







几年前刚学c#写的 解析类发出来
namespace 采集脚本_1
{
class zd
{
爬虫类 pa=new 爬虫类();
http_post post_1=new http_post() ;
http_get get_1 = new http_get();
public string get_x(string url,string cookies)
{
string y_data=pa.get网页源码(url,"",cookies,"get");
return y_data;
}
public string post_x(string url, string data, string cookies)
{
string y_data = pa.get网页源码(url, data, cookies, "post");
return y_data;
}
public ArrayList xpath_s(string data,string xpath,string ads)
{
ArrayList xp_list_1 = new ArrayList();
HtmlNodeCollection txt=pa.解析html多(data,xpath);
foreach(HtmlNode htm in txt)
{
if (ads != "")
{ xp_list_1.Add(htm.Attributes[ads].Value); }
else { xp_list_1.Add(htm.InnerText); }
}
return xp_list_1;
}
#region 单个html处理
/// <summary>
/// 处理单个html
/// </summary>
/// <param name="data"></param>
/// <param name="xpath"></param>
/// <returns></returns>
public string xpath_d(string data,string xpath)
{
string s_data=pa.解析html单(data,xpath);
return s_data;
}
#endregion
#region 载入脚本
/// <summary>
/// 初始化载入脚本
/// </summary>
/// <returns></returns>
public HtmlNodeCollection load(string bane)
{
HtmlNodeCollection ini;
string data_io = bane;
ini = pa.解析html多(data_io, "//node/node");
return ini;
}
#endregion
#region 异常处理
public void end(string k, TextBox a)
{
a.AppendText(k + "\n");
}
#endregion
/// <summary>
/// 逐行解析脚本
/// </summary>
/// <param name="jx_list"></param>
public void jx(HtmlNodeCollection jx_list,string q_data,ArrayList q_list,TextBox tex,Timer tim,string canshu)
{
if (jx_list != null)
{
foreach (HtmlNode dd in jx_list)
{
string jx_name = dd.Attributes["name"].Value;
switch (jx_name)
{
case "http_post"://post读取网页
http_post post = new http_post();
post.http_url = dd.Attributes["url"].Value;
post.http_data = dd.Attributes["data"].Value;
post.http_cookies = dd.Attributes["cookies"].Value;
q_data = post_x(post.http_url, post.http_data, post.http_cookies);
break;
case "http_get"://get读取网页
http_get get = new http_get();
get.http_url = dd.Attributes["url"].Value.Replace("【i】",canshu);
get.http_cookies = dd.Attributes["cookies"].Value;
q_data = get_x(get.http_url, get.http_cookies);
break;
case "xpath_d"://单个解析xpath
string s_xpath_1 = dd.Attributes["xpath"].Value;
q_data = xpath_d(q_data, s_xpath_1);
break;
case "xpath_s"://多个解析xpath
string s_xpath = dd.Attributes["xpath"].Value;
string iff = dd.Attributes["if"].Value;
q_list = xpath_s(q_data, s_xpath,iff);
break;
case "w"://输出信息
string sta = dd.Attributes["state"].Value;
string atrin = dd.Attributes["string"].Value.Replace("【i】",canshu);
if (sta == "str")
{
tex.Invoke(new MethodInvoker(delegate{end(atrin + q_data, tex);}));
}
else if (sta == "data") { tex.Invoke(new MethodInvoker(delegate { end(atrin, tex); })); }
else
{
tex.Invoke(new MethodInvoker(delegate
{
foreach (string ss in q_list)
{
end(ss, tex);
}
}));
}
break;
case "for":
forr forr = new forr();
string s_sub = dd.Attributes["sub"].Value;
int ine = 0;
if (s_sub == "cont")
{
endfor(q_list.Count, dd.InnerHtml, q_data, q_list, tex, tim,ine);
}
else
{
endfor(int.Parse(s_sub), dd.InnerHtml, q_data, q_list, tex, tim,ine);
}
break;
case "clear":
string zdd=dd.Attributes["attribute"].Value;
if (zdd == "list")
{
q_list.Clear();
}
else {
q_data = "";
}
break;
case "clean":
tex.Text = "";
break;
case "time":
q_data = DateTime.Now.ToString();
break;
case "timer":
string tine=dd.Attributes["int"].Value;
int m = (1000 * 60) * int.Parse(tine);
tim.Interval = m;
tim.Enabled = true;
break;
case "io":
//q_data = dd.Attributes[""]
break;
}
}
}
else { end("初始化脚本错误!!!", tex); }
}
/// <summary>
/// 循环 处理
/// </summary>
/// <param name="cs"></param>
/// <param name="nr_data"></param>
/// <param name="b"></param>
/// <param name="c"></param>
/// <param name="d"></param>
/// <param name="f"></param>
/// <param name="ino"></param>
public void endfor(int cs,string nr_data,string b,ArrayList c,TextBox d,Timer f,int ino)
{
for (int j = 0; j < cs;j++ )
{
ino = j;
HtmlNodeCollection htmll=pa.解析html多(nr_data, "//node");
if(htmll!=null)
{
jx(htmll, b, c, d,f,j.ToString());
}
}
}
}
public class http_post
{
public string http_url { set; get; }
public string http_cookies { set; get; }
public string http_data { set; get; }
}
public class http_get
{
public string http_url { set; get; }
public string http_cookies { set; get; }
}
public class forr
{
/// <summary>
/// 次数
/// </summary>
public int i { set; get; }//次数
/// <summary>
/// 下标
/// </summary>
public int a { set; get; }//列表下标
}
}
为什么叫html解释器呢,因为利用了html节点树解析,也可以利用别的结构 例如xml 或者自己实现解析 。 下面是运行时状态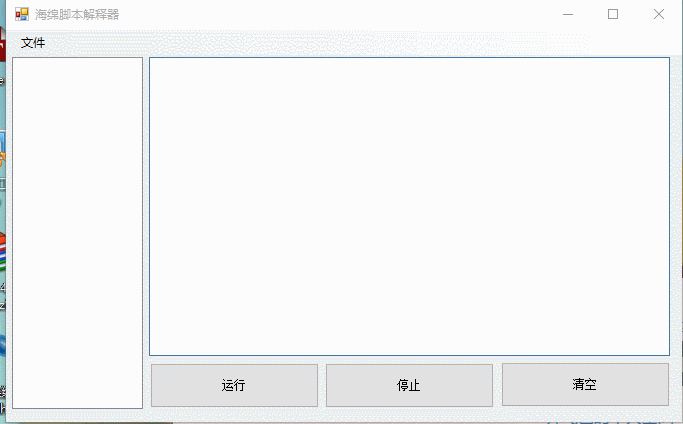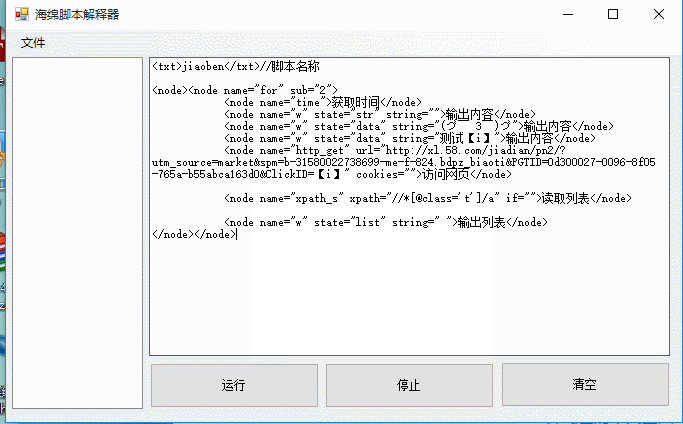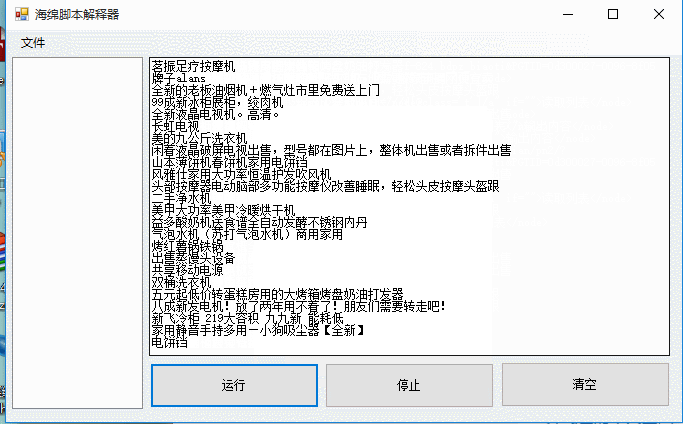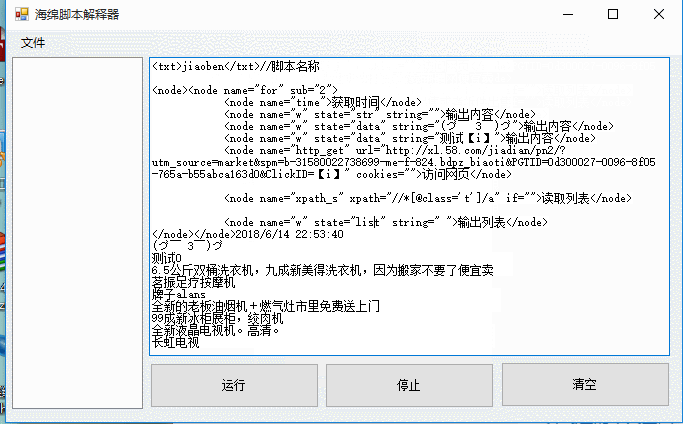















 59
59











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









