







给大家良心推荐一款超好用的爬虫软件——前嗅ForeSpider爬虫工具,也是最近发现的。本人是数据工作者,每天就是跟各种各样的数据打交道,数据采集必不可少,然而这也是最令我头疼的地方,尝试了各种各样的爬虫工具,不是操作繁琐就是采集精度不够,无奈自己没有能力造一个,只能受限于现在市面上的种种。
说重点~说重点~重点就是我最近在网上搜索又发现了一款爬虫软件,查了一下说是什么前嗅公司旗下的一款爬虫产品叫前嗅ForeSpider爬虫,只能说是目前为止本人强烈推荐的,用过才发现,简直更是技术白们的福音。
跟之前使用过的其他爬虫软件对比发现,人家这个前嗅ForeSpider爬虫有自己的内置数据库,当然也支持MySQL等主流数据存储系统啦。在使用过程中有几点感受必须大赞特赞。
(1)采集全面。基本上就是把网址链接输进去一步步操作就OK。有特殊情况需要特殊处理才能采集的,也支持配置脚本。
(2)人性化。支持动态调整、自动定时采集、模板在线更新。
(3)操作效率高。前嗅ForeSpider爬虫的操作都是可视化的,而且你要采集的东西在它这个爬虫软件内可以直接预览,让我在采集数据之前直接先把无效数据剔除干净,学习成本很低。
(4)精度高。数据提取同样可进行可视化操作,此外支持正则表达式和脚本配置更加做到精准采集。
(5)功能强大。支持验证码识别、关键字搜索、登录采集、HTTPS协议。妈妈再也不用担心登录和验证码限制了!!
(6)采集性能强大:单机采集能力可达4000-8000万,日采集能力超过500万。服务器单机采集能力可达8亿-16亿,日采集能力超过2000万。并行情况下可支撑百亿以上规模数据链接,堪与百度等搜索引擎系统媲美。
说了那么多,给大家简单分享一下教程吧~ ~ ~
1、 下载安装。这个可以去它官网(www.forenose.com),强烈建议大家先
在官网注册登录,免费试用前嗅ForeSpider爬虫软件,如果满意的话再使用付费版也不迟。
2、 进入前嗅ForeSpider爬虫主程序页面。

3、以一个新闻网站:中国新闻网为例,采集该网站的科技政策性文章,进行采集配置。
(1)表单创建

(2)采集源配置
点开左上角“采集源”,在左边的采集频道列表新建频道,输入采集名称和采集源。

(3)完成上述操作,点击左下方模板列表中的链接模板(默认):01,此时内置的浏览器将会根据你输入的采集源进行同步跳转显示。

(4)点击右上角的“采集预览”按钮,观察你所要采集内容的链接情况。
(5)观察完毕关闭采集预览,右边有模板节点配置:
a.点击默认链接抽取下的链接过滤,进行过滤规则和过滤串的限制。

b.此外,还可以选择标题过滤。
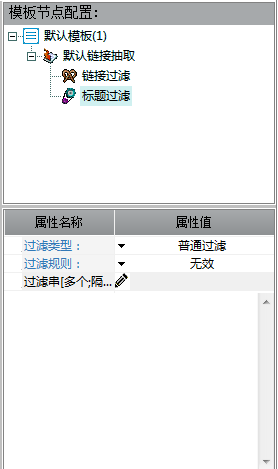
(6)配好默认模板(1),即链接模板,开始配,即数据模版。
点击左下方的“默认模板(2)”,在右边的示例地址上输入你要采集的一篇文章的链接地址。输入好示例地址,内置浏览器可自动跳转。
(7)点击默认模板下的默认数据抽取,在下方的表单名称进行选择


如上图,表单名称:科技政策就是我们在步骤3中的第一步进行的表单创建。
(8)给表单中的每个字段进行定位采集操作。

(9)点击“默认模版(1)”下的“默认链接抽取”。标注模板ID指向“2”,即做到了将连链接模板和数据模版进行了链接。

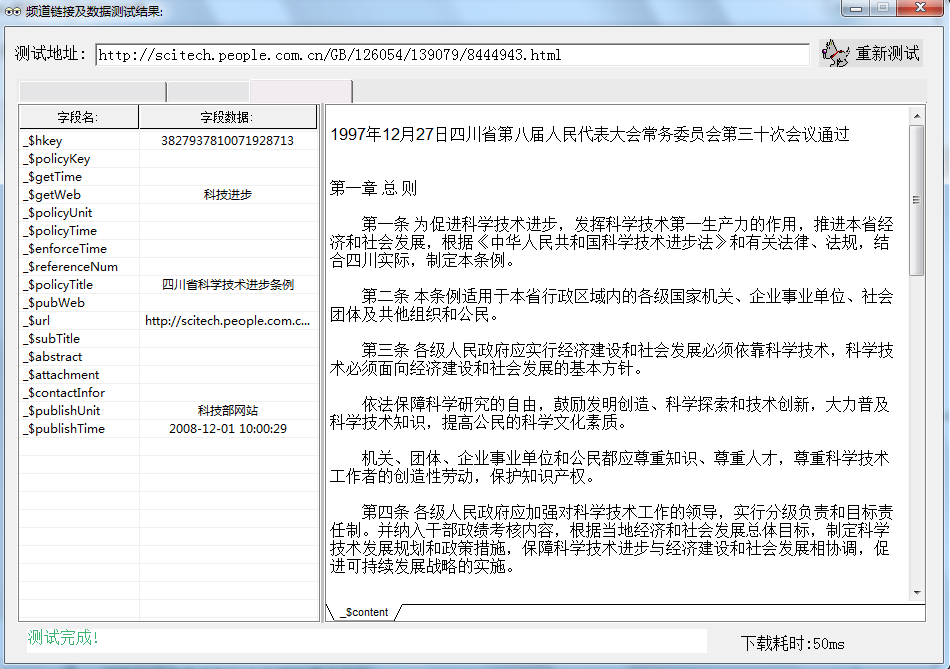
(10)操作完毕,采集预览结果如下:
第一层:

第二层:
教程就简单给大家分享一下,我也是刚入门,还在探索阶段。很神奇有
木有,前嗅ForeSpider爬虫价格也很亲民,如果有兴趣也可以去前嗅网络的官网详细了解一下,把网址给大家(www.forenose.com)。
希望这次分享能给一些数据工作者或者需要数据支持的企业有所帮助,
我也在持续探索着,如果大家有好的爬虫软件或者爬虫工具的,也可以推荐一下,互相帮助互相进步啦~谢谢!















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









