会调用 ICOTL 命令来调用 KVM 模块。
- 原生的 QEMU 是单线程实现,QEMU-KVM 是多线程实现。
主机 Linux 将一个虚拟视作一个 QEMU 进程,该进程包括下面几种线程:
- I/O 线程用于管理模拟设备
- vCPU 线程用于运行 Guest 代码
- 其它线程,比如处理 event loop,offloaded tasks 等的线程
在我的测试环境中(RedHata Linux 作 Hypervisor):
| smp 设置的值 | 线程数 | 线程 |
| 4 | 8 | 1 个主线程(I/O 线程)、4 个 vCPU 线程、3 个其它线程 |
| 6 | 10 | 1 个主线程(I/O 线程)、6 个 vCPU 线程、3 个其它线程 |
这篇文章 谈谈了这些线程的情况。

(来源)
| 客户机代码执行(客户机线程) | I/O 线程 | 非 I/O 线程 |
| 虚拟CPU(主机 QEMU 线程) | QEMU I/O 线程 | QEMU vCPU 线程 |
| 物理 CPU | 物理 CPU 的 VMX non-root 模式中 | 物理 CPU 的 VMX non-root 模式中 |
2.2.4 从客户机线程到物理 CPU 的两次调度
要将客户机内的线程调度到某个物理 CPU,需要经历两个过程:
- 客户机线程调度到客户机物理CPU 即 KVM vCPU,该调度由客户机操作系统负责,每个客户机操作系统的实现方式不同。在 KVM 上,vCPU 在客户机系统看起来就像是物理 CPU,因此其调度方法也没有什么不同。
- vCPU 线程调度到物理 CPU 即主机物理 CPU,该调度由 Hypervisor 即 Linux 负责。
KVM 使用标准的 Linux 进程调度方法来调度 vCPU 进程。Linux 系统中,线程和进程的区别是 进程有独立的内核空间,线程是代码的执行单位,也就是调度的基本单位。Linux 中,线程是就是轻量级的进程,也就是共享了部分资源(地址空间、文件句柄、信号量等等)的进程,所以线程也按照进程的调度方式来进行调度。
(1)Linux 进程调度原理可以参考 这篇文章 和 这篇文章。通常情况下,在SMP系统中,Linux内核的进程调度器根据自有的调度策略将系统中的一个可运行(runable)进程调度到某个CPU上执行。下面是 Linux 进程的状态机:

(2)处理器亲和性:可以设置 vCPU 在指定的物理 CPU 上运行,具体可以参考这篇文章 和 这篇文章。
根据 Linux 进程调度策略,可以看出,在 Linux 主机上运行的 KVM 客户机 的总 vCPU 数目最好是不要超过物理 CPU 内核数,否则,会出现线程间的 CPU 内核资源竞争,导致有虚机因为 vCPU 进程等待而导致速度很慢。
关于这两次调度,业界有很多的研究,比如上海交大的论文 Schedule Processes, not VCPUs 提出动态地减少 vCPU 的数目即减少第二次调度。
另外,这篇文章 谈到的是 vSphere CPU 的调度方式,有空的时候可以研究下并和 KVM vCPU 的调度方式进行比较。
2.3 客户机CPU结构和模型
KVM 支持 SMP 和 NUMA 多CPU架构的主机和客户机。对 SMP 类型的客户机,使用 “-smp”参数:
-smp [,cores=][,threads=][,sockets=][,maxcpus=]对 NUMA 类型的客户机,使用 “-numa”参数:
-numa [,mem=][,cpus=]][,nodeid=] CPU 模型 (models)定义了哪些主机的 CPU 功能 (features)会被暴露给客户机操作系统。为了在具有不同 CPU 功能的主机之间做安全的迁移,qemu-kvm 往往不会将主机CPU的所有功能都暴露给客户机。其原理如下:
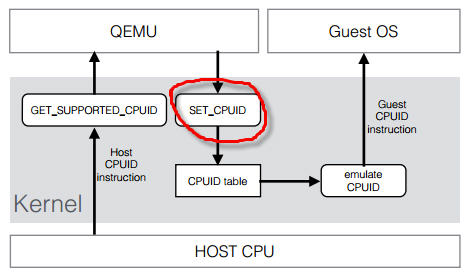
你可以运行 qemu-kvm -cpu ? 命令来获取主机所支持的 CPU 模型列表。
-
[root@rh65 s1]# kvm -cpu ? x86 Opteron_G5 AMD Opteron 63xx class CPU -
x86 Opteron_G4 AMD Opteron 62xx class CPU -
x86 Opteron_G3 AMD Opteron 23xx (Gen 3 Class Opteron) -
x86 Opteron_G2 AMD Opteron 22xx (Gen 2 Class Opteron) -
x86 Opteron_G1 AMD Opteron 240 (Gen 1 Class Opteron) -
x86 Haswell Intel Core Processor (Haswell) -
x86 SandyBridge Intel Xeon E312xx (Sandy Bridge) -
x86 Westmere Westmere E56xx/L56xx/X56xx (Nehalem-C) -
x86 Nehalem Intel Core i7 9xx (Nehalem Class Core i7) -
x86 Penryn Intel Core 2 Duo P9xxx (Penryn Class Core 2) -
x86 Conroe Intel Celeron_4x0 (Conroe/Merom Class Core 2) -
x86 cpu64-rhel5 QEMU Virtual CPU version (cpu64-rhel5) -
x86 cpu64-rhel6 QEMU Virtual CPU version (cpu64-rhel6) -
x86 n270 Intel(R) Atom(TM) CPU N270 @ 1.60GHz -
x86 athlon QEMU Virtual CPU version 0.12.1 x86 pentium3 -
x86 pentium2 -
x86 pentium -
x86 486 x86 coreduo Genuine Intel(R) CPU T2600 @ 2.16GHz -
x86 qemu32 QEMU Virtual CPU version 0.12.1 x86 kvm64 Common KVM processor -
x86 core2duo Intel(R) Core(TM)2 Duo CPU T7700 @ 2.40GHz -
x86 phenom AMD Phenom(tm) 9550 Quad-Core Processor -
x86 qemu64 QEMU Virtual CPU version 0.12.1 Recognized CPUID flags: -
f_edx: pbe ia64 tm ht ss sse2 sse fxsr mmx acpi ds clflush pn pse36 pat cmov mca pge mtrr sep apic cx8 mce pae msr tsc pse de vme fpu -
f_ecx: hypervisor rdrand f16c avx osxsave xsave aes tsc-deadline popcnt movbe x2apic sse4.2|sse4_2 sse4.1|sse4_1 dca pcid pdcm xtpr cx16 fma cid ssse3 tm2 est smx vmx ds_cpl monitor dtes64 pclmulqdq|pclmuldq pni|sse3 -
extf_edx: 3dnow 3dnowext lm|i64 rdtscp pdpe1gb fxsr_opt|ffxsr fxsr mmx mmxext nx|xd pse36 pat cmov mca pge mtrr syscall apic cx8 mce pae msr tsc pse de vme fpu -
extf_ecx: perfctr_nb perfctr_core topoext tbm nodeid_msr tce fma4 lwp wdt skinit xop ibs osvw 3dnowprefetch misalignsse sse4a abm cr8legacy extapic svm cmp_legacy lahf_lm -
[root@rh65 s1]#
每个 Hypervisor 都有自己的策略,来定义默认上哪些CPU功能会被暴露给客户机。至于哪些功能会被暴露给客户机系统,取决于客户机的配置。qemu32 和 qemu64 是基本的客户机 CPU 模型,但是还有其他的模型可以使用。你可以使用 qemu-kvm 命令的 -cpu 参数来指定客户机的 CPU 模型,还可以附加指定的 CPU 特性。"-cpu" 会将该指定 CPU 模型的所有功能全部暴露给客户机,即使某些特性在主机的物理CPU上不支持,这时候QEMU/KVM 会模拟这些特性,因此,这时候也许会出现一定的性能下降。
RedHat Linux 6 上使用默认的 cpu64-rhe16 作为客户机 CPU model:

你可以指定特定的 CPU model 和 feature:
qemu-kvm -cpu Nehalem,+aes 
你也可以直接使用 -cpu host,这样的话会客户机使用和主机相同的 CPU model。
2.4 客户机 vCPU 数目的分配方法
- 不是客户机的 vCPU 越多,其性能就越好,因为线程切换会耗费大量的时间;应该根据负载需要分配最少的 vCPU。
- 主机上的客户机的 vCPU 总数不应该超过物理 CPU 内核总数。不超过的话,就不存在 CPU 竞争,每个 vCPU 线程在一个物理 CPU 核上被执行;超过的话,会出现部分线程等待 CPU 以及一个 CPU 核上的线程之间的切换,这会有 overhead。
- 将负载分为计算负载和 I/O 负载,对计算负载,需要分配较多的 vCPU,甚至考虑 CPU 亲和性,将指定的物理 CPU 核分给给这些客户机。
这篇文章 (http://my.oschina.net/chape/blog/173981) 介绍了一些指导性方法,摘要如下:
我们来假设一个主机有 2 个socket,每个 socket 有 4 个core。主频2.4G MHZ 那么一共可用的资源是 2*4*2.4G= 19.2G MHZ。假设主机上运行了三个VM,VM1和VM2设置为1socket*1core,VM3设置为1socket*2core。那么VM1和VM2分别有1个vCPU,而VM3有2个vCPU。假设其他设置为缺省设置。
那么三个VM获得该主机CPU资源分配如下:VM1:25%; VM2:25%; VM3:50%
假设运行在VM3上的应用支持多线程,那么该应用可以充分利用到所非配的CPU资源。2vCPU的设置是合适的。假设运行在VM3上的应用不支持多线程,该应用根本无法同时使用利用2个vCPU. 与此同时,VMkernal层的CPU Scheduler必须等待物理层中两个空闲的pCPU,才开始资源调配来满足2个vCPU的需要。在仅有2vCPU的情况下,对该VM的性能不会有太大负面影响。但如果分配4vCPU或者更多,这种资源调度上的负担有可能会对该VM上运行的应用有很大负面影响。
确定 vCPU 数目的步骤。假如我们要创建一个VM,以下几步可以帮助确定合适的vCPU数目
1 了解应用并设置初始值
该应用是否是关键应用,是否有Service Level Agreement。一定要对运行在虚拟机上的应用是否支持多线程深入了解。咨询应用的提供商是否支持多线程和SMP(Symmetricmulti-processing)。参考该应用在物理服务器上运行时所需要的CPU个数。如果没有参照信息,可设置1vCPU作为初始值,然后密切观测资源使用情况。
2 观测资源使用情况
确定一个时间段,观测该虚拟机的资源使用情况。时间段取决于应用的特点和要求,可以是数天,甚至数周。不仅观测该VM的CPU使用率,而且观测在操作系统内该应用对CPU的占用率。特别要区分CPU使用率平均值和CPU使用率峰值。
假如分配有4个vCPU,如果在该VM上的应用的CPU
- 使用峰值等于25%, 也就是仅仅能最多使用25%的全部CPU资源,说明该应用是单线程的,仅能够使用一个vCPU (4 * 25% = 1 )
- 平均值小于38%,而峰值小于45%,考虑减少 vCPU 数目
- 平均值大于75%,而峰值大于90%,考虑增加 vCPU 数目
3 更改vCPU数目并观测结果
每次的改动尽量少,如果可能需要4vCPU,先设置2vCPU在观测性能是否可以接受。
2. KVM 内存虚拟化
2.1 内存虚拟化的概念
除了 CPU 虚拟化,另一个关键是内存虚拟化,通过内存虚拟化共享物理系统内存,动态分配给虚拟机。虚拟机的内存虚拟化很象现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存地址空间,这个地址空间无需和下面的物理机器内存直接对应,操作系统保持着虚拟页到物理页的映射。现在所有的 x86 CPU 都包括了一个称为内存管理的模块MMU(Memory Management Unit)和 TLB(Translation Lookaside Buffer),通过MMU和TLB来优化虚拟内存的性能。
KVM 实现客户机内存的方式是,利用mmap系统调用,在QEMU主线程的虚拟地址空间中申明一段连续的大小的空间用于客户机物理内存映射。
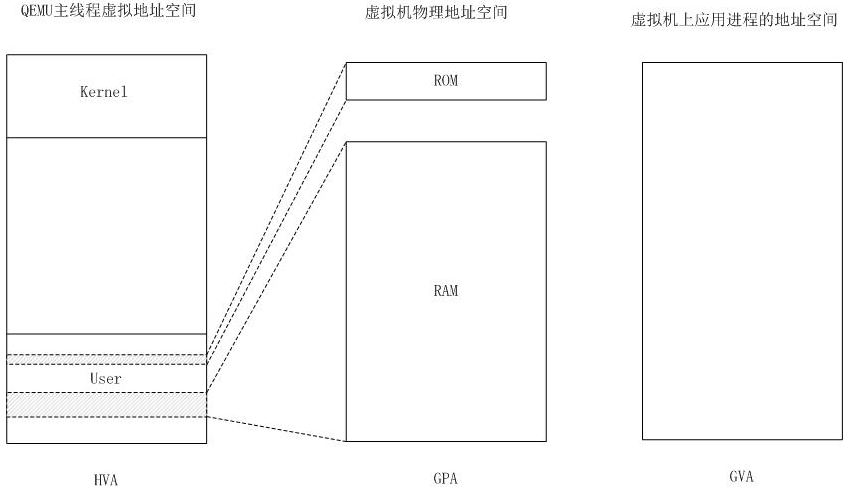
(图片来源 HVA 同下面的 MA,GPA 同下面的 PA,GVA 同下面的 VA)
在有两个虚机的情况下,情形是这样的:
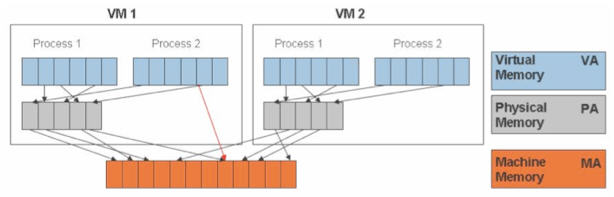
可见,KVM 为了在一台机器上运行多个虚拟机,需要增加一个新的内存虚拟化层,也就是说,必须虚拟 MMU 来支持客户操作系统,来实现 VA -> PA -> MA 的翻译。客户操作系统继续控制虚拟地址到客户内存物理地址的映射 (VA -> PA),但是客户操作系统不能直接访问实际机器内存,因此VMM 需要负责映射客户物理内存到实际机器内存 (PA -> MA)。
VMM 内存虚拟化的实现方式:
- 软件方式:通过软件实现内存地址的翻译,比如 Shadow page table (影子页表)技术
- 硬件实现:基于 CPU 的辅助虚拟化功能,比如 AMD 的 NPT 和 Intel 的 EPT 技术
影子页表技术:
2.2 KVM 内存虚拟化
KVM 中,虚机的物理内存即为 qemu-kvm 进程所占用的内存空间。KVM 使用 CPU 辅助的内存虚拟化方式。在 Intel 和 AMD 平台,其内存虚拟化的实现方式分别为:
- AMD 平台上的 NPT (Nested Page Tables) 技术
- Intel 平台上的 EPT (Extended Page Tables)技术
EPT 和 NPT采用类似的原理,都是作为 CPU 中新的一层,用来将客户机的物理地址翻译为主机的物理地址。关于 EPT, Intel 官方文档中的技术如下(实在看不懂...)

EPT的好处是,它的两阶段记忆体转换,特点就是将 Guest Physical Address → System Physical Address,VMM不用再保留一份 SPT (Shadow Page Table),以及以往还得经过 SPT 这个转换过程。除了降低各部虚拟机器在切换时所造成的效能损耗外,硬体指令集也比虚拟化软体处理来得可靠与稳定。
2.3 KSM (Kernel SamePage Merging 或者 Kernel Shared Memory)
KSM 在 Linux 2.6.32 版本中被加入到内核中。
2.3.1 原理
其原理是,KSM 作为内核中的守护进程(称为 ksmd)存在,它定期执行页面扫描,识别副本页面并合并副本,释放这些页面以供它用。因此,在多个进程中,Linux将内核相似的内存页合并成一个内存页。这个特性,被KVM用来减少多个相似的虚拟机的内存占用,提高内存的使用效率。由于内存是共享的,所以多个虚拟机使用的内存减少了。这个特性,对于虚拟机使用相同镜像和操作系统时,效果更加明显。但是,事情总是有代价的,使用这个特性,都要增加内核开销,用时间换空间。所以为了提高效率,可以将这个特性关闭。
2.3.2 好处
其好处是,在运行类似的客户机操作系统时,通过 KSM,可以节约大量的内存,从而可以实现更多的内存超分,运行更多的虚机。
2.3.3 合并过程
(1)初始状态:

(2)合并后:

(3)Guest 1 写内存后:

2.4 KVM Huge Page Backed Memory (巨页内存技术)
这是KVM虚拟机的又一个优化技术.。Intel 的 x86 CPU 通常使用4Kb内存页,当是经过配置,也能够使用巨页(huge page): (4MB on x86_32, 2MB on x86_64 and x86_32 PAE)
使用巨页,KVM的虚拟机的页表将使用更少的内存,并且将提高CPU的效率。最高情况下,可以提高20%的效率!
使用方法,需要三部:
mkdir /dev/hugepagesmount -t hugetlbfs hugetlbfs /dev/hugepages
-
#保留一些内存给巨页 -
sysctl vm.nr_hugepages=2048 (使用 x86_64 系统时,这相当于从物理内存中保留了2048 x 2M = 4GB 的空间来给虚拟机使用)
-
#给 kvm 传递参数 hugepages -
qemu-kvm - qemu-kvm -mem-path /dev/hugepages
也可以在配置文件里加入:
验证方式,当虚拟机正常启动以后,在物理机里查看:
cat /proc/meminfo |grep -i hugepages老外的一篇文档,他使用的是libvirt方式,先让libvirtd进程使用hugepages空间,然后再分配给虚拟机。
参考资料:
http://www.cnblogs.com/xusongwei/archive/2012/07/30/2615592.html
https://www.ibm.com/developerworks/cn/linux/l-cn-vt/
http://www.slideshare.net/HwanjuKim/3cpu-virtualization-and-scheduling
http://www.cse.iitb.ac.in/~puru/courses/autumn12/cs695/classes/kvm-overview.pdf
http://www.linux-kvm.com/content/using-ksm-kernel-samepage-merging-kvm
http://blog.csdn.net/summer_liuwei/article/details/6013255
http://blog.pchome.net/article/458429.html
http://blog.chinaunix.net/uid-20794164-id-3601787.html
虚拟化技术性能比较和分析,周斌,张莹
http://wiki.qemu.org/images/c/c8/Cpu-models-and-libvirt-devconf-2014.pdf
http://frankdenneman.nl/2011/01/11/beating-a-dead-horse-using-cpu-affinity/
(3):I/O 全虚拟化和准虚拟化
在 QEMU/KVM 中,客户机可以使用的设备大致可分为三类:
1. 模拟设备:完全由 QEMU 纯软件模拟的设备。
2. Virtio 设备:实现 VIRTIO API 的半虚拟化设备。
3. PCI 设备直接分配 (PCI device assignment) 。
1. 全虚拟化 I/O 设备
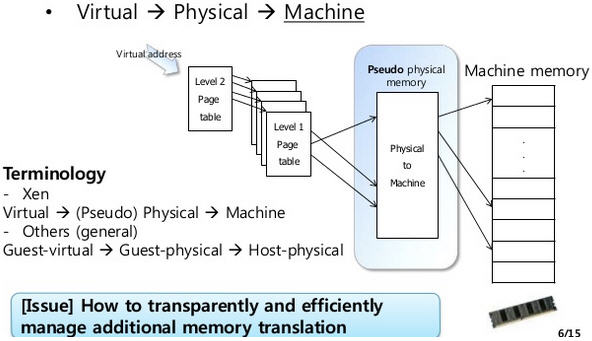
KVM 在 IO 虚拟化方面,传统或者默认的方式是使用 QEMU 纯软件的方式来模拟 I/O 设备,包括键盘、鼠标、显示器,硬盘 和 网卡 等。模拟设备可能会使用物理的设备,或者使用纯软件来模拟。模拟设备只存在于软件中。
1.1 原理
过程:
- 客户机的设备驱动程序发起 I/O 请求操作请求
- KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求
- 经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序。
- QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作。
- 完成之后,QEMU 将结果放回 I/O 共享页,并通知 KMV 模块中的 I/O 操作捕获代码。
- KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机。
注意:当客户机通过DMA (Direct Memory Access)访问大块I/O时,QEMU 模拟程序将不会把结果放进共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中共,然后通知KVM模块告诉客户机DMA操作已经完成。
这种方式的优点是可以模拟出各种各样的硬件设备;其缺点是每次 I/O 操作的路径比较长,需要多次上下文切换,也需要多次数据复制,所以性能较差。
1.2 QEMU 模拟网卡的实现
Qemu 纯软件的方式来模拟I/O设备,其中包括经常使用的网卡设备。Guest OS启动命令中没有传入的网络配置时,QEMU默认分配 rtl8139 类型的虚拟网卡类型,使用的是默认用户配置模式,这时候由于没有具体的网络模式的配置,Guest的网络功能是有限的。 全虚拟化情况下,KVM虚机可以选择的网络模式包括:
- 默认用户模式(User);
- 基于网桥(Bridge)的模式;
- 基于NAT(Network Address Translation)的模式;
分别使用的 qemu-kvm 参数为:
- -net user[,vlan=n]:使用用户模式网络堆栈,这样就不需要管理员权限来运行.如果没有指 定-net选项,这将是默认的情况.-net tap[,vlan=n][,fd=h]
- -net nic[,vlan=n][,macaddr=addr]:创建一个新的网卡并与VLAN n(在默认的情况下n=0)进行连接。作为可选项的项目,MAC地址可以进行改变.如果 没有指定-net选项,则会创建一个单一的NIC.
- -net tap[,vlan=n][,fd=h][,ifname=name][,script=file]:将TAP网络接口 name 与 VLAN n 进行连接,并使用网络配置脚本文件进行 配置。默认的网络配置脚本为/etc/qemu-ifup。如果没有指定name,OS 将会自动指定一个。fd=h可以用来指定一个已经打开的TAP主机接口的句柄。
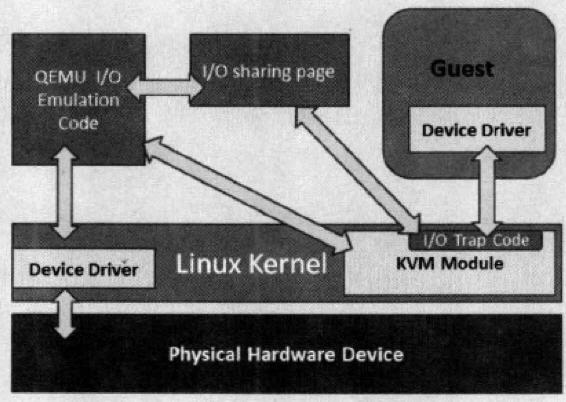
网桥模式是目前比较简单,也是用的比较多的模式,下图是网桥模式下的 VM的收发包的流程。
如图中所示,红色箭头表示数据报文的入方向,步骤:
- 网络数据从 Host 上的物理网卡接收,到达网桥;
- 由于 eth0 与 tap1 均加入网桥中,根据二层转发原则,br0 将数据从 tap1 口转发出去,即数据由 Tap设备接收;
- Tap 设备通知对应的 fd 数据可读;
- fd 的读动作通过 tap 设备的字符设备驱动将数据拷贝到用户空间,完成数据报文的前端接收。
(引用自 http://luoye.me/2014/07/17/netdev-virtual-1/)
1.3 RedHat Linux 6 中提供的模拟设备
- 模拟显卡:提供2块模拟显卡。
- 系统组件:
- ntel i440FX host PCI bridge
- PIIX3 PCI to ISA bridge
- PS/2 mouse and keyboard
- EvTouch USB Graphics Tablet
- PCI UHCI USB controller and a virtualized USB hub
- Emulated serial ports
- EHCI controller, virtualized USB storage and a USB mouse
- 模拟的声卡:intel-hda
- 模拟网卡:e1000,模拟 Intel E1000 网卡;rtl8139,模拟 RealTeck 8139 网卡。
- 模拟存储卡:两块模拟 PCI IDE 接口卡。KVM 限制每个虚拟机最多只能有4块虚拟存储卡。还有模拟软驱。
注意:RedHat Linux KVM 不支持 SCSI 模拟。
在不显式指定使用其它类型设备的情况下,KVM 虚机将使用这些默认的虚拟设备。比如上面描述的默认情况下 KVM 虚机默认使用rtl8139网卡。比如,在 RedHat Linxu 6.5 主机上启动KVM RedHat Linux 6.4 虚机后,登录虚机,查看 pci 设备,可以看到这些模拟设备:

当使用 “-net nic,model=e1000” 指定网卡model 为 e1000 时,
1.4 qemu-kvm 关于磁盘设备和网络的主要选项
| 类型 | 选项 |
| 磁盘设备(软盘、硬盘、CDROM等) |
|
| 网络 | -net nic[,vlan=n][,macaddr=mac][,model=type][,name=name][,addr=addr][,vectors=v]:创建一个新的网卡设备并连接至vlan n中;PC架构上默认的NIC为e1000,macaddr用于为其指定MAC地址,name用于指定一个在监控时显示的网上设备名称;emu可以模拟多个类型的网卡设备;可以使用“qemu-kvm -net nic,model=?”来获取当前平台支持的类型; -net tap[,vlan=n][,name=name][,fd=h][,ifname=name][,script=file][,downscript=dfile]:通过物理机的TAP网络接口连接至vlan n中,使用script=file指定的脚本(默认为/etc/qemu-ifup)来配置当前网络接口,并使用downscript=file指定的脚本(默认为/etc/qemu-ifdown)来撤消接口配置;使用script=no和downscript=no可分别用来禁止执行脚本; -net user[,option][,option][,...]:在用户模式配置网络栈,其不依赖于管理权限;有效选项有: vlan=n:连接至vlan n,默认n=0; name=name:指定接口的显示名称,常用于监控模式中; net=addr[/mask]:设定GuestOS可见的IP网络,掩码可选,默认为10.0.2.0/8; host=addr:指定GuestOS中看到的物理机的IP地址,默认为指定网络中的第二个,即x.x.x.2; dhcpstart=addr:指定DHCP服务地址池中16个地址的起始IP,默认为第16个至第31个,即x.x.x.16-x.x.x.31; dns=addr:指定GuestOS可见的dns服务器地址;默认为GuestOS网络中的第三个地址,即x.x.x.3; tftp=dir:激活内置的tftp服务器,并使用指定的dir作为tftp服务器的默认根目录; bootfile=file:BOOTP文件名称,用于实现网络引导GuestOS;如:qemu -hda linux.img -boot n -net user,tftp=/tftpserver/pub,bootfile=/pxelinux.0 |
对于网卡来说,你可以使用 modle 参数指定虚拟网络的类型。 RedHat Linux 6 所支持的虚拟网络类型有:
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio 2. 准虚拟化 (Para-virtualizaiton) I/O 驱动 virtio
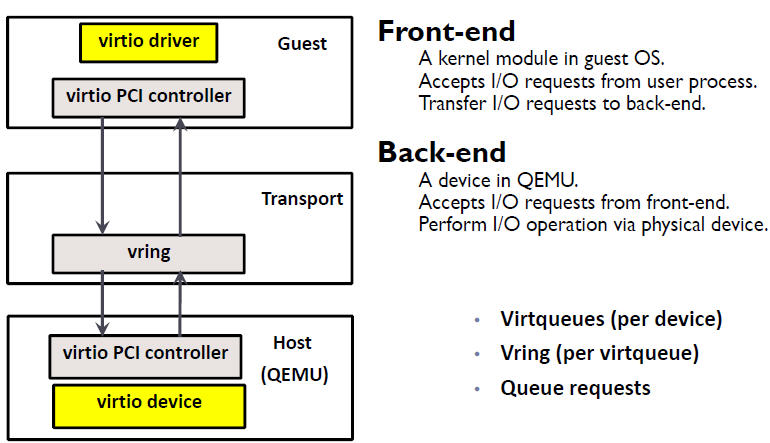
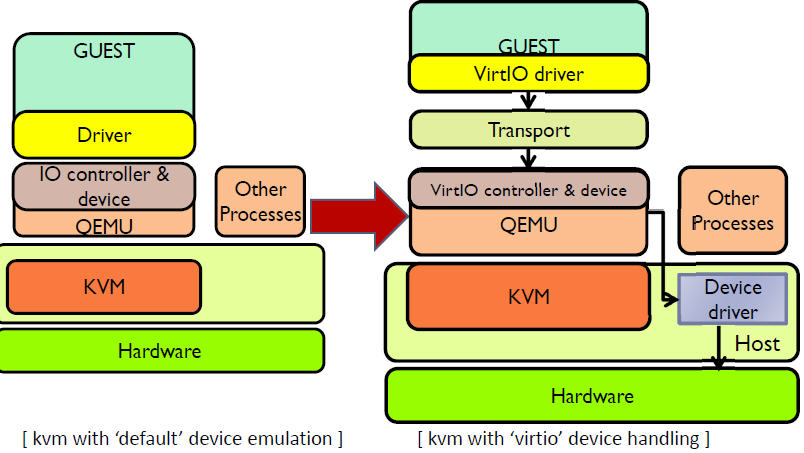
在 KVM 中可以使用准虚拟化驱动来提供客户机的I/O 性能。目前 KVM 采用的的是 virtio 这个 Linux 上的设备驱动标准框架,它提供了一种 Host 与 Guest 交互的 IO 框架。
2.1 virtio 的架构
KVM/QEMU 的 vitio 实现采用在 Guest OS 内核中安装前端驱动 (Front-end driver)和在 QEMU 中实现后端驱动(Back-end)的方式。前后端驱动通过 vring 直接通信,这就绕过了经过 KVM 内核模块的过程,达到提高 I/O 性能的目的。
纯软件模拟的设备和 Virtio 设备的区别:virtio 省去了纯模拟模式下的异常捕获环节,Guest OS 可以和 QEMU 的 I/O 模块直接通信。
使用 Virtio 的完整虚机 I/O流程:
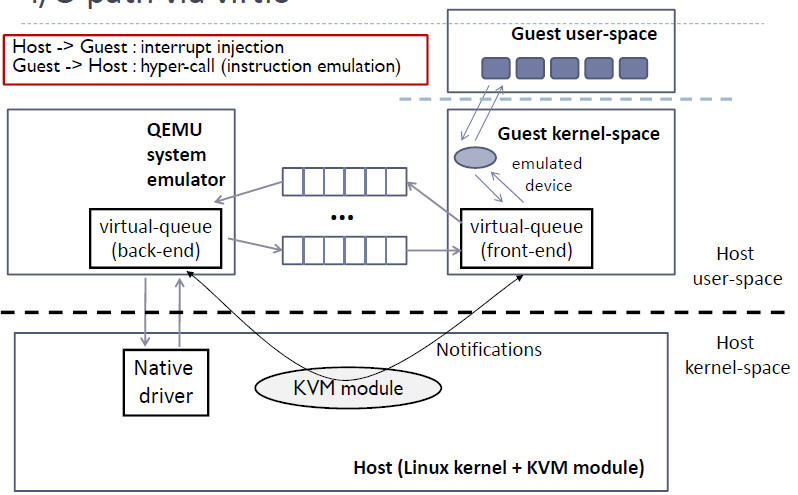
Host 数据发到 Guest:
1. KVM 通过中断的方式通知 QEMU 去获取数据,放到 virtio queue 中
2. KVM 再通知 Guest 去 virtio queue 中取数据。
2.2 Virtio 在 Linux 中的实现
Virtio 是在半虚拟化管理程序中的一组通用模拟设备的抽象。这种设计允许管理程序通过一个应用编程接口 (API)对外提供一组通用模拟设备。通过使用半虚拟化管理程序,客户机实现一套通用的接口,来配合后面的一套后端设备模拟。后端驱动不必是通用的,只要它们实现了前端所需的行为。因此,Virtio 是一个在 Hypervisor 之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,进而根据 virtio 标准与 Hypervisor 协作,从而客户机达到更好的性能。
- 前端驱动:客户机中安装的驱动程序模块
- 后端驱动:在 QEMU 中实现,调用主机上的物理设备,或者完全由软件实现。
- virtio 层:虚拟队列接口,从概念上连接前端驱动和后端驱动。驱动可以根据需要使用不同数目的队列。比如 virtio-net 使用两个队列,virtio-block只使用一个队列。该队列是虚拟的,实际上是使用 virtio-ring 来实现的。
- virtio-ring:实现虚拟队列的环形缓冲区
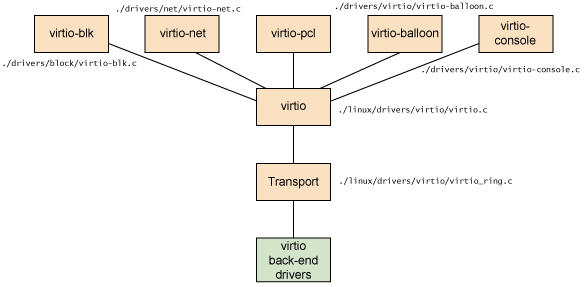
Linux 内核中实现的五个前端驱动程序:
- 块设备(如磁盘)
- 网络设备
- PCI 设备
- 气球驱动程序(动态管理客户机内存使用情况)
- 控制台驱动程序
Guest OS 中,在不使用 virtio 设备的时候,这些驱动不会被加载。只有在使用某个 virtio 设备的时候,对应的驱动才会被加载。每个前端驱动器具有在管理程序中的相应的后端的驱动程序。
以 virtio-net 为例,解释其原理:
(1)virtio-net 的原理:

它使得:
- 多个虚机共享主机网卡 eth0
- QEMU 使用标准的 tun/tap 将虚机的网络桥接到主机网卡上
- 每个虚机看起来有一个直接连接到主机PCI总线上的私有 virtio 网络设备
- 需要在虚机里面安装 virtio驱动
(2)virtio-net 的流程:

总结 Virtio 的优缺点:
- 优点:更高的IO性能,几乎可以和原生系统差不多。
- 缺点:客户机必须安装特定的 virtio 驱动。一些老的 Linux 还没有驱动支持,一些 Windows 需要安装特定的驱动。不过,较新的和主流的OS都有驱动可以下载了。Linux 2.6.24+ 都默认支持 virtio。可以使用 lsmod | grep virtio 查看是否已经加载。
2.3 使用 virtio 设备 (以 virtio-net 为例)
使用 virtio 类型的设备比较简单。较新的 Linux 版本上都已经安装好了 virtio 驱动,而 Windows 的驱动需要自己下载安装。
(1)检查主机上是否支持 virtio 类型的网卡设备
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio(2)指定网卡设备model 为 virtio,启动虚机

(3)通过 vncviewer 登录虚机,能看到被加载了的 virtio-net 需要的内核模块

(4)查看 pci 设备


其它 virtio 类型的设备的使用方式类似 virtio-net。
2.4 vhost-net (kernel-level virtio server)
前面提到 virtio 在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而如果对于网络 I/O 请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做 “vhost-net” 的驱动模块,它是作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,减少内核空间到用户空间的切换,从而提高效率。
根据 KVM 官网的这篇文章,vhost-net 能提供更低的延迟(latency)(比 e1000 虚拟网卡低 10%),和更高的吞吐量(throughput)(8倍于普通 virtio,大概 7~8 Gigabits/sec )。
vhost-net 与 virtio-net 的比较:

vhost-net 的要求:
- qemu-kvm-0.13.0 或者以上
- 主机内核中设置 CONFIG_VHOST_NET=y 和在虚机操作系统内核中设置 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 开始支持该特性)
- 在客户机内使用 virtion-net 前段驱动
- 在主机内使用网桥模式,并且启动 vhost_net
qemu-kvm 命令的 -net tap 有几个选项和 vhost-net 相关的: -net tap,[,vnet_hdr=on|off][,vhost=on|off][,vhostfd=h][,vhostforce=on|off]
- vnet_hdr =on|off:设置是否打开TAP设备的“IFF_VNET_HDR”标识。“vnet_hdr=off”表示关闭这个标识;“vnet_hdr=on”则强制开启这个标识,如果没有这个标识的支持,则会触发错误。IFF_VNET_HDR是tun/tap的一个标识,打开它则允许发送或接受大数据包时仅仅做部分的校验和检查。打开这个标识,可以提高virtio_net驱动的吞吐量。
- vhost=on|off:设置是否开启vhost-net这个内核空间的后端处理驱动,它只对使用MIS-X中断方式的virtio客户机有效。
- vhostforce=on|off:设置是否强制使用 vhost 作为非MSI-X中断方式的Virtio客户机的后端处理程序。
- vhostfs=h:设置为去连接一个已经打开的vhost网络设备。
vhost-net 的使用实例:
(1)确保主机上 vhost-net 内核模块被加载了

(2)启动一个虚拟机,在客户机中使用 -net 定义一个 virtio-net 网卡,在主机端使用 -netdev 启动 vhost

(3)在虚拟机端,看到 virtio 网卡使用的 TAP 设备为 tap0。

(4)在宿主机中看 vhost-net 被加载和使用了,以及 Linux 桥 br0,它连接物理网卡 eth1 和 客户机使用的 TAP 设备 tap0

一般来说,使用 vhost-net 作为后端处理驱动可以提高网络的性能。不过,对于一些网络负载类型使用 vhost-net 作为后端,却可能使其性能不升反降。特别是从宿主机到其中的客户机之间的UDP流量,如果客户机处理接受数据的速度比宿主机发送的速度要慢,这时就容易出现性能下降。在这种情况下,使用vhost-net将会是UDP socket的接受缓冲区更快地溢出,从而导致更多的数据包丢失。故这种情况下,不使用vhost-net,让传输速度稍微慢一点,反而会提高整体的性能。
使用 qemu-kvm 命令行,加上“vhost=off”(或没有vhost选项)就会不使用vhost-net,而在使用libvirt时,需要对客户机的配置的XML文件中的网络配置部分进行如下的配置,指定后端驱动的名称为“qemu”(而不是“vhost”)。
2.6 virtio-balloon
另一个比较特殊的 virtio 设备是 virtio-balloon。通常来说,要改变客户机所占用的宿主机内存,要先关闭客户机,修改启动时的内存配置,然后重启客户机才可以实现。而 内存的 ballooning (气球)技术可以在客户机运行时动态地调整它所占用的宿主机内存资源,而不需要关闭客户机。该技术能够:
- 当宿主机内存紧张时,可以请求客户机回收利用已分配给客户机的部分内存,客户机就会释放部分空闲内存。若其内存空间不足,可能还会回收部分使用中的内存,可能会将部分内存换到交换分区中。
- 当客户机内存不足时,也可以让客户机的内存气球压缩,释放出内存气球中的部分内存,让客户机使用更多的内存。

目前很多的VMM,包括 KVM, Xen,VMware 等都对 ballooning 技术提供支持。其中,KVM 中的 Ballooning 是通过宿主机和客户机协同来实现的,在宿主机中应该使用 2.6.27 及以上版本的 Linux内核(包括KVM模块),使用较新的 qemu-kvm(如0.13版本以上),在客户机中也使用 2.6.27 及以上内核且将“CONFIG_VIRTIO_BALLOON”配置为模块或编译到内核。在很多Linux发行版中都已经配置有“CONFIG_VIRTIO_BALLOON=m”,所以用较新的Linux作为客户机系统,一般不需要额外配置virtio_balloon驱动,使用默认内核配置即可。
原理:
- KVM 发送请求给 VM 让其归还一定数量的内存给KVM。
- VM 的 virtio_balloon 驱动接到该请求。
- VM 的驱动是客户机的内存气球膨胀,气球中的内存就不能被客户机使用。
- VM 的操作系统归还气球中的内存给VMM
- KVM 可以将得到的内存分配到任何需要的地方。
- KM 也可以将内存返还到客户机中。
优势和不足:
| 优势 | 不足 |
|
|
在QEMU monitor中,提供了两个命令查看和设置客户机内存的大小。
- (qemu) info balloon #查看客户机内存占用量(Balloon信息)
- (qemu) balloon num #设置客户机内存占用量为numMB
使用实例:
(1)启动一个虚机,内存为 2048M,启用 virtio-balloon

(2)通过 vncviewer 进入虚机,查看 pci 设备

(3)看看内存情况,共 2G 内存

(4)进入 QEMU Monitor,调整 balloon 内存为 500M

(5)回到虚机,查看内存,变为 500 M

2.7 RedHat 的 多队列 Virtio (multi-queue)
目前的高端服务器都有多个处理器,虚拟使用的虚拟CPU数目也不断增加。默认的 virtio-net 不能并行地传送或者接收网络包,因为 virtio_net 只有一个TX 和 RX 队列。而多队列 virtio-net 提供了一个随着虚机的虚拟CPU增加而增强网络性能的方法,通过使得 virtio 可以同时使用多个 virt-queue 队列。
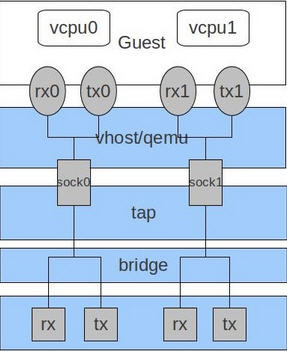
它在以下情况下具有明显优势:
- 网络流量非常大
- 虚机同时有非常多的网络连接,包括虚拟机之间的、虚机到主机的、虚机到外部系统的等
- virtio 队列的数目和虚机的虚拟CPU数目相同。这是因为多队列能够使得一个队列独占一个虚拟CPU。
注意:对队列 virtio-net 对流入的网络流工作得非常好,但是对外发的数据流偶尔会降低性能。打开对队列 virtio 会增加中的吞吐量,这相应地会增加CPU的负担。 在实际的生产环境中需要做必须的测试后才确定是否使用。
在 RedHat 中,要使用多队列 virtio-net,在虚机的 XML 文件中增加如下配置:

然后在主机上运行下面的命令:
ethtool -L eth0 combined M ( 1 <= M <= N)2.8 Windows 客户机的 virtio 前端驱动
Windows 客户机下的 virtio 前端驱动必须下载后手工安装。 RedHat Linux 这篇文章 说明了在 Windows 客户机内安装virtio 驱动的方法。
参考文档:
- http://linux.web.cern.ch/linux/centos7/docs/rhel/Red_Hat_Enterprise_Linux-7-Virtualization_Tuning_and_Optimization_Guide-en-US.pdf
- http://toast.djw.org.uk/qemu.html
- KVM 官方文档
- KVM 虚拟化技术实战与解析 任永杰、单海涛 著
- RedHat Linux 6 官方文档
- http://www.slideshare.net 中关于 KVM 的一些文档
- http://www.linux-kvm.org/page/Multiqueue
- 以及部分来自于网络,比如 http://smilejay.com/2012/11/use-ballooning-in-kvm/
(4):I/O 设备直接分配和 SR-IOV
本文将分析 PCI/PCIe 设备直接分配(Pass-through)和 SR-IOV, 以及三种 I/O 虚拟化方式的比较。
1. PCI/PCI-E 设备直接分配给虚机 (PCI Pass-through)
设备直接分配 (Device assignment)也称为 Device Pass-Through。
先简单看看PCI 和 PCI-E 的区别(AMD CPU):

(简单点看,PCI 卡的性能没有 PCI-E 高,因为 PCI-E 是直接连在 IOMMU 上,而 PCI 卡是连在一个 IO Hub 上。)
主要的 PCI 设备类型:
- Network cards (wired or wireless)
- SCSI adapters
- Bus controllers: USB, PCMCIA, I2C, FireWire, IDE
- Graphics and video cards
- Sound cards
1.1 PCI/PCIe Pass-through 原理
这种方式,允许将宿主机中的物理 PCI 设备直接分配给客户机使用。较新的x86平台已经支持这种类型,Intel 定义的 I/O 虚拟化技术成为 VT-d,AMD 的称为 AMD-V。KVM 支持客户机以独占方式访问这个宿主机的 PCI/PCI-E 设备。通过硬件支持的 VT-d 技术将设备分给客户机后,在客户机看来,设备是物理上连接在PCI或者PCI-E总线上的,客户机对该设备的I/O交互操作和实际的物理设备操作完全一样,不需要或者很少需要 KVM 的参与。运行在 VT-d 平台上的 QEMU/KVM,可以分配网卡、磁盘控制器、USB控制器、VGA 显卡等设备供客户机直接使用。
几乎所有的 PCI 和 PCI-E 设备都支持直接分配,除了显卡以外(显卡的特殊性在这里)。PCI Pass-through 需要硬件平台 Intel VT-d 或者 AMD IOMMU 的支持。这些特性必须在 BIOS 中被启用。Red Hat Enterprise Linux 6.0 及以上版本支持热插拔的 PCI 设备直接分配到虚拟机。
网卡直接分配:
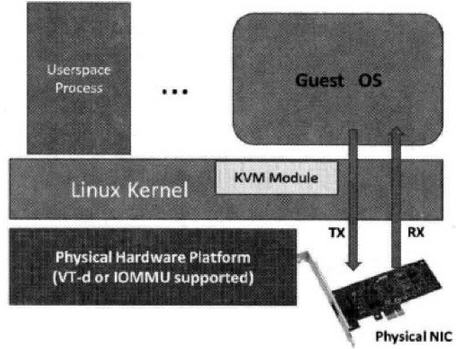
硬盘直接分配:
- 一般 SATA 或者 SAS 等类型的硬盘的控制器都是直接接入到 PCI 或者 PCI-E 总线的,所以也可以将硬盘作为普通的PCI设备直接分配个客户机。需要注意的是,当分配硬盘时,实际上将其控制器作为一个整体分配到客户机中,因此需要在硬件平台上至少有另两个或者多个SATA或者 SAS控制器。
1.2 在 RedHat Linux 6 上使用 virt-manger 分配一个光纤卡给虚机
准备工作:
(1)在 BIOS 中打开 Intel VT-d
(2)在 Linux 内核中启用 PCI Pass-through
添加 intel_iommu=on 到 /boot/grub/grub.conf 文件中。(在我的 RedHat Linux 6上,该文件是 /boot/grub.conf)
(3)重启系统,使得配置生效
实际分配:
(1)使用 lspci -nn 命令找到待分配的 PCI 设备。这里以一个 FC 卡为例:

使用 lspci 命令得到的 PCI 数字的含义,以后使用 libvirt API 分配设备时会用到:

(2)使用 virsh nodedev-list 命令找到该设备的 PCI 编号

(3)将设备从主机上解除

(4)使用 virt-manager 将设备直接分配给一个启动了的虚拟机

(5)添加好了后的效果

(6)在虚机中查看该PCI设备

(7)不再使用的话,需要在 virt-manager 中首先将该设备移除,然后在主机上重新挂载该设备

1.3 在 RedHat Linux 6 上使用 qemu-kvm 分配一个光纤卡给虚机
除了步骤(4),其他步骤同上面。

1.4 设备直接分配让客户机的优势和不足
- 好处:在执行 I/O 操作时大量减少甚至避免 VM-Exit 陷入到 Hypervisor 中,极大地提高了性能,可以达到几乎和原生系统一样的性能。VT-d 克服了 virtio 兼容性不好和 CPU 使用频率较高的问题。
- 不足:(1)一台服务器主板上的空间比较有限,因此允许添加的 PCI 和 PCI-E 设备是有限的。大量使用 VT-d 独立分配设备给客户机,让硬件设备数量增加,这会增加硬件投资成本。(2)对于使用 VT-d 直接分配了设备的客户机,其动态迁移功能将受限,不过也可以使用热插拔或者libvirt 工具等方式来缓解这个问题。
- 不足的解决方案:(1)在一台物理宿主机上,仅少数 I/O 如网络性能要求较高的客户机使用 VT-d直接分配设备,其他的使用纯模拟或者 virtio 已达到多个客户机共享同一个设备的目的 (2)对于网络I/O的解决办法,可以选择 SR-IOV 是一个网卡产生多个独立的虚拟网卡,将每个虚拟网卡分配个一个客户机使用。
2. SR-IOV 设备分配
2.1 原理
VT-d 的性能非常好,但是它的物理设备只能分配给一个客户机使用。为了实现多个虚机共享一个物理设备,并且达到直接分配的目的,PCI-SIG 组织发布了 SR-IOV (Single Root I/O Virtualization and sharing) 规范,它定义了一个标准化的机制用以原生地支持实现多个客户机共享一个设备。不过,目前 SR-IOV (单根 I/O 虚拟化)最广泛地应用还是网卡上。
SR-IOV 使得一个单一的功能单元(比如,一个以太网端口)能看起来像多个独立的物理设备。一个带有 SR-IOV 功能的物理设备能被配置为多个功能单元。SR-IOV 使用两种功能(function):
- 物理功能(Physical Functions,PF):这是完整的带有 SR-IOV 能力的PCIe 设备。PF 能像普通 PCI 设备那样被发现、管理和配置。
- 虚拟功能(Virtual Functions,VF):简单的 PCIe 功能,它只能处理I/O。每个 VF 都是从 PF 中分离出来的。每个物理硬件都有一个 VF 数目的限制。一个 PF,能被虚拟成多个 VF 用于分配给多个虚拟机。
Hypervisor 能将一个或者多个 VF 分配给一个虚机。在某一时刻,一个 VF 只能被分配给一个虚机。一个虚机可以拥有多个 VF。在虚机的操作系统看来,一个 VF 网卡看起来和一个普通网卡没有区别。SR-IOV 驱动是在内核中实现的。
网卡 SR-IOV 的例子:


光纤卡 SR-IOV 的例子:

2.2 SR-IOV 的条件
- 需要 CPU 支持 Intel VT-x 和 VT-D (或者 AMD 的 SVM 和 IOMMU)
- 需要有支持 SR-IOV 规范的设备:目前这种设备较多,比如Intel的很多中高端网卡等。
- 需要 QEMU/KAM 的支持。
RedHat Linux 6.0 官方只完整测试了下面的几款 SR-IOV 网卡:
- Intel? 82576NS Gigabit Ethernet Controller ( igb 驱动)
- Intel? 82576EB Gigabit Ethernet Controller ( igb 驱动)
- Intel? 82599ES 10 Gigabit Ethernet Controller ( ixgbe 驱动)
- Intel? 82599EB 10 Gigabit Ethernet Controller ( ixgbe 驱动)
2.3 分配 SR-IOV 设备的步骤
手头没有支持SR-IOV的设备。这是 RedHat 上 SR-IOV 的配置步骤: Using SR-IOV。
简单来说,SR-IOV 分配步骤和设备直接分配相比基本类似,除了要使 PF 虚拟化成多个 VF 以外。
2.4 优势和不足
| 优势 | 不足 |
|
|
3. 各种设备虚拟化方式的比较
3.1 架构上的比较(以网卡为例)


3.2 性能上的比较 (以网卡为例)
纯模拟网卡和物理网卡的比较:

(来源:Evaluating and Optimizing I/O Virtualization in Kernel-based Virtual Machine (KVM), Binbin Zhang, Xiaolin Wang, Rongfeng Lai, Liang Yang, Zhenlin Wang,Yingwei Luo, Xiaoming Li)
(测试环境:两台物理服务器 HostA 和 HostB,都使用GB以太网。HostA 使用 82566DC 网卡,HostB 使用 82567LM-2 网卡,一台虚机运行在 HostB 上,使用 KVM-76.)
结论:
- 纯模拟网卡的性能只有物理网卡的四成到六成
- 纯模拟网卡的 UDP 性能比 TCP 性能高 50% 到 100%
- 在虚拟网卡上使用 NAPI,不但不会提高性能,反而会是性能下降
- e1000 的性能比 rt18139 的性能高不少(为什么 RedHat Linux KVM 上默认的网卡是 rt18139 呢?)
Virtio 和 vhost_net 的吞吐量比较:

- 来源:CANONICAL, KVM Performance Optimization, Paul Sim,Cloud Consultant, paul.sim@canonical.com
- 结论: vhost_net 比 virtio 的 UDP 和 TCP 性能高 20% 左右。
RedHat Linux 6 上 virtio,vhost_net,SR-IOV 和物理设备网络延迟的比较:

(来源:RedHat 官网)
RedHat Linux 6 上 virtio 和 vhost_net 所消耗的主机CPU资源的比较:

(来源同上)
使用 virtio 的 KVM 与物理机的 TCP 吞吐量对比:

(数据来源:RedHat 官网)
物理机与使用 SR-IOV 的 KVM 的网络性能对比:

(来源:同上)
物理机与使用 Pass-through 的KVM 的 TCP 性能对比:

(资料来源:Open Source Virtualization: KVM and Linux, Chris Wright, Principal Software Engineer, Red Hat,September 4, 2009)
3.3 Virtio 和 Pass-Through 的详细比较

(来源:Reconnaissance of Virtio: What’s new and how it’s all connected? by Mario Smarduch)
4. 综合结论
KVM 依赖的Intel/AMD 处理器的各种虚拟化扩展:
| 处理器 | CPU 虚拟化 | 内存虚拟化 | PCI Pass-through |
| Intel | VT-x | VPID,EPT | VT-d |
| AMD | AMD-V | ASID,NPT | IOMMU |
I/O 虚拟化方案的选择:
- I/O设备尽量使用准虚拟化(virtio 和 vhost_net)
- 如果需要实时迁移,不能使用 SR-IOV
- 对更高I/O要求又不需要实时迁移的,可以使用 SR-IOV
- 每种方案都有优势和不足,在特定环境下其性能有可能反而下降,因此在生产环境中使用各种虚拟化方式前需要经过完整测试
(5):libvirt 介绍
1. Libvirt 是什么
为什么需要Libvirt?
- Hypervisor 比如 qemu-kvm 的命令行虚拟机管理工具参数众多,难于使用。
- Hypervisor 种类众多,没有统一的编程接口来管理它们,这对云环境来说非常重要。
- 没有统一的方式来方便地定义虚拟机相关的各种可管理对象。
Libvirt提供了什么?
- 它提供统一、稳定、开放的源代码的应用程序接口(API)、守护进程 (libvirtd)和和一个默认命令行管理工具(virsh)。
- 它提供了对虚拟化客户机和它的虚拟化设备、网络和存储的管理。
- 它提供了一套较为稳定的C语言应用程序接口。目前,在其他一些流行的编程语言中也提供了对libvirt的绑定,在Python、Perl、Java、Ruby、PHP、OCaml等高级编程语言中已经有libvirt的程序库可以直接使用。
- 它对多种不同的 Hypervisor 的支持是通过一种基于驱动程序的架构来实现的。libvirt 对不同的 Hypervisor 提供了不同的驱动,包括 Xen 的驱动,对QEMU/KVM 有 QEMU 驱动,VMware 驱动等。在 libvirt 源代码中,可以很容易找到 qemu_driver.c、xen_driver.c、xenapi_driver.c、vmware_driver.c、vbox_driver.c 这样的驱动程序源代码文件。
- 它作为中间适配层,让底层 Hypervisor 对上层用户空间的管理工具是可以做到完全透明的,因为 libvirt 屏蔽了底层各种 Hypervisor 的细节,为上层管理工具提供了一个统一的、较稳定的接口(API)。
- 它使用 XML 来定义各种虚拟机相关的受管理对象。
目前,libvirt 已经成为使用最为广泛的对各种虚拟机进行管理的工具和应用程序接口(API),而且一些常用的虚拟机管理工具(如virsh、virt-install、virt-manager等)和云计算框架平台(如OpenStack、OpenNebula、Eucalyptus等)都在底层使用libvirt的应用程序接口。

 (SLE 11)
(SLE 11)
1.1 Libvirt C API
1.1.1 Libvirti API 所管理的主要对象
| 对象 | 解释 |
| Domain (域) | 指运行在由Hypervisor提供的虚拟机器上的一个操作系统实例(常常是指一个虚拟机)或者用来启动虚机的配置。 |
| Hypervisor | 一个虚拟化主机的软件层 |
| Node (主机) | 一台物理服务器。 |
| Storage pool (存储池) | 一组存储媒介的集合,比如物理硬盘驱动器。一个存储池被划分为小的容器称作卷。卷会被分给一个或者多个虚机。 |
| Volume (卷) | 一个从存储池分配的存储空间。一个卷会被分给一个或者多个域,常常成为域里的虚拟硬盘。 |
1.1.2 对象的管理模型
| 对象名称 | 对象 | Python 类 | 描述 |
| Connect | 与 Hypervisor的连接 | virConnectPtr | 在调用任何 API 去管理一个本地或者远端的Hypervisor前,必须建立和这个Hypervisor的连接。 |
| Domain | Guest domain | virDomainPtr | 用于列举和管理已有的虚机,或者创建新的虚机。唯一标识:ID,Name,UUID。一个域可能是暂时性的或者持久性的。暂时性的域只能在它运行期间被管理。持久性的域在主机上保存了它的配置。 |
| Virtual Network | 虚拟网络 | virNetworkPtr | 用于管理虚机的网络设备。唯一标识:Name,UUID。一个虚拟网络可能是暂时性的或者持久性的。每个主机上安装libvirt后,它都有一个默认的网络设备“default”。它向该主机上运行的虚机提供DHCP服务,以及通过NAT连接到主机上。 |
| Storage Pool | 存储池 | virStoragePoolPtr | 用于管理虚拟机内的所有存储,包括 local disk, logical volume group, iSCSI target, FibreChannel HBA and local/network file system。唯一标识:Name,UUID。一个存储池可能是暂时性的或者持久性的。Pool 的 type 可以是 dir, fs, netfs, disk, iscsi, logical, scsi,mpath, rbd, sheepdog, gluster 或者 zfs。 |
| Storage Volume | 存储卷 | virStorageVolPtr | 用于管理一个存储池内的存储块,包括一个池内分配的块、磁盘分区、逻辑卷、SCSI/iSCSI Lun,或者一个本地或者网络文件系统内的文件等。唯一标识:Name,Key,Path。 |
| Host device | 主机设备 | virNodeDevPtr | 用于管理主机上的物理硬件设备,包括 the physical USB or PCI devices and logical devices these provide, such as a NIC, disk, disk controller, sound card, etc。唯一标识:Name。 |
1.1.3 API 的简单分类
Libvirt API 就是对各种对象的各种操作,包括基本的增、删、改、查操作和其它操作。
| 对象 | 增 | 删 | 改 | 查 | 其它 |
| Connect | virConnectOpen virConnectOpenAuth virConnectOpenReadOnly | virConnectClose | virConnectSetKeepAlive | ||
| Strorage pool | virStoragePoolBuild virStoragePoolCreate virStoragePoolCreateXML virStoragePoolDefineXML | virStoragePoolDelete virStoragePoolDestroy virStoragePoolFree virStoragePoolUndefine | virStoragePoolRefresh virStoragePoolSetAutostart | virConnectFindStoragePoolSources virConnectListAllStoragePools virConnectListDefinedStoragePools virConnectListStoragePools virConnectNumOfDefinedStoragePools virConnectNumOfStoragePools virStoragePoolGetInfo/Name/UUID/UUIDString/XMLDesc virStoragePoolIsActive/Persistent virStoragePoolLookupByName/UUID/UUIDString/Volume virStoragePoolRef | virStoragePoolGetAutostart virStoragePoolGetConnect virStoragePoolNumOfVolumes virStoragePoolListAllVolumes virStoragePoolListVolumes |
| Storage volume | virStorageVolCreateXML virStorageVolCreateXMLFrom | virStorageVolDelete virStorageVolFree | virStorageVolResize virStorageVolUpload virStorageVolWipe virStorageVolWipePattern | virStorageVolGetConnect/Info/Key/Name/Path/XMLDesc virStorageVolLookupByKey/Name/Path virStorageVolRef | virStorageVolDownload |
| Network | virNetworkCreate virNetworkCreateXML virNetworkDefineXML | virNetworkDestroy virNetworkFree virNetworkUndefine | virNetworkSetAutostart virNetworkUpdate | virConnectListAllNetworks virConnectListDefinedNetworks virConnectListNetworks virConnectNumOfDefinedNetworks virConnectNumOfNetworks virNetworkGetBridgeName/DHCPLeases/Name/UUID/UUIDString/XMLDesc virNetworkIsActive/Persistent virNetworkLookupByName/UUID/UUIDString virNetworkGetAutostart virNetworkGetConnect | virConnectNetworkEventDeregisterAny virConnectNetworkEventGenericCallback virNetworkDHCPLeaseFree |
| Domain snapshot | virDomainSnapshotCreateXML | virDomainSnapshotDelete virDomainSnapshotFree | virDomainRevertToSnapshot | virDomainHasCurrentSnapshot virDomainListAllSnapshots virDomainSnapshotCurrent virDomainSnapshotGetConnect/Domain/Name/Parent/XMLDesc virDomainSnapshotHasMetadata virDomainSnapshotIsCurrent virDomainSnapshotListAllChildren virDomainSnapshotListChildrenNames virDomainSnapshotListNames virDomainSnapshotLookupByName virDomainSnapshotNum virDomainSnapshotNumChildren virDomainSnapshotRef | |
| Host | virInitialize virNodeSetMemoryParameters virNodeSuspendForDuration | virConnectBaselineCPU virConnectCompareCPU virConnectGetCPUModelNames/Capabilities/Hostname/LibVersion/MaxVcpus/Sysinfo/Type/URI/Version virConnectIsAlive virConnectIsEncrypted virConnectIsSecure virGetVersion virNodeGetCPUMap/CPUStats /CellsFreeMemory/FreeMemory/Info/MemoryParameters/MemoryStats / virNodeGetSecurityModel | virTypedParamsAddBoolean virTypedParamsAddDouble virTypedParamsAddFromString virTypedParamsAddInt virTypedParamsAddLLong virTypedParamsAddString virTypedParamsAddUInt virTypedParamsAddULLong virTypedParamsClear virTypedParamsFree virTypedParamsGet | ||
| Interface | virInterfaceCreate virInterfaceDefineXML | virInterfaceDestroy virInterfaceFree virInterfaceUndefine | virInterfaceChangeBegin virInterfaceChangeCommit virInterfaceChangeRollback | virConnectListAllInterfaces virConnectListDefinedInterfaces virConnectListInterfaces virConnectNumOfDefinedInterfaces virConnectNumOfInterfaces virInterfaceGetConnect virInterfaceGetMACString virInterfaceGetName virInterfaceGetXMLDesc virInterfaceIsActive virInterfaceLookupByMACString virInterfaceLookupByName virInterfaceRef | |
| Net Filter | virNWFilterDefineXML | virNWFilterFree virNWFilterUndefine | virConnectListAllNWFilters virConnectListNWFilters virConnectNumOfNWFilters virNWFilterGetName virNWFilterGetUUID virNWFilterGetUUIDString virNWFilterGetXMLDesc virNWFilterLookupByName virNWFilterLookupByUUID virNWFilterLookupByUUIDString virNWFilterRef | ||
| Domain Event | virConnectDomainEventDeregister virConnectDomainEventDeregisterAny virConnectDomainEventDeviceAddedCallback virConnectDomainEventDeviceRemovedCallback | virConnectDomainEventAgentLifecycleCallback virConnectDomainEventBalloonChangeCallback virConnectDomainEventBlockJobCallback virConnectDomainEventCallback virConnectDomainEventDiskChangeCallback virConnectDomainEventGenericCallback virConnectDomainEventGraphicsCallback virConnectDomainEventIOErrorCallback virConnectDomainEventIOErrorReasonCallback virConnectDomainEventPMSuspendCallback virConnectDomainEventPMSuspendDiskCallback | |||
| Domain | virDomainCreate virDomainCreateLinux virDomainCreateWithFiles virDomainCreateWithFlags virDomainCreateXML virDomainCreateXMLWithFiles virDomainDefineXML virDomainDefineXMLFlags | virDomainDestroy virDomainDestroyFlags virDomainFree virDomainUndefine virDomainUndefineFlags virDomainUpdateDeviceFlags | virDomainAbortJob virDomainAddIOThread virDomainDelIOThread virDomainAttachDevicevirDomainAttachDeviceFlags virDomainDetachDevice virDomainDetachDeviceFlags virDomainBlockCommit virDomainBlockCopy virDomainBlockJobAbort virDomainBlockJobSetSpeed virDomainBlockPeek virDomainBlockPull virDomainBlockRebase virDomainBlockResize virDomainCoreDump virDomainCoreDumpWithFormat virDomainFSFreeze virDomainFSInfoFree virDomainFSThaw virDomainFSTrim virDomainInjectNMI virDomainInterfaceFree virDomainManagedSave virDomainManagedSaveRemove virDomainMigrate virDomainMigrate2 virDomainMigrate3 virDomainMigrateSetCompressionCache virDomainMigrateSetMaxDowntime virDomainMigrateSetMaxSpeed virDomainMigrateToURI virDomainMigrateToURI2 virDomainMigrateToURI3 virDomainOpenChannel virDomainOpenConsole virDomainOpenGraphics virDomainOpenGraphicsFD virDomainPMSuspendForDuration virDomainPMWakeup virDomainReboot virDomainReset virDomainRestore virDomainRestoreFlags virDomainResume virDomainSave virDomainSaveFlags virDomainSaveImageDefineXML virDomainScreenshot virDomainSendKey virDomainSendProcessSignal virDomainShutdown virDomainSetBlkioParameters virDomainSetBlockIoTune virDomainSetInterfaceParameters virDomainSetMaxMemory virDomainSetMemory virDomainSetMemoryFlags virDomainSetMemoryParameters virDomainSetMemoryStatsPeriod virDomainSetMetadata virDomainSetNumaParameters virDomainSetSchedulerParameters virDomainSetSchedulerParametersFlags virDomainSetTime virDomainSetUserPassword virDomainSetVcpus virDomainSetVcpusFlags | virConnectGetAllDomainStats virConnectGetDomainCapabilities virConnectListAllDomains virConnectListDefinedDomains virConnectListDomains virConnectNumOfDefinedDomains virConnectNumOfDomains virDomainBlockStats virDomainBlockStatsFlags virDomainGetAutostart virDomainGetBlkioParameters virDomainGetBlockInfo virDomainGetBlockIoTune virDomainGetBlockJobInfo virDomainGetCPUStats virDomainGetConnect virDomainGetControlInfo virDomainGetDiskErrors virDomainGetEmulatorPinInfo virDomainGetFSInfo virDomainGetHostname virDomainGetID virDomainGetIOThreadInfo virDomainGetInfo virDomainGetInterfaceParameters virDomainGetJobInfo virDomainGetJobStats virDomainGetMaxMemory virDomainGetMaxVcpus virDomainGetMemoryParameters virDomainGetMetadata virDomainGetName virDomainGetNumaParameters virDomainGetOSType virDomainGetSchedulerParameters virDomainGetSchedulerParametersFlags virDomainGetSchedulerType virDomainGetSecurityLabel virDomainGetSecurityLabelList virDomainGetState virDomainGetTime virDomainGetUUID virDomainGetUUIDString virDomainGetVcpuPinInfo virDomainGetVcpus virDomainGetVcpusFlags virDomainGetXMLDesc virDomainHasManagedSaveImage virDomainIOThreadInfoFree virDomainInterfaceAddresses virDomainInterfaceStats virDomainIsActive virDomainIsPersistent virDomainIsUpdated virDomainListGetStats virDomainLookupByID virDomainLookupByName virDomainLookupByUUID virDomainLookupByUUIDString virDomainMemoryPeek virDomainMemoryStats virDomainMigrateGetCompressionCache virDomainMigrateGetMaxSpeed virDomainPinEmulator ? virDomainPinIOThread virDomainPinVcpu virDomainPinVcpuFlags virDomainSaveImageGetXMLDesc virDomainStatsRecordListFree | virConnectDomainXMLFromNative virConnectDomainXMLToNative |
| Secret | virSecretDefineXML | virSecretFree virSecretUndefine | virSecretSetValue | virConnectListAllSecrets virConnectListSecrets virConnectNumOfSecrets virSecretGetConnect/UUID/UUIDString/UsageID/UsageType/Value/XMLDesc virSecretLookupByUUID/UUIDString/Usage virSecretRef | |
| Stream | virStreamNew | virStreamFree | virStreamFinish virStreamAbort virStreamRecv virStreamRecvAll virStreamSend virStreamSendAll | virStreamSinkFunc virStreamSourceFunc |
1.2 Libvirt XML 定义
Libvirt 使用 XML 来定义各种对象,其中,与 OpenStack Nova 关系比较密切的有:
| disk (磁盘) | 任何磁盘设备,包括软盘(floppy)、硬盘(hard disk)、光驱(cdrom)或者半虚拟化驱动都使用 元素来定义。 方式:
(1)”volume“ 类型的 disk
| |
| Host device assignment (主机设备分配) |
| |
| Network interface (网卡) |
| |
| network (网络) | 1. bridge:定义一个用于构造该虚拟网络的网桥。 2. domain:定义 DHCP server 的 DNS domain。 3. forward: 定义虚拟网络直接连到物理 LAN 的方式. ”mode“指转发模式。 (1) mode=‘nat’:所有连接到该虚拟网络的虚拟的网络都会经过物理机器的网卡,并转换成物理网卡的地址。
也可以指定公共的IP地址和端口号。
(3) mode=‘bridge’:使用不受libvirt管理的bridge,比如主机上已有的bridge;open vswitch bridge;使用 macvtap's "bridge" 模式
(5) mode=‘hostdev’:直接分配主机上的网络设备。
|
详细的 XML 定义说明在 https://libvirt.org/format.html。
1.3 Libvirt API 的实现
libvirt API 的实现是在各个 Hypervisor driver 和 Storage dirver 内。Hypervisor 驱动包括:
- LXC - Linux Containers
- OpenVZ
- QEMU
- Test - Used for testing
- UML - User Mode Linux
- VirtualBox
- VMware ESX
- VMware Workstation/Player
- Xen
- Microsoft Hyper-V
- IBM PowerVM (phyp)
- Parallels
- Bhyve - The BSD Hypervisor
1.4 Libvirt 的 Python 绑定
python-libvirt 包含 Libvirt 的 Python 语言绑定。安装 libvirt 时,默认会安装 python-libvirt 。 来源: https://libvirt.org/python.html https://pypi.python.org/pypi/libvirt-python
Python API 和 C API 之间几乎是一对一的映射关系,比如:
-
#C API int virConnectNumOfDomains (virConnectPtr conn); int virDomainSetMaxMemory (virDomainPtr domain, unsigned long memory); -
#Python API virConnect::numOfDomains(self) virDomain::setMaxMemory(self, memory)
因此,libvirt 官网并没有提供详细的 python API 描述。
2. QEMU/KVM libvirt 驱动
2.1 架构

?Libvirtd 是一个 daemon 进程,可以被本地的virsh调用,也可以被远程的virsh调用
?Libvirtd 调用 qemu-kvm 操作KVM 虚拟机
这里有一个 virsh 命令、Libvirt C API、 QEMU driver 方法 和 QEMU Monitor 命令的对照表(部分):
| virsh command | Public API | QEMU driver function | Monitor command |
|---|---|---|---|
| virsh create XMLFILE | virDomainCreateXML() | qemudDomainCreate() | info cpus, cont, change vnc password, balloon (all indirectly) |
| virsh suspend GUEST | virDomainSuspend() | qemudDomainSuspend() | stop |
| virsh resume GUEST | virDomainResume() | qemudDomainResume() | cont |
| virsh shutdown GUEST | virDomainShutdown() | qemudDomainShutdown() | system_powerdown |
| virsh setmem GUEST MEM-KB | virDomainSetMemory() | qemudDomainSetMemory() | balloon (indirectly) |
| virsh dominfo GUEST | virDomainGetInfo() | qemudDomainGetInfo() | info balloon (indirectly) |
| virsh save GUEST FILENAME | virDomainSave() | qemudDomainSave() | stop, migrate exec |
| virsh restore FILENAME | virDomainRestore() | qemudDomainRestore() | cont |
| virsh dumpxml GUEST | virDomainDumpXML() | qemudDomainDumpXML() | info balloon (indirectly) |
| virsh attach-device GUEST XMLFILE | virDomainAttachDevice() | qemudDomainAttachDevice() | change, eject, usb_add, pci_add (all indirectly) |
| virsh detach-device GUEST XMLFILE | virDomainDetachDevice() | qemudDomainDetachDevice() | pci_del (indirectly) |
| virsh migrate GUEST DEST-URI | virDomainMigrate() | qemudDomainMigratePerform() | stop, migrate_set_speed, migrate, cont |
| virsh domblkstat GUEST | virDomainBlockStats() | qemudDomainBlockStats() | info blockstats |
| - | virDomainBlockPeek() | qemudDomainMemoryPeek() | memsave |
2.2 安装
有三种方式来安装 libvirt:
(1)下载 libvirt 的源代码,然后编译和安装
(2)从各 Linux 的发行版中直接安装,比如 Ubuntu 上运行 apt-get install libvirt-bin
(3)从 git 上克隆 libvirt 的代码,然后编译和安装
2.3 libvirt log
这篇文章 描述了 livbirt log。设置所有日志的方法是在 /etc/libvirt/libvirtd.conf 中添加下面的配置然后重启 libvirt:
log_filters="1:libvirt 1:util 1:qemu" log_outputs="1:file:/var/log/libvirt/libvirtd.log"3 使用 libvirt 编程来管理 KVM 虚机的实例
这里只描述基本的过程。具体的过程,下一篇文章会具体分析 Nova 中 libvirt 的使用。
- 定义虚机的基本配置,包括 vCPU、内存、磁盘或者cdrom以及启动顺序,生成 xml 配置,调用 virDomainCreateXML API 启动一个虚机
- 使用 Domain 相关的 API 来管理虚机的生命周期。我的这篇文章有虚机生命周期的详细介绍。
- 添加磁盘:定义一个 disk 的 xml 配置,使用 virDomainAttachDevice API 将它挂载到虚机上。如果不是本地的源磁盘,需要提前准备好。
- 添加interface:使用 Network API 定义一个虚拟网络(需要提前准备好物理网络),然后定义一个 interface 的 XML 配置,使用 virDomainAttachDevice API 将它加到虚机。
- 按照需要,重复2、3、4步骤。
(6):Nova 通过 libvirt 管理 QEMU/KVM 虚机
1. Libvirt 在 OpenStack 架构中的位置
在 Nova Compute 节点上运行的 nova-compute 服务调用 Hypervisor API 去管理运行在该 Hypervisor 的虚机。Nova 使用 libvirt 管理 QEMU/KVM 虚机,还使用别的 API 去管理别的虚机。


libvirt 的实现代码在 /nova/virt/libvirt/driver.py 文件中。
这里是 OpenStack Hypervisor Matrix。
这里是 每个 Linux 发行版里面 libvirt, QEMU/KVM 的版本号。
请注意Juno 版本 Nova 对 libvirt 和 QEMU 的各种最低版本要求:
| 功能 | 最低 libvirt 版本 | 最低 QEMU 版本 | 不支持的后果 |
| 所有 | 0.9.11 | Nova 不能使用 libvirt driver | |
| 支持 device callback | 1.1.1 | 不支持的话,就无法支持 Detach PCI/SR-IOV 设备 | |
| Live snapshot | 1.3.0 | 1.3.0 | 只能使用 Clod Snapshot |
| 挂载卷时设置卷的 block 大小(Block IO) | 0.10.2 | 不能使用的话,就不能设置卷的特定 block size,只能使用其默认的 block size。 | |
| Block Job Info | 1.1.1 | 不能在线删除卷的快照 (online deletion of volume snapshots) | |
| Discard | 1.0.6 | 1.6.0 | |
| NUMA topology | 1.0.4 | 无法获取 node 的 NUMA topology 信息,就无法将虚机的 vCPU 指定到特定的 node CPU 上,会影响虚机的性能 |
2. Nova 中 libvirt 的使用
Nova 使用 libvirt 来管理虚机,包括:
- 创建虚机
- 虚机的生命周期管理(参考这篇文档)
- 添加和删除连接到别的网络的网卡 (interface)
- 添加和删除 Cinder 卷 (volume)
2.1 创建 QEMU/KVM 虚机
创建虚机的配置有几个来源:
- 用户的选项,包括虚机的基本信息,比如 name,flavor,image,network,disk等。
- image 的属性,比如 hw_vif_model,hw_scsi_model 等。完整的供 libvirt API 使用的属性列表 在这里。
- 管理员在 nova.conf 中的配置
(注意:image 的元数据属性的优先级高于 nova.conf 中的配置。只有在没有property的情况下才使用nova.conf中的配置)
创建虚机的过程的几个主要阶段:
(1)消息由 nova-api 路由到某个 nova compute 节点 (API -> Scheduler -> Compute (manager) -> Libvirt Driver)
(2)调用 Neutron REST API 去准备网络。其返回的数据类似:
[VIF({'profile': {}, 'ovs_interfaceid': u'59cfa0b8-2f5c-481a-89a8-7a8711b368a2', 'network': Network({'bridge': 'br-int', 'subnets': [Subnet({'ips': [FixedIP({'meta': {}, 'version': 4, 'type': 'fixed', 'floating_ips': [], 'address': u'10.0.10.14'})], 'version': 4, 'meta': {'dhcp_server': u'10.0.10.11'}, 'dns': [], 'routes': [], 'cidr': u'10.0.10.0/24', 'gateway': IP({'meta': {}, 'version': 4, 'type': 'gateway', 'address': u'10.0.10.1'})})], 'meta': {'injected': False, 'tenant_id': u'74c8ada23a3449f888d9e19b76d13aab'}, 'id': u'a924e87a-826b-4109-bb03-523a8b3f6f9e', 'label': u'demo-net2'}), 'devname': u'tap59cfa0b8-2f', 'vnic_type': u'normal', 'qbh_params': None, 'meta': {}, 'details': {u'port_filter': True, u'ovs_hybrid_plug': True}, 'address': u'fa:16:3e:e0:30:e7', 'active': False, 'type': u'ovs', 'id': u'59cfa0b8-2f5c-481a-89a8-7a8711b368a2', 'qbg_params': None})](3)从 image 启动话,nova 会调用 Glane REST API 后者 image metadata 和准备本地启动盘
image metadata:
{u'status': u'active', u'deleted': False, u'container_format': u'bare', u'min_ram': 0, u'updated_at': u'2015-04-26T04:34:40.000000', u'min_disk': 0, u'owner': u'74c8ada23a3449f888d9e19b76d13aab', u'is_public': False, u'deleted_at': None, u'properties': {}, u'size': 13167616, u'name': u'image', u'checksum': u'64d7c1cd2b6f60c92c14662941cb7913', u'created_at': u'2015-04-26T04:34:39.000000', u'disk_format': u'qcow2', u'id': u'bb9318db-5554-4857-a309-268c6653b9ff'}本地启动盘:
{'disk_bus': 'virtio', 'cdrom_bus': 'ide', 'mapping': {'disk': {'bus': 'virtio', 'boot_index': '1', 'type': 'disk', 'dev': u'vda'}, 'root': {'bus': 'virtio', 'boot_index': '1', 'type': 'disk', 'dev': u'vda'}, 'disk.local': {'bus': 'virtio', 'type': 'disk', 'dev': 'vdb'}, 'disk.swap': {'bus': 'virtio', 'type': 'disk', 'dev': 'vdc'}}} 本地启动盘的文件信息:
-
root@compute2:/home/s1# qemu-img info /var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.local -
image: /var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.local -
file format: qcow2 -
virtual size: 1.0G (1073741824 bytes) #由 flavor.ephemeral_disk 指定其 size disk size: 324K -
cluster_size: 65536 -
backing file: /var/lib/nova/instances/_base/ephemeral_1_default -
Format specific information: -
compat: 1.1 -
lazy refcounts: false -
root@compute2:/home/s1# qemu-img info /var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.swap -
image: /var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.swap -
file format: qcow2 -
virtual size: 30M (31457280 bytes) # 由 flavor.swap_disk 指定其size disk size: 196K -
cluster_size: 65536 -
backing file: /var/lib/nova/instances/_base/swap_30 -
Format specific information: -
compat: 1.1 -
lazy refcounts: false
(4)根据这些信息,生成 domain xml,然后生成其配置使得它是一个持久性虚机 (调用 libvirt Python DefineXML API)。
一个从 image 启动的 Domain 的配置 XML 实例(蓝色部分是注释说明):
-
<domain type="qemu"> -
8352e969-0a25-4abf-978f-d9d0ec4de0cd -
instance-0000002f -
51200 # guest.memory = flavor.memory_mb * units.Ki 即 50 * 1024 = 51200 <vcpu cpuset="0">1 #flavor.vcpus -
<nova:instance xmlns:nova="http://openstack.org/xmlns/libvirt/nova/1.0"> -
<nova:package version="2014.2.2"/> -
vm11 #input.name 2015-06-09 23:54:04 -
<nova:flavor name="tiny2"> #input.flavor 50 -
1 -
30 -
1 -
1 -
<nova:user uuid="bcd37e6272184f34993b4d7686ca4479">admin -
<nova:project uuid="74c8ada23a3449f888d9e19b76d13aab">admin -
<nova:root type="image" uuid="bb9318db-5554-4857-a309-268c6653b9ff"/> #input.source -
<sysinfo type="smbios"> # Nova 中写死的 -
<entry name="manufacturer">OpenStack Foundation -
<entry name="product">OpenStack Nova -
<entry name="version">2014.2.2 -
<entry name="serial">03bb1a0f-ae04-4765-9f3c-d200a2540675 -
<entry name="uuid">8352e969-0a25-4abf-978f-d9d0ec4de0cd -
hvm #表示 Guest OS 需要 full virtualiaiton 支持 <boot dev="hd"/> #指定启动盘 <smbios mode="sysinfo"/> #去读取 的定义 -
# Soft Reboot 需要 ACPI 的支持,否则只能使用 Hard reboot。 https://bugs.launchpad.net/horizon/+bug/1346741 # 没 APIC 的话,Windows Guest 会在 Xen 或者 KVM 上崩溃。 https://bugs.launchpad.net/nova/+bug/1086352 -
<clock offset="utc"/> #如果Guest OS 是 MS,则是 localtime,否则都是 utc <cpu mode="host-model" match="exact"> # 对于 KVM,如果 CONF.libvirt.cpu_mode 是 none,mode 则设为 "host-model"。具体可参考 https://wiki.openstack.org/wiki/LibvirtXMLCPUModel <topology sockets="1" cores="1" threads="1"/> #默认的时候,sockets 数目设为 vcpu 的数目,cores 和 threads 都设为 1. 可以通过设置 image 的 hw_cpu_topology 属性来改变这里的设置,具体请参考 https://blueprints.launchpad.net/nova/+spec/support-libvirt-vcpu-topology 以及 https://wiki.openstack.org/wiki/VirtDriverGuestCPUMemoryPlacement -
<disk type="file" device="disk"> # 从 image 启动时候的启动盘(flavor.root_disk) <driver name="qemu" type="qcow2" cache="none"/> -
<source file="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk"/> -
<target bus="virtio" dev="vda"/> #对于 KVM,disk 的 bus 为 "virtio",cdrom 的 bus 为 "ide",floppy 的 bus 为 "fdc" -
<disk type="file" device="disk"> #临时分区 (falvor.ephemeral_disk) <driver name="qemu" type="qcow2" cache="none"/> -
<source file="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk.local"/> -
<target bus="virtio" dev="vdb"/> -
<disk type="file" device="disk"> #swap 分区 (flavor.swap_disk) <driver name="qemu" type="qcow2" cache="none"/> -
<source file="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk.swap"/> -
<target bus="virtio" dev="vdc"/> -
<interface type="bridge"> # 虚机通过网桥连接到 OVS <mac address="fa:16:3e:e0:30:e7"/> -
<model type="virtio"/> #该 type 可以由 image metadata hw_vif_type 指定。未指定的话,如果配置了 conf.libvirt.use_virtio_for_bridges = true (默认就是 true)的话,QEMU/KVM 会使用 virtio 类型。 <driver name="qemu"/> -
<source bridge="qbr59cfa0b8-2f"/> #qbr59cfa0b8-2f 连接虚机的 vNIC tap59cfa0b8-2f 和 qvb59cfa0b8-2f ,而 qvb59cfa0b8-2f 练到 OVS 的 br-int 上。 <target dev="tap59cfa0b8-2f"/> -
</interface> -
<serial type="file"> 当 CONF.serial_console.enabled = true 时,type 为 "tcp",使用 config 配置,其 XML 为 ;当为 false 时,使用 console.log 文件,type 为 file。 <source path="/var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/console.log"/> -
<serial type="pty"/> #每个domain都有 type 为 "pty" 的 serial 配置。 <input type="tablet" bus="usb"/> #当 CONF.vnc_enabled = true 或者 CONF.spice.enabled = true 并且 CONF.spice.agent_enabled = false 时添加 tablet,type 和 bus 都是固定的。 <graphics type="vnc" autoport="yes" keymap="en-us" listen="0.0.0.0"/> #如果 CONF.vnc_enabled = true,那么 keymap=CONF.vnc_keymap;listen=CONF.vncserver_listen #如果 CONF.vnc_enabled 或者 CONF.spice.enabled,则添加该 video 配置 <model type="cirrus"/> #如果 CONF.spice.enabled,则 type 为 qxl;否则为 cirrus。 -
<memballoon model="virtio"> #如果 CONF.libvirt.mem_stats_period_seconds >0 则添加 memballoon;对 KVM,model 固定为 "virtio" <stats period="10"/>
从 bootable volume 启动的话,disk 部分为:
-
<disk type="file" device="disk"> -
<driver name="qemu" type="qcow2" cache="none"/> -
<source file="/var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.local"/> -
<target bus="virtio" dev="vdb"/> -
<disk type="file" device="disk"> -
<driver name="qemu" type="qcow2" cache="none"/> -
<source file="/var/lib/nova/instances/02699155-940f-4401-bc01-36220db80639/disk.swap"/> -
<target bus="virtio" dev="vdc"/> -
26446902-5a56-4c79-b839-a8e13a66dc7a
(5). 启动 domain (调用 libvirt Python createWithFlags API)
2.2 添加 volume 到虚机 (nova volume-attach)
(1)使用 volume id 通过 volume driver 找到指定的 volume
(2)调用 volume driver 来建立主机和 Volume 之间的连接
主机信息为:
{'ip': '192.168.1.15', 'host': 'compute2', 'initiator': 'iqn.1993-08.org.debian:01:a9f2b45c24f9'} 建立的 iSCSI 连接信息为:
{u'driver_volume_type': u'iscsi', u'data': {u'access_mode': u'rw', u'target_discovered': False, u'encrypted': False, u'qos_specs': None, u'target_iqn': u'iqn.2010-10.org.openstack:volume-51da0d1f-0a17-4e7f-aeff-27438963348a', u'target_portal': u'10.0.2.41:3260', u'volume_id': u'51da0d1f-0a17-4e7f-aeff-27438963348a', u'target_lun': 1, u'auth_password': u'hXG64qrzEjNt8MDKnERA', u'auth_username': u'fKSAe6vhgyeG88U9kcBV', u'auth_method': u'CHAP'}} volume 在主机上的磁盘为:
root@compute2:/home/s1# ls /dev/disk/by-path/ -ls
total 0
0 lrwxrwxrwx 1 root root 9 Jun 10 12:18 ip-10.0.2.41:3260-iscsi-iqn.2010-10.org.openstack:volume-51da0d1f-0a17-4e7f-aeff-27438963348a-lun-1 -> ../../sdc
Disk /dev/sdc: 1073 MB, 1073741824 bytes
34 heads, 61 sectors/track, 1011 cylinders, total 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Disk /dev/sdc doesn't contain a valid partition table
(3)通过 domain name 来找到指定 domain 对象 (通过调用 lookupByName API)
(4)生成 volume 连接的配置 xml,比如:
51da0d1f-0a17-4e7f-aeff-27438963348a
(5)调用 attachDeviceFlags API 将 volume 挂载到该虚机
2.3 添加连接到新的网络的 interface 给虚机 (nova interface-attach)
(1)运行 nova interface-attach,传入 network-id,Neutron 会分配如下network info 给 Nova
VIF({'profile': {}, 'ovs_interfaceid': u'0142efee-7382-43ef-96e8-d0084ecc893c', 'network': Network({'bridge': u'br-int', 'subnets': [Subnet({'ips': [FixedIP({'meta': {}, 'version': 4, 'type': u'fixed', 'floating_ips': [], 'address': u'10.0.0.40'})], 'version': 4, 'meta': {u'dhcp_server': u'10.0.0.3'}, 'dns': [], 'routes': [], 'cidr': u'10.0.0.0/24', 'gateway': IP({'meta': {}, 'version': 4, 'type': u'gateway', 'address': u'10.0.0.1'})})], 'meta': {u'injected': False, u'tenant_id': u'74c8ada23a3449f888d9e19b76d13aab'}, 'id': u'01630966-b21f-4a6d-95ff-10c4575f1fe2', 'label': u'demo-net'}), 'devname': u'tap0142efee-73', 'vnic_type': u'normal', 'qbh_params': None, 'meta': {}, 'details': {u'port_filter': True, u'ovs_hybrid_plug': True}, 'address': u'fa:16:3e:14:32:d9', 'active': True, 'type': u'ovs', 'id': u'0142efee-7382-43ef-96e8-d0084ecc893c', 'qbg_params': None})(2)执行下面的命令,将 Neutron 分配的 port 连接到 OVS
-
#添加 linux bridge -
brctl addbr qbr0142efee-73 #名字是 devname 的后半部分 brctl setfd qbr0142efee-73 0 brctl stp qbr0142efee-73 off -
tee /sys/class/net/qbr0142efee-73/bridge/multicast_snooping -
ip link add qvb0142efee-73 type veth peer name qvo0142efee-73 ip link set qvb0142efee-73 ip link set qvb0142efee-73 promisc on -
#在 OVS 上添加端口 -
ovs-vsctl --timeout=120 -- --if-exists del-port qvo0142efee-73 -- add-port br-int qvo0142efee-73 -- set Interface qvo0142efee-73 external-ids:iface-id=0142efee-7382-43ef-96e8-d0084ecc893c external-ids:iface-status=active external-ids:attached-mac=fa:16:3e:14:32:d9 external-ids:vm-uuid=8352e969-0a25-4abf-978f-d9d0ec4de0cd
(3)生成 interface 配置的xml,比如:
(4)调用 attachDeviceFlags API 来挂载该 interface 到虚机
至于其他的虚机操作,会在另一篇文章中描述。
(7):使用 libvirt 做 QEMU/KVM 快照和 Nova 实例的快照
本文将梳理 QEMU/KVM 快照相关的知识,以及在 OpenStack Nova 中使用 libvirt 来对 QEMU/KVM 虚机做快照的过程。
1. QEMU/KVM 快照
1.1 概念
QEMU/KVM 快照的定义:
- 磁盘快照:磁盘的内容(可能是虚机的全部磁盘或者部分磁盘)在某个时间点上被保存,然后可以被恢复。
- 磁盘数据的保存状态:
- 在一个运行着的系统上,一个磁盘快照很可能只是崩溃一致的(crash-consistent) 而不是完整一致(clean)的,也是说它所保存的磁盘状态可能相当于机器突然掉电时硬盘数据的状态,机器重启后需要通过 fsck 或者别的工具来恢复到完整一致的状态(类似于 Windows 机器在断电后会执行文件检查)。
- 对一个非运行中的虚机来说,如果上次虚机关闭的时候磁盘是完整一致的,那么其被快照的磁盘快照也将是完整一致的。
- 磁盘快照有两种:
- 内部快照 - 使用单个的 qcow2 的文件来保存快照和快照之后的改动。这种快照是 libvirt 的默认行为,现在的支持很完善(创建、回滚和删除),但是只能针对 qcow2 格式的磁盘镜像文件,而且其过程较慢等。
- 外部快照 - 快照是一个只读文件,快照之后的修改是另一个 qcow2 文件中。外置快照可以针对各种格式的磁盘镜像文件。外置快照的结果是形成一个 qcow2 文件链:original <- snap1 <- snap2 <- snap3。http://wiki.libvirt.org/page/Qemu_guest_agent
快照还可以分为 live snapshot(热快照)和 Clod snapshot:
- Live snapshot:系统运行状态下做的快照
- Cold snapshot:系统停止状态下的快照
libvit 做 snapshot 的各个 API:
snapshot 做快照的 libvirt API 从快照恢复的 libvirt API virsh 命令 磁盘快照 virDomainSnapshotCreateXML(flags = VIR_DOMAIN_SNAPSHOT_CREATE_DISK_ONLY ) virDomainRevertToSnapshot virsh snapshot-create/snapshot-revert 内存(状态)快照 virDomainSave
virDomainSaveFlags
virDomainManagedSave
virDomainRestore
virDomainRestoreFlags
virDomainCreate
virDomainCreateWithFlags
virsh save/restore系统检查点 virDomainSnapshotCreateXML virDomainRevertToSnapshot virsh snapshot-create/snapshot-revert 分别来看看这些 API 是如何工作的:
1. virDomainSnapshotCreateXML (virDomainPtr domain, const char * xmlDesc, unsigned int flags)
作用:根据 xmlDesc 指定的 snapshot xml 和 flags 来创建虚机的快照。
flags 包含 虚机处于运行状态时快照的做法 虚机处于关闭状态时快照的做法 0 创建系统检查点,包括磁盘状态和内存状态比如内存内容 保持关机时的磁盘状态 VIR_DOMAIN_SNAPSHOT_CREATE_LIVE 做快照期间,虚机将不会被 paused。这会增加内存 dump file 的大小,但是可以减少系统停机时间。部分 Hypervisor 只在做外部的系统检查点时才设置该 flag,这意味着普通快照还是需要暂停虚机。 VIR_DOMAIN_SNAPSHOT_CREATE_DISK_ONLY 只做指定磁盘的快照。对应运行着的虚机,磁盘快照可能是不完整的(类似于突然电源被拔了的情形)。 只做指定磁盘的快照。 其内部实现根据虚机的运行状态有两种情形:
- 对运行着的虚机,API 使用 QEMU Monitor 去做快照,磁盘镜像文件必须是 qcow2 格式,虚机的 CPU 被停止,快照结束后会重新启动。
- 对停止着的虚机,API 调用 qemu-img 方法来操作所有磁盘镜像文件。
这里有其实现代码,可见其基本的实现步骤:
-
static virDomainSnapshotPtr qemuDomainSnapshotCreateXML -
{ -
.... -
call qemuDomainSnapshotCreateDiskActive -
{ -
call qemuProcessStopCPUs # 停止 vCPUs for each disk call qemuDomainSnapshotCreateSingleDiskActive -
{ -
call qemuMonitorDiskSnapshot # 调用 QEMU Monitor 去为每个磁盘做snapshot } -
call qemuProcessStartCPUs # 启动 vCPUs } .... }
2. virDomainSave 相关的几个 API
这几个API 功能都比较类似:
virDomainSave 该方法会 suspend 一个运行着的虚机,然后保存期内存内容到一个文件中。成功调用以后,domain 将不会处于 running 状态。使用 virDomainRestore 来恢复虚机。 virDomainSaveFlags 类似于 virDomainSave API,可使用几个 flags。一些 Hypervisor 在调用该方法前需要调用 virDomainBlockJobAbort() 方法来停止 block copy 操作。 virDomainManagedSave 也类似于 virDomainSave API。主要区别是 libvirt 将其内存保存到一个受 libvirt 管理的文件中,因此libvirt 可以一直跟踪 snapshot 的状态;当调用 virDomainCreate/virDomainCreateWithFlags 方法重启该 domain的时候,libvirt 会使用该受管文件,而不是一个空白的文件,这样就可以 restore 该snapshot。 Features/SnapshotsMultipleDevices 这篇文章讨论同时对多个磁盘做快照的问题。
1.2 使用 virsh 实验
1.2.1 virsh save 命令
对运行中的 domain d-2 运行 “virsh save” 命令。命令执行完成后,d-2 变成 “shut off” 状态。

看看 domain 的磁盘镜像文件和 snapshot 文件:

内存数据被保存到 raw 格式的文件中。
要恢复的时候,可以运行 “vish restore d-2.snap1” 命令从保存的文件上恢复。
1.2.2 virsh snapshot-create/snapshort-create-as
先看看它的用法:
-
virsh # help snapshot-create-as -
NAME -
snapshot-create-as - Create a snapshot from a set of args -
SYNOPSIS -
snapshot-create-as [] [] [--print-xml] [--no-metadata] [--halt] [--disk-only] [--reuse-external] [--quiesce] [--atomic] [--live] [--memspec ] [[--diskspec] ]... -
DESCRIPTION -
Create a snapshot (disk and RAM) from arguments -
OPTIONS -
[--domain] domain name, id or uuid -
[--name] name of snapshot -
[--description] description of snapshot -
--print-xml print XML document rather than create -
--no-metadata take snapshot but create no metadata -
--halt halt domain after snapshot is created -
--disk-only capture disk state but not vm state -
--reuse-external reuse any existing external files -
--quiesce quiesce guest's file systems -
--atomic require atomic operation -
--live take a live snapshot -
--memspec memory attributes: [file=]name[,snapshot=type] -
[--diskspec] disk attributes: disk[,snapshot=type][,driver=type][,file=name]
其中一些参数,比如 --atomic,在一些老的 QEMU libary 上不支持,需要更新它到新的版本。根据 这篇文章,atomic 应该是 QEMU 1.0 中加入的。
(1)默认的话,该命令创建虚机的所有磁盘和内存做内部快照,创建快照时虚机处于 paused 状态,快照完成后变为 running 状态。持续时间较长。
-
<memory snapshot='internal'/> -
<disk name='vda' snapshot='internal'/> -
<disk name='vdb' snapshot='internal'/> -
<disk name='vdc' snapshot='internal'/> -

每个磁盘的镜像文件都包含了 snapshot 的信息:
-
root@compute1:/var/lib/nova/instances/eddc46a8-e026-4b2c-af51-dfaa436fcc7b# qemu-img info disk -
image: disk -
file format: qcow2 -
virtual size: 1.0G (1073741824 bytes) -
disk size: 43M -
cluster_size: 65536 -
backing file: /var/lib/nova/instances/_base/fbad3d96a1727069346073e51d5bbb1824e76e34 Snapshot list: -
ID TAG VM SIZE DATE VM CLOCK -
1 1433950148 41M 2015-06-10 23:29:08 05:16:55.007 Format specific information: -
compat: 1.1 -
lazy refcounts: false
你可以运行 snapshot-revert 命令回滚到指定的snapshot。
virsh # snapshot-revert instance-0000002e 1433950148根据 这篇文章,libvirt 将内存状态保存到某一个磁盘镜像文件内 (”state is saved inside one of the disks (as in qemu's 'savevm'system checkpoint implementation). If needed in the future,we can also add an attribute pointing out _which_ disk saved the internal state; maybe disk='vda'.)
(2)可以使用 “--memspec” 和 “--diskspec” 参数来给内存和磁盘外部快照。这时候,在获取内存状态之前需要 Pause 虚机,就会产生服务的 downtime。
-
virsh # snapshot-create-as 0000002e livesnap2 --memspec /home/s1/livesnap2mem,snapshot=external --diskspec vda,snapshot=external -
Domain snapshot livesnap2 created -
virsh # snapshot-dumpxml 0000002e livesnap2 <driver type='qcow2'/> -
<source file='/home/s1/testvm/testvm1.livesnap2'/>
(3)可以使用 “--disk-only” 参数,这时会做所有磁盘的外部快照,但是不包含内存的快照。不指定快照文件名字的话,会放在原来的磁盘文件所在的目录中。多次快照后,会形成一个外部快照链,新的快照使用前一个快照的镜像文件作为 backing file。
-
virsh # snapshot-list instance-0000002e --tree 1433950148 #内部快照 1433950810 #内部快照 1433950946 #内部快照 snap1 #第一个外部快照 | -
+- snap2 #第二个外部快照 | -
+- 1433954941 #第三个外部快照 | -
+- 1433954977 #第四个外部快照
而第一个外部快照的镜像文件是以虚机的原始镜像文件作为 backing file 的:
-
root@compute1:/var/lib/nova/instances/eddc46a8-e026-4b2c-af51-dfaa436fcc7b# qemu-img info disk.snap1 -
image: disk.snap1 -
file format: qcow2 -
virtual size: 30M (31457280 bytes) -
disk size: 196K -
cluster_size: 65536 -
backing file: /var/lib/nova/instances/eddc46a8-e026-4b2c-af51-dfaa436fcc7b/disk.swap #虚机的 swap disk 原始镜像文件 backing file format: qcow2 -
Format specific information: -
compat: 1.1 -
lazy refcounts: false
目前还不支持回滚到某一个extrenal disk snapshot。这篇文章 谈到了一个workaround。
[root@rh65 osdomains]# virsh snapshot-revert d-2 1434467974
error: unsupported configuration: revert to external disk snapshot not supported yet(4)还可以使用 “--live” 参数创建系统还原点,包括磁盘、内存和设备状态等。使用这个参数时,虚机不会被 Paused(那怎么实现的?)。其后果是增加了内存 dump 文件的大小,但是减少了系统的 downtime。该参数只能用于做外部的系统还原点(external checkpoint)。
-
virsh # snapshot-create-as 0000002e livesnap3 --memspec /home/s1/livesnap3mem,snapshot=external --diskspec vda,snapshot=external --live Domain snapshot livesnap3 created -
virsh # snapshot-dumpxml 0000002e livesnap3 <memory snapshot='external' file='/home/s1/livesnap3mem'/> -
<disk name='vda' snapshot='external' type='file'> -
<driver type='qcow2'/> -
<source file='/home/s1/testvm/testvm1.livesnap3'/>
注意到加 “--live” 生成的快照和不加这个参数生成的快照不会被链在一起:
-
virsh # snapshot-list 0000002e --tree livesnap1 #没加 --live | -
+- livesnap2 #没加 --live livesnap3 #加了 --live | -
+- livesnap4 #加了 --live
不过,奇怪的是,使用 QEMU 2.3 的情况下,即使加了 --live 参数,虚机还是会被短暂的 Paused 住:
-
[root@rh65 ~]# virsh snapshot-create-as d-2 --memspec /home/work/d-2/mem3,snapshot=external --diskspec hda,snapshot=external --live -
Domain snapshot 1434478667 created -
[root@rh65 ~]# virsh list --all -
Id Name State ---------------------------------------------------- 40 osvm1 running 42 osvm2 running 43 d-2 running -
[root@rh65 ~]# virsh list --all -
Id Name State ---------------------------------------------------- 40 osvm1 running 42 osvm2 running 43 d-2 paused # 不是说好我用 --live 你就不pause 虚机的么?这是肿了么。。 [root@rh65 ~]# virsh list --all -
Id Name State ---------------------------------------------------- 40 osvm1 running 42 osvm2 running 43 d-2 running
综上所述,对于 snapshot-create-as 命令来说,
参数 结果 所有磁盘和内存的内部的内部快照 --memspec snapshot=external --diskspec vda,snapshot=external磁盘和内存的外部快照,虚机需要被暂停 --live --memspec snapshot=external --diskspec vda,snapshot=external 创建系统检查点(包括磁盘和内存的快照),而且虚机不会被暂停(?测试结果显示还是会暂停,只是暂停时间比不使用 --live 要短一些) --disk-only 创建所有或者部分磁盘的外部快照 可以使用 sanpshot-revert 命令来回滚到指定的系统还原点,不过得使用 “-force” 参数:
-
[root@rh65 ~]# virsh snapshot-revert d-2 1434478313 error: revert requires force: Target device address type none does not match source pci -
[root@rh65 ~]# virsh snapshot-revert d-2 1434478313 --force -
[root@rh65 ~]#
1.3 外部快照的删除
目前 libvirt 还不支持直接删除一个外部快照,可以参考 这篇文章 介绍的 workaround。
2. OpenStack 中的快照
OpenStack Snapshot 可分为下面的几种情形:
2.1 对 Nova Instance 进行快照
(1)对从镜像文件启动的虚机做快照
- 只将运行当中的虚机的 Root disk (第一个vd 或者 hd disk) 做成 image,然后上传到 glance 里面
- Live Snapshot:对满足特定条件(QEMU 1.3+ 和 Libvirt 1.0.0+,以及 source_format not in ('lvm', 'rbd') and not CONF.ephemeral_storage_encryption.enabled and not CONF.workarounds.disable_libvirt_livesnapshot,以及能正常调用 libvirt.blockJobAbort ,其前提条件可参考这文章)的虚机,会进行 Live snapshot。Live Snapshot 允许用户在虚机处于运行状态时不停机做快照。
- Cold Snapshot:对不能做 live snapshot 的虚机做 Cold snapshot。这种快照必须首先 Pause 虚机。
(2)对从卷启动的虚机做快照
- 对虚机的每个挂载的 volume 调用 cinder API 做 snapshot。
- Snapshot 出的 metadata 会保存到 glance 里面,但是不会有 snapshot 的 image 上传到 Glance 里面。
- 这个 snapshot 也会出现在 cinder 的数据库里面,对 cinder API 可见。
2.2 对卷做快照
- 调用 cinder driver api,对 backend 中的 volume 进行 snapshot。
- 这个 snapshot 会出现在 cinder 的数据库里面,对 cinder API 可见。
3. 从镜像文件启动的 Nova 虚机做快照
严格地说,Nova 虚机的快照,并不是对虚机做完整的快照,而是对虚机的启动盘(root disk,即 vda 或者 hda)做快照生成 qcow2 格式的文件,并将其传到 Glance 中,其作用也往往是方便使用快照生成的镜像来部署新的虚机。Nova 快照分为 Live Snapshot (不停机快照)和 Clold Snapshot (停机快照)。
3.1 Nova Live Snapshot
满足 2.1.1 中所述条件时,运行命令 ”nova image-create “ 后,Nova 会执行 Live Snapshot。其过程如下:
- 找到虚机的 root disk (vda 或者 hda)。
- 在 CONF.libvirt.snapshots_directory 指定的文件夹(默认为 /var/lib/nova/instances/snapshots)中创建一个临时文件夹,在其中创建一个 qcow2 格式的 delta 文件,其文件名为 uuid 字符串,该文件的 backing file 和 root disk 文件的 backing file 相同 (下面步骤 a)。
- 调用 virDomainGetXMLDesc 来保存 domain 的 xml 配置。
- 调用 virDomainBlockJobAbort 来停止对 root disk 的活动块操作 (Cancel the active block job on the given disk)。
- 调用 virDomainUndefine 来将 domain 变为 transimit 类型的,这是因为 BlockRebase API 不能针对 Persistent domain 调用。
- 调用 virDomainBlockRebase 来将 root disk image 文件中不同的数据拷贝到 delta disk file 中。(下面步骤 b)
- 步骤 6 是一个持续的过程,因为可能有应用正在向该磁盘写数据。Nova 每隔 0.5 秒调用 virDomainBlockJobInfo API 来检查拷贝是否结束。
- 拷贝结束后,调用 virDomainBlockJobAbort 来终止数据拷贝。
- 调用 virDomainDefineXML 将domain 由 transimisit 该回到 persistent。
- 调用 qemu-img convert 命令将 delta image 文件和 backing file 变为一个 qcow2 文件 (下面步骤 c)
- 将 image 的元数据和 qcow2 文件传到 Glance 中。
(a)执行 qemu-img create -f qcow2 (qemu-img create 创建一个基于镜像1的镜像2,镜像2的文件将基于镜像1,镜像2中的文件将基于镜像1中的。在镜像2中所作的任何读写操作都不会影响到镜像1. 镜像1可以被其他镜像当做backing file. 但是要确保镜像1不要被修改)。比如: qemu-img create -f qcow2 -o backing_file=/var/lib/nova/instances/_base/ed39541b2c77cd7b069558570fa1dff4fda4f678,size=21474836480 /var/lib/nova/instances/snapshots/tmpzfjdJS/7f8d11be9ff647f6b7a0a643fad1f030.delta(b)相当于执行 virsh blockjob [--abort] [--async] [--pivot] [--info] [](c)执行 'qemu-img convert -f qcow2 -o dest_fmt' 来将带 backing file 的 qcow2 image 转化成不带 backing file 的 flat image。其中 dest_fmt 由 snapshot_image_format 决定,有效值是 raw, qcow2, vmdk, vdi,默认值是 source image 的 format。比如: qemu-img convert -f qcow2 -O qcow2 /var/lib/nova/instances/snapshots/tmpzfjdJS/7f8d11be9ff647f6b7a0a643fad1f030.delta /var/lib/nova/instances/snapshots/tmpzfjdJS/7f8d11be9ff647f6b7a0a643fad1f030来看看其中的一个关键 API int virDomainBlockRebase (virDomainPtr dom, const char * disk, const char * base, unsigned long bandwidth,unsigned int flags)
该 API 从 backing 文件中拷贝数据,或者拷贝整个 backing 文件到 @base 文件。Nova 中的调用方式为:domain.blockRebase(disk_path, disk_delta, 0,libvirt.VIR_DOMAIN_BLOCK_REBASE_COPY |libvirt.VIR_DOMAIN_BLOCK_REBASE_REUSE_EXT |libvirt.VIR_DOMAIN_BLOCK_REBASE_SHALLOW)默认的话,该 API 会拷贝整个@disk 文件到 @base 文件,但是使用 VIR_DOMAIN_BLOCK_REBASE_SHALLOW 的话就只拷贝差异数据(top data)因为 @disk 和 @base 使用相同的 backing 文件。 VIR_DOMAIN_BLOCK_REBASE_REUSE_EXT 表示需要使用已经存在的 @base 文件因为 Nova 会预先创建好这个文件。简单的示意图:

这里 有个过程的 PoC 代码描述该过程。
这里 有该过程的完整 libvirt 日志分析。
这里 有文章讲 Libvirt Features/SnapshotsMultipleDevices。
3.2 Nova Cold Snapshot
当虚机不在运行中时或者不满足 live snapshot 的条件的情况下,Nova 会执行 Cold snapshot。其主要过程如下:
(1)当虚机处于 running 或者 paused 状态时:
- detach PCI devices
- detach SR-IOV devices
- 调用 virDomainManagedSave API 来将虚机 suspend 并且将内存状态保存到磁盘文件中。
(2)调用 qemu-img convert 命令将 root disk 的镜像文件转化一个相同格式的镜像文件。
(3)调用 virDomainCreateWithFlags API 将虚机变为初始状态
(4)将在步骤1 中卸载的 PCI 和 SR-IOV 设备重新挂载回来
(5)将元数据和 qcow2 文件传到 Glance 中
4. 从 volume 启动的 Nova 实例的快照
(0)从卷启动虚机,并且再挂载一个卷,然后运行 nova image-create 命令。
-
| image | Attempt to boot from volume - no image supplied | -
| key_name | - | -
| metadata | {} | -
| name | vm10 | -
| os-extended-volumes:volumes_attached | [{"id": "26446902-5a56-4c79-b839-a8e13a66dc7a"}, {"id": "de127d46-ed92-471d-b18b-e89953c305fd"}]
(1)从 DB 获取该虚机的块设备( Block Devices Mapping)列表。
(2)对该列表中的每一个卷,依次调用 Cinder API 做快照。对 LVM Driver 的 volume 来说,执行的命令类似于 " lvcreate --size 100M --snapshot --name snap /dev/vg00/lvol1“。
-
s1@controller:~$ cinder snapshot-list +--------------------------------------+--------------------------------------+-----------+------------------------+------+ -
| ID | Volume ID | Status | Name | Size | -
+--------------------------------------+--------------------------------------+-----------+------------------------+------+ -
| a7c591fb-3413-4548-abd8-86753da3158b | de127d46-ed92-471d-b18b-e89953c305fd | available | snapshot for vm10-snap | 1 | -
| d1277ea9-e972-4dd4-89c0-0b9d74956247 | 26446902-5a56-4c79-b839-a8e13a66dc7a | available | snapshot for vm10-snap | 1 | -
+--------------------------------------+--------------------------------------+-----------+------------------------+------+
(3)将快照的 metadata 放到 Glance 中。(注:该 image 只是一些属性的集合,比如 block device mapping, kernel 和 ramdisk IDs 等,它并没有 image 数据, 因此其 size 为 0。)
-
s1@controller:~$ glance image-show e86cc562-349c-48cb-a81c-896584accde3 +---------------------------------+----------------------------------------------------------------------------------+ -
| Property | Value | -
+---------------------------------+----------------------------------------------------------------------------------+ -
| Property 'bdm_v2' | True | -
| Property 'block_device_mapping' | [{"guest_format": null, "boot_index": 0, "no_device": null, "snapshot_id": | -
| # 分别是该虚机挂载的两个volume 的 | "d1277ea9-e972-4dd4-89c0-0b9d74956247", "delete_on_termination": null, | -
| snapshot 的信息 | "disk_bus": "virtio", "image_id": null, "source_type": "snapshot", | -
| | "device_type": "disk", "volume_id": null, "destination_type": "volume", | -
| | "volume_size": null}, {"guest_format": null, "boot_index": null, "no_device": | -
| | null, "snapshot_id": "a7c591fb-3413-4548-abd8-86753da3158b", | -
| | "delete_on_termination": null, "disk_bus": null, "image_id": null, | -
| | "source_type": "snapshot", "device_type": null, "volume_id": null, | -
| | "destination_type": "volume", "volume_size": null}] | -
| Property 'checksum' | 64d7c1cd2b6f60c92c14662941cb7913 | -
| Property 'container_format' | bare | -
| Property 'disk_format' | qcow2 | -
| Property 'image_id' | bb9318db-5554-4857-a309-268c6653b9ff | -
| Property 'image_name' | image | -
| Property 'min_disk' | 0 | -
| Property 'min_ram' | 0 | -
| Property 'root_device_name' | /dev/vda | -
| Property 'size' | 13167616 | -
| created_at | 2015-06-10T05:52:24 | -
| deleted | False | -
| id | e86cc562-349c-48cb-a81c-896584accde3 | -
| is_public | False | -
| min_disk | 0 | -
| min_ram | 0 | -
| name | vm10-snap | -
| owner | 74c8ada23a3449f888d9e19b76d13aab | -
| protected | False | -
| size | 0 # 这里 size 是 0,表明该 image 只是元数据, | -
| status | active | -
| updated_at | 2015-06-10T05:52:24 | -
+---------------------------------+----------------------------------------------------------------------------------+
5. 当前 Nova snapshot 的局限
- Nova snapshot 其实只是提供一种创造系统盘镜像的方法。不支持回滚至快照点,只能采用该快照镜像创建一个新的虚拟机。
- 在虚机是从 image boot 的时候,只对系统盘进行快照,不支持内存快照,不支持系统还原点 (blueprint:https://blueprints.launchpad.net/nova/+spec/live-snapshot-vms)
- Live Snapshot 需要用户进行一致性操作:http://www.sebastien-han.fr/blog/2012/12/10/openstack-perform-consistent-snapshots/
- 只支持虚拟机内置(全量)快照,不支持外置(增量)快照。这与当前快照的实现方式有关,因为是通过 image 进行保存的。
- 从 image boot 的虚机的快照以 Image 方式保存到 Glance 中,而非以 Cinder 卷方式保存。
- 过程较长(需要先通过存储快照,然后抽取并上传至 Glance),网络开销大。
那为什么 Nova 不实现虚机的快照而只是系统盘的快照呢?据说,社区关于这个功能有过讨论,讨论的结果是不加入这个功能,原因主要有几点:
- 这应该是一种虚拟化技术的功能,不是云计算平台的功能。
- openstack 由于底层要支持多种虚拟化的技术,某些虚拟化技术实现这种功能比较困难。
- 创建的 VM state snapshot 会面临 cpu feature 不兼容的问题。
- 目前 libvirt 对 QEMU/KVM 虚机的外部快照的支持还不完善,即使更新到最新的 libvirt 版本,造成兼容性比较差。
这里 也有很多的讨论。
(8):使用 libvirt 迁移 QEMU/KVM 虚机和 Nova 虚机
1. QEMU/KVM 迁移的概念
迁移(migration)包括系统整体的迁移和某个工作负载的迁移。系统整理迁移,是将系统上所有软件包括操作系统完全复制到另一个物理机硬件机器上。虚拟化环境中的迁移,可分为静态迁移(static migration,或者 冷迁移 cold migration,或者离线迁移 offline migration) 和 动态迁移 (live migration,或者 热迁移 hot migration 或者 在线迁移 online migration)。静态迁移和动态迁移的最大区别是,静态迁移有明显一段时间客户机中的服务不可用,而动态迁移则没有明显的服务暂停时间。
虚拟化环境中的静态迁移也可以分为两种,一种是关闭客户机后,将其硬盘镜像复制到另一台宿主机上然后恢复启动起来,这种迁移不能保留客户机中运行的工作负载;另一种是两台宿主机共享存储系统,这时候的迁移可以保持客户机迁移前的内存状态和系统运行的工作负载。
动态迁移,是指在保证客户机上应用服务正常运行的同时,让客户机在不同的宿主机之间进行迁移,其逻辑步骤和前面的静态迁移几乎一直,有硬盘存储和内存都复制的动态迁移,也有仅复制内存镜像的动态迁移。不同的是,为了保证迁移过程中客户机服务的可用性,迁移过程只能有非常短暂的停机时间。动态迁移允许系统管理员将客户机在不同物理机上迁移,同时不会断开访问客户机中服务的客户端或者应用程序的连接。一个成功的迁移,需要保证客户机的内存、硬盘存储和网络连接在迁移到目的主机后任然保持不变,而且迁移的过程的服务暂停时间较短。
1.1 迁移效率的衡量
(1)整体迁移时间
(2)服务器停机时间:这时间是指源主机上的客户机已经暂停服务,而目的主机上客户机尚未恢复服务的时间。
(3)对服务性能的影响:客户机迁移前后性能的影响,以及目的主机上其它服务的性能影响。
其中,整体迁移时间受很多因素的影响,比如 Hypervisor 和迁移工具的种类、磁盘存储的大小(是否需要复制磁盘镜像)、内存大小及使用率、CPU 的性能和利用率、网络带宽大小及是否拥塞等,整体迁移时间一般分为几秒钟到几十分钟不等。动态迁移的服务停机时间,也有这些因素的影响,往往在几毫秒到几百毫秒。而静态迁移,其暂停时间较长。因此,静态迁移一般适合于对服务可用性要求不高的场景,而动态迁移适合于对可用性要求高的场景。
动态迁移的应用场景包括:负载均衡、解除硬件依赖、节约能源 和异地迁移。
1.2 KVM 迁移的原理
1.2.1 静态迁移
对于静态迁移,你可以在宿主机上某客户机的 QEMU monitor 中,用 savevm my_tag 命令保存一个完整的客户机镜像快照,然后在宿主机中关闭或者暂停该客户机,然后将该客户机的镜像文件复制到另一台宿主机中,使用在源主机中启动该客户机时的命令来启动复制过来的镜像,在其 QEMU monitor 中 loadvm my_tag 命令恢复刚才保存的快照即可完全加载保存快照时的客户机状态。savevm 命令可以保证完整的客户机状态,包括 CPU 状态、内存、设备状态、科协磁盘中的内存等。注意,这种方式需要 qcow2、qed 等格式的磁盘镜像文件的支持。
1.2.2 动态迁移
如果源宿主机和目的宿主机共享存储系统,则只需要通过网络发送客户机的 vCPU 执行状态、内存中的内容、虚机设备的状态到目的主机上。否则,还需要将客户机的磁盘存储发到目的主机上。共享存储系统指的是源和目的虚机的镜像文件目录是在一个共享的存储上的。
在基于共享存储系统时,KVM 动态迁移的具体过程为:
- 迁移开始时,客户机依然在宿主机上运行,与此同时,客户机的内存页被传输到目的主机上。
- QEMU/KVM 会监控并记录下迁移过程中所有已被传输的内存页的任何修改,并在所有内存页都传输完成后即开始传输在前面过程中内存页的更改内容。
- QEMU/KVM 会估计迁移过程中的传输速度,当剩余的内存数据量能够在一个可以设定的时间周期(默认 30 毫秒)内传输完成时,QEMU/KVM 会关闭源宿主机上的客户机,再将剩余的数据量传输到目的主机上,最后传输过来的内存内容在目的宿主机上恢复客户机的运行状态。
- 至此,KVM 的动态迁移操作就完成了。迁移后的客户机尽可能与迁移前一直,除非目的主机上缺少一些配置,比如网桥等。
注意,当客户机中内存使用率非常大而且修改频繁时,内存中数据不断被修改的速度大于KVM能够传输的内存速度时,动态迁移的过程是完成不了的,这时候只能静态迁移。
1.3 使用命令行的方式做动态迁移
1.3.1 使用 NFS 共享存储
(1)在源宿主机上挂载 NFS 上的客户机镜像,并启动客户机
mount my-nfs:/raw-images/ /mnt/ kvm /mnt/rh1.img -smp 2 -m 2048 -net nic -net tap(2)在目的宿主机上也挂载镜像目录,并启动一个客户机用于接收动态迁移过来的内存内容
mount my-nfs:/raw-images/ /mnt/ kvm /mnt/rh1.img -smp 2 -m 2048 -net nic -net tap -incoming tcp:0:6666注意:(1)NFS 挂载目录必须一致 (2)“-incoming tcp:0:6666” 参数表示在 6666 端口建立一个 TCP socket 连接用于接收来自源主机的动态迁移的内容,其中 0 表示运行来自任何主机的连接。“-incoming“ 使 qemu-kvm 进程进入到监听模式,而不是真正以命令行中的文件运行客户机。
(3)在源宿主机的客户机的 QEMU monitor 中,使用命令 ” migrate tcp:host2:6666" 即可进入动态迁移的流程。
1.3.2 不使用共享存储的动态迁移
过程类似,包括使用相同backing file 的镜像的客户机迁移,以及完全不同镜像文件的客户机的迁移。唯一的区别是,migrate 命令中添加 “-b” 参数,它意味着传输块设备。
1.3.3 其它 QEMU monitor migrate 命令
- migrate_cancel:取消迁移
- migrate_set_speed:设置最大迁移速度,单位是 bytes
- migrate_set_downtime:设置最大允许的服务暂停时间,单位是 秒
- info migrate:显示迁移进度
2. OpenStack Nova QEMU/KVM 实例动态迁移的环境配置
除了直接拷贝磁盘镜像文件的冷迁移,OpenStack 还支持下面几种虚机热迁移模式:
- 不使用共享存储时的块实时迁移(Block live migration without shared storage)。这种模式不支持使用只读设备比如 CD-ROM 和 Config Drive。块实时迁移不需要 nova compute 节点都使用共享存储。它使用 TCP 来将虚机的镜像文件通过网络拷贝到目的主机上,因此和共享存储式的实时迁移相比,这种方式需要更长的时间。而且在迁移过程中,主机的性能包括网络和 CPU 会下降。
- 基于共享存储的实时迁移 (Shared storage based live migration):两个主机可以访问共享的存储。
- 从卷启动的虚机的实时迁移(Volume backed VM live migration)。这种迁移也是一种块拷贝迁移。
实时迁移的过程并不复杂,复杂在于环境配置。
2.1 基础环境配置
2.1.1 SSH 权限配置
这种方式需要配置源(compute1)和目的主机(compute2)之间能够通过 SSH 相互访问,以确保能通过 TCP 拷贝文件,已经可以通过 SSH 在目的主机建立目录。
使用 nova 用户在compute1 上执行操作:
-
usermod -s /bin/bash nova -
su nova -
mkdir -p -m 700 .ssh -
#创建 config 文件如下 -
nova@compute2:~/.ssh$ cat config -
Host * StrictHostKeyChecking no -
UserKnownHostsFile=/dev/null #产生 key -
ssh-keygen -f id_rsa -b 1024 -P "" cat id_rsa.pub >> authorized_keys -
#将 id_rsa id_rsa.pub 拷贝到 compute2 上面 -
cat id_rsa.pub >> authorized_keys
使用 root 用户在每个主机上进行操作:
-
root@compute1:/var/lib/nova/.ssh# chown -R nova:nova /var/lib/nova -
root@compute1:/var/lib/nova/.ssh# chmod 700 /var/lib/nova/.ssh -
root@compute1:/var/lib/nova/.ssh# chmod 600 /var/lib/nova/.ssh/authorized_keys
测试 SSH 无密码访问:
-
nova@compute1:~/.ssh$ ssh nova@compute2 ls -
Warning: Permanently added 'compute2,192.168.1.29' (ECDSA) to the list of known hosts. -
... -
nova@compute2:~/.ssh$ ssh nova@compute1 ls -
Warning: Permanently added 'compute1,192.168.1.15' (ECDSA) to the list of known hosts. -
...
2.1.2 其它配置
每个node 上的 DNS 或者 /etc/hosts,确保互联互通。
2.2 Live migration 环境配置
2.2.1 libvirtd 配置
在 compute1 和 compute2 上做如下配置:
-
->Edit /etc/libvirt/libvirtd.conf -
listen_tls = 0 listen_tcp = 1 auth_tcp = “none” ->Edit /etc/init/libvirt-bin.conf env libvirtd_opts="-d -l"
->Edit /etc/default/libvirt-bin# options passed to libvirtd, add "-l" to listen on tcp
libvirtd_opts="-d -l"-
->Restart libvirtd -
service libvirt-bin restart -
root 12088 1 2 07:48 ? 00:00:00 /usr/sbin/libvirtd -d -l
做完上述操作后,可以使用如下命令来检查是否设置正确:
-
root@compute2:~# virsh -c qemu+tcp://compute1/system list --all Id Name State ---------------------------------------------------- 4 instance-0000000d running 5 instance-00000006 running - instance-00000005 shut off -
root@compute1:~# virsh -c qemu+tcp://compute2/system list --all Id Name State ----------------------------------------------------
Nova 设置:
-
->Edit /etc/nova/nova.conf, add following line: -
[libvirt] -
block_migration_flag = VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER, VIR_MIGRATE_LIVE,VIR_MIGRATE_TUNNELLED,VIR_MIGRATE_NON_SHARED_INC -
live_migration_flag = VIR_MIGRATE_UNDEFINE_SOURCE, VIR_MIGRATE_PEER2PEER, VIR_MIGRATE_LIVE,VIR_MIGRATE_TUNNELLED -
live_migration_uri = qemu+tcp://%s/system
2.2.2 共享存储 Live migration 环境配置
其实共享存储的实时迁移配置的要求和块拷贝的实时迁移的配置差不多,除了下面几点:
- Hypervisor 要求:目前只有部分 Hypervisor 支持 live migraiton,可查询该表。
- 共享存储:存放虚机文件的文件夹 NOVA-INST-DIR/instances/ (比如 /var/lib/nova/instances,该路径可以由 state_path 配置变量来配置) 必须是挂载到共享存储上的。当Nova 使用 RBD 作为镜像的backend时,这个要求不是必须的,具体见下面的说明。
- 必须在 nova.conf 中配置 vncserver_listen=0.0.0.0 (关于这个,社区认为这个配置具有安全风险,会通过这个 ticket 来解决)
- 不使用默认配置的话,必须在每个 nova compute 上的 nova.conf 中配置相同的 instances_path 和 state_path 。
- 在 Kilo 版本之前,Nova 是默认不支持 live migriation 的。在做实时迁移之前,需要在 nova.conf 中做如下配置
live_migration_flag=VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_TUNNELLED注意:对于上面第二点,在 Kilo 版本中(前面版本的情况未知),当 Nova 使用 RBD 作为 image backend 时,Nova 会认为是在共享存储上:
def check_instance_shared_storage_local(self, context, instance): """Check if instance files located on shared storage.""" if self.image_backend.backend().is_shared_block_storage(): return None在 class Rbd(Image): 类中:
-
@staticmethod -
def is_shared_block_storage(): -
"""True if the backend puts images on a shared block storage.""" return True
目前,只有 RBD 作为 image backend 时,该函数才返回 true。对于其它类型的 backend,Nova 会在目的 host 上的 instance folder 创建一个临时文件,再在源 host 上查看该文件,通过判断是否该文件在共享存储上来判断是否在使用共享存储。
常见问题:
(1)在源 host 上,出现 ”live Migration failure: operation failed: Failed to connect to remote libvirt URI qemu+tcp://compute2/system: unable to connect to server at 'compute2:16509': Connection refused“
其原因是 2.1.1 部分的 libvirt 设置不正确。
(2)在目的 host 上,出现 ”libvirtError: internal error: process exited while connecting to monitor: 2015-09-21T14:17:31.840109Z qemu-system-x86_64: -drive file=rbd:vms/6bef8898-85f9-429d-9250-9291a2e4e5ac_disk:id=cinder:key=AQDaoPpVEDJZHhAAu8fuMR/OxHUV90Fm1MhONQ==:auth_supported=cephx\;none:mon_host=9.115.251.194\:6789\;9.115.251.195\:6789\;9.115.251.218\:6789,if=none,id=drive-virtio-disk0,format=raw,cache=writeback,discard=unmap: could not open disk image rbd:vms/6bef8898-85f9-429d-9250-9291a2e4e5ac_disk:id=cinder:key=AQDaoPpVEDJZHhAAu8fuMR/OxHUV90Fm1MhONQ==:auth_supported=cephx\;none:mon_host=9.115.251.194\:6789\;9.115.251.195\:6789\;9.115.251.218\:6789: Could not open 'rbd:vms/6bef8898-85f9-429d-9250-9291a2e4e5ac_disk:id=cinder:key=AQDaoPpVEDJZHhAAu8fuMR/OxHUV90Fm1MhONQ==:auth_supported=cephx\;none:mon_host=9.115.251.194\:6789\;9.115.251.195\:6789\;9.115.251.218\:6789': Operation not permitted“
原因:目的 host 上的用户操作 RBD 的权限设置不正确,检查 secret 设置。
3. 迁移过程
3.0 Nova 有关迁移的命令
Nova 有三个与迁移有关的命令:migrate,live-migrate 和 resize。
Nova CLI REST API Action 行为 nova live-migration --block-migrate --disk_over_commit 8352e969-0a25-4abf-978f-d9d0ec4de0cd compute2 os-migrateLive 块拷贝动态迁移 nova live-migration 8352e969-0a25-4abf-978f-d9d0ec4de0cd compute2 os-migrateLive 共享存储动态迁移 nova migrate 8352e969-0a25-4abf-978f-d9d0ec4de0cd migrate 静态迁移 nova resize --poll 8352e969-0a25-4abf-978f-d9d0ec4de0cd 1 resize 静态迁移并且改变 flavor nova resize --poll 8352e969-0a25-4abf-978f-d9d0ec4de0cd resize 静态迁移 nova resize-confirm 9eee079e-0353-44cb-b76c-ecf9be61890d confirmResize 确认 resize 使得完整操作得以完成 nova resize-revert 9eee079e-0353-44cb-b76c-ecf9be61890d revertResize 取消 resize 使得操作被取消虚机回到原始状态 3.1 静态迁移(migrate 或者 resize 不使用新的 flavor)
-
s1@controller:~$ nova migrate --poll 9eee079e-0353-44cb-b76c-ecf9be61890d -
Server migrating... 100% complete -
Finished -
s1@controller:~$ nova list -
+--------------------------------------+-------+---------------+------------+-------------+------------------------------------------+ -
| ID | Name | Status | Task State | Power State | Networks | -
+--------------------------------------+-------+---------------+------------+-------------+------------------------------------------+ -
| 02699155-940f-4401-bc01-36220db80639 | vm10 | ACTIVE | - | Running | demo-net2=10.0.10.17; demo-net=10.0.0.39 | -
| 9eee079e-0353-44cb-b76c-ecf9be61890d | vm100 | VERIFY_RESIZE | - | Running | demo-net2=10.0.10.20 | -
+--------------------------------------+-------+---------------+------------+-------------+------------------------------------------+ s1@controller:~$ nova resize-confirm 9eee079e-0353-44cb-b76c-ecf9be61890d -
s1@controller:~$ nova list -
+--------------------------------------+-------+--------+------------+-------------+------------------------------------------+ -
| ID | Name | Status | Task State | Power State | Networks | -
+--------------------------------------+-------+--------+------------+-------------+------------------------------------------+ -
| 02699155-940f-4401-bc01-36220db80639 | vm10 | ACTIVE | - | Running | demo-net2=10.0.10.17; demo-net=10.0.0.39 | -
| 9eee079e-0353-44cb-b76c-ecf9be61890d | vm100 | ACTIVE | - | Running | demo-net2=10.0.10.20 | -
+--------------------------------------+-------+--------+------------+-------------+------------------------------------------+
3.1.1 迁移过程
直接使用流程图来说明:


1. migrate 和 resize 都是执行静态迁移。
2. 静态迁移分为三个阶段:
(1)调用 Scheduler 算法选择目的 node(步骤5),并通过 RPC 远程调用 prep_resize 做些迁移前的准备工作
(2)在源主机上,调用 libvirt driver 做一系列操作:
- 使用 ssh 在目的 node 上建立虚机的镜像文件的目录
- 将虚机关机
- 断开所有 volume connections
- 针对每一个非 swap 分区的磁盘,如果是 qcow2 格式,则执行 qemu-img merge 操作将稀疏文件和backing 文件合并成单个文件,并通过 “rysnc” 或者 “scp”命令将文件拷贝到目的 node 上
- 开始迁移需要的网络工作
(3)通过 RPC,调用目的 node 上的 Nova 的 finish_resize 方法。该方法会在自己本机上设置网络、结束网络设置工作,并调用 libvirt driver 来:
- 创建 image
- 获取 guest xml
- 创建 domain 和 network
- 需要的话启动虚机
至此,虚机已经被拷贝到目的主机上了。接下来,用户有两个选择:resize_confirm 和 resize_revert。
3.1.2 确认迁移 (resize_confirm)
迁移确认后,在源主机上,虚机的文件会被删除,虚机被 undefine,虚机的 VIF 被从 OVS 上拔出,network filters 也会被删除。

3.1.3 取消迁移 (resize_revert)
取消迁移的命令首先发到目的 node 上,依次 tear down network,删除 domain,断掉 volume connections,然后调用源主机上的方法来重建 network,删除临时文件,启动 domain。这样,虚机就会需要到 resize 之前的状态。

3.2 实时迁移 (Live migration)
可以 Nova client 的 live-migration 命令来做实时迁移,除了要被迁移的 虚机 和 目的 node 外,它可以带两个额外的参数:
- “block-migrate“:使用的话,做 block copy live migration;不使用的话,做共享存储的 live migration;
- ”disk_over_commit“:使用的话,计算所有磁盘的 disk_size 来计算目的 node 上所需空间的大小;不使用的话,则计算磁盘的 virtual size。在下面的例子中,如果使用 disk_over_commit,那么计算在目的主机上需要的空间的时候,该 disk 的 size 为 324k,否则为 1G:
-
root@compute1:/home/s1# qemu-img info /var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk.local -
image: /var/lib/nova/instances/8352e969-0a25-4abf-978f-d9d0ec4de0cd/disk.local -
file format: qcow2 virtual size: 1.0G (1073741824 bytes) -
disk size: 324K -
cluster_size: 65536 backing file: /var/lib/nova/instances/_base/ephemeral_1_default -
Format specific information: -
compat: 1.1 lazy refcounts: false
REST API request body 实例: {"os-migrateLive": {"disk_over_commit": false, "block_migration": true, "host": "compute2"}}
实时迁移的主要步骤如下:


其过程也可以分为三个阶段:
3.2.1 实时迁移前的准备工作 (步骤 2 - 7)
Nova 通过 RPC 调用目的主机上 nova comute manager 的 pre_live_migration 方法,它依次:
(1)准备 instance 目录:
(1)创建 instance dir
(2)如果源和目的虚机不共享 instance path:获取镜像类型,为每一个disk,如果不使用 backing file 的话则调用 “qemu-img create” 方法来创建空的磁盘镜像;否则,依次创建空的 Ephemeral disk 和 Swap disk,以及从 Glance 中获取 image 来创建 Root disk
(3)如果不是 block migration 而且 不 is_shared_instance_path,则 _fetch_instance_kernel_ramdisk
(2)调用 volumer driver api 为每一个volume 建立目的主机和 volume 的连接
(3)调用 plug_vifs(instance, network_info) 将每一个 vif plug 到 OVS 上
(4)调用 network_api.setup_networks_on_host 方法,该方法会为迁移过来的虚机准备 dhcp 和 gateway;
(5)调用 libvirt driver 的 ensure_filtering_rules_for_instance 方法去准备 network filters。
3.2.2 调用 libvirt API 开始迁移虚机 (步骤 8 - 9)
这部分的实现在 libvirt driver 代码中。因为 libvirt 的一个 bug (说明在这里),当 libvirt 带有 VIR_DOMAIN_XML_MIGRATABLE flag 时,Nova 会调用 libvirt 的 virDomainMigrateToURI2 API,否则调用 virDomainMigrateToURI API。
首先比较一下 block live migration 和 live migration 的 flags 的区别:
#nova block live migration flags:VIR_MIGRATE_UNDEFINE_SOURCE, VIR_MIGRATE_PEER2PEER, VIR_MIGRATE_LIVE, VIR_MIGRATE_TUNNELLED, VIR_MIGRATE_NON_SHARED_INC #nova live migration flags: VIR_MIGRATE_UNDEFINE_SOURCE, VIR_MIGRATE_PEER2PEER, VIR_MIGRATE_LIVE, VIR_MIGRATE_TUNNELLED各自的含义如下:
- VIR_MIGRATE_UNDEFINE_SOURCE: 迁移完成后,将源虚机删除掉。(If the migration is successful, undefine the domain on the source host.)
- VIR_MIGRATE_PEER2PEER 和 VIR_MIGRATE_TUNNELLED 一起使用:点对点迁移,必须指定目的 URI,QEMU在两者之间建立 TCP Tunnel 用于数据传输
- VIR_MIGRATE_LIVE: 执行 live migration,不要停机 (Do not pause the VM during migration)
- VIR_MIGRATE_NON_SHARED_INC: 使用非共享存储式迁移即 block migration (Migration with non-shared storage with incremental disk copy)
再看看两个 API 的参数:
int virDomainMigrateToURI2 (virDomainPtr domain, const char * dconnuri, # 格式为 qemu+tcp:///system const char * miguri, #为 none const char * dxml, #指定迁移后的虚机的 XML。Nova 对 “/devices/graphics” 部分做了一点点更改。 unsigned long flags, # nova.conf 中的配置 const char * dname, #none unsigned long bandwidth) # 由 CONF.libvirt.live_migration_bandwidth 指定,默认为 0 表示由 libvirt 自己选择合适的值如果 libvirt 不带 VIR_DOMAIN_XML_MIGRATABLE flag,则调用的 API 是:
-
int virDomainMigrateToURI (virDomainPtr domain, const char * duri, -
unsigned long flags, const char * dname, -
unsigned long bandwidth)
可见,两个 API 唯一的区别是不能指定新的虚机使用的 XML 配置。这时候你必须手动配置 VNC 或者 SPICE 地址为 0.0.0.0 or :: (接收全部)或者 127.0.0.1 or ::1 (只限本机)。
调用 API 后,接下来就是等待其完成。这其中的过程应该主要包括:
(1)根据传入的 domain xml,启动一个虚机,它处于等待 TCP incoming 状态
(2)从源 node 上将 domain 的数据传过来
(3)快完成时,关闭源 node 上的虚机,传输最后一次数据,打开目的 node 上的虚机
(4)将源 node 上的虚机删除
Nova 每个0.5 秒检查源虚机的状态,直到它被删除。
迁移完成后,需要执行后续的操作(_post_live_migration)。
3.2.3 迁移完成后在源和目的主机上的后续操作(步骤 10 -29)
在源主机上,依次执行下面的操作:
- 调用 volume driver 的 disconnect_volume 方法和 terminate_connection 方法,断开主机和所有 volume 的连接
- 调用 firewall driver 的 unfilter_instance 方法,删除 domain 的 iptables 中的所有 security group ingress 规则 (self.iptables.ipv4['filter'].remove_chain(chain_name))
- 调用 network api 的 migrate_instance_start 方法,开始将网络从源主机上迁移到目的主机上(实际上没做什么事情,只是 pass)
- 调用 vif driver 的 unplug 方法,将每个 vif 从 OVS 上删除
-
brctl delif qbr59cfa0b8-2f qvb59cfa0b8-2f -
ip link set qbr59cfa0b8-2f down -
brctl delbr qbr59cfa0b8-2f -
ovs-vsctl --timeout=120 -- --if-exists del-port br-int qvo59cfa0b8-2f -
ip link delete qvo59cfa0b8-2f
-
- 通过 RPC 调用目的主机上的 nova manager 的 post_live_migration_at_destination 方法,该方法会:
- 调用 network api 的 setup_networks_on_host 方法来设置网络(处理 vpn,dhcp,gateway)
- 调用 network api 的 migrate_instance_finish 方法
- 调用 libvirt driver 的 post_live_migration_at_destination方法,它会调用 libvirt _conn.listDefinedDomains 方法查看迁移过来的主机的 domain是否存在;不存在的话,生成其 xml,然后调用 libvirt API _conn.defineXML(xml) 去定义该 domain。
- 将新的 domain 数据更新到数据库(包括新的 host,power_state,vm_state,node)
- 调用 network api 的 setup_networks_on_host 方法 (不理解为什么重复上面第1步)
- 调用 libvirt driver 的 driver.cleanup 方法去 _unplug_vifs (如果上面第四步失败,则再次尝试删除所有 vif 相关的 bridge 和 OVS 连接),firewall_driver.unfilter_instance (和上面第2步重复了),_disconnect_volume(断开 domain 和 所有 volume 的连接),_delete_instance_files (删除 domain 相关的文件),_undefine_domain (删除 domain)
- 调用 network_api.setup_networks_on_host 去 tear down networks on source host
- 至此,live migration 完全结束。
3.2.4 迁移过程中失败时的回滚
迁移的三个步骤中,前面第一个和第二个步骤中出现失败的话,会调用 _rollback_live_migration 启动回滚操作。该方法
(1)将虚机的状态由 migrating 变为 running。
(2)调用 network_api.setup_networks_on_host 方法重做源主机上的网络设置
(3)通过 RPC 调用,去目的主机上将准备过程中建立的 volume 连接删除。
(4)通过 RPC 调用,去目的主机上调用 compute_rpcapi.rollback_live_migration_at_destination 函数,该方法会
(1)调用 network_api.setup_networks_on_host 方法去 tear down networks on destination host
(2)调用 libvirt driver 的 driver.rollback_live_migration_at_destination 方法,它会将 domain 删除,并且清理它所使用的资源,包括 unplug vif,firewall_driver.unfilter_instance,_disconnect_volume, _delete_instance_files, _undefine_domain。
3.2.5 测试
环境:准备两个虚机 vm1 和 vm2,操作系统为 cirros。打算将 vm1 迁移到另一个node 上。在 vm2 上查看 vm1 在迁移过程中的状态。
迁移前:在 vm1 中运行 “ping vm2”,并在 vm2 中 ssh 连接到 vm1。
结果:vm1 迁移过程中,vm2 上 ssh 的连接没有中断,vm1 中的 ping 命令继续执行。在另一次测试结果中,vm2 ping vm1 在整个迁移过程中 time 出现了一次 2ms 的时间增加。
3.3 遇到过的问题
3.3.1 apparmor
将虚机从 compute1 迁移到 compute2 成功,再从 compute2 迁移到 compute1 失败,报错如下:
An error occurred trying to live migrate. Falling back to legacy live migrate flow. Error: unsupported configuration: Unable to find security driver for label apparmor经比较迁移前后的虚机的 xml,发现 compute2 上的虚机的 xml 多了一项: 。
分别在 compute 1 和 2 上运行 “virsh capabilities”,发现 compute1 没有使用 apparmor,而 compute2 使用了 apparmor。
-
#compute 1 上 -
none -
0 -
#compute2 上 -
apparmor -
0
最简单的方法是在两个 node 上都 disable apparmor(在 /etc/libvirt/qemu.conf 中添加 ‘security_driver = “none” 然后重启 libvirtd),然后 destroy/start 虚机后,它的 xml 配置中的 apparmor 就没有了。这篇文章 详细介绍了 apparmor。
3.3.2 当虚机是 boot from volume 时,live migration 失败。
报错:
-
Command: iscsiadm -m node -T iqn.2010-10.org.openstack:volume-26446902-5a56-4c79-b839-a8e13a66dc7a -p 10.0.2.41:3260 --rescan -
Exit code: 21 Stdout: u'' Stderr: u'iscsiadm: No session found.\n' to caller
原因是 cinder 代码中有 bug,导致目的主机无法建立和 volume 的连接。fix 在这里。
参考文档:
https://www.mirantis.com/blog/tutorial-openstack-live-migration-with-kvm-hypervisor-and-nfs-shared-storage/
http://www.sebastien-han.fr/blog/2015/01/06/openstack-configure-vm-migrate-nova-ssh/
KVM 原理技术 实战与原理解析 任永杰、单海涛著
OpenStack 官网
- 磁盘数据的保存状态:















 2713
2713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









