






说明:蓝色=命令名称
浅绿=命令参数
浅蓝=选项
紫色=目录
系统环境:CentOS 6.2 i686
有文件,包含的内容如下:

去除重复列结果如下:

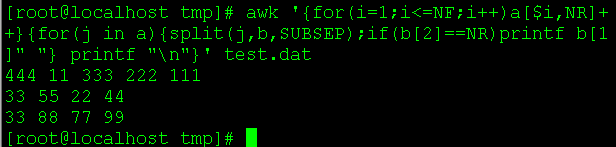
方法:awk '{for(i=1;i<=NF;i++)a[$i,NR]++}{for(j in a){split(j,b,SUBSEP);if(b[2]==NR)printf b[1]" "} printf "\n"}' file
说明:本方法巧妙的利用了awk的数组,a[$i,NR]将读入的数据以域和行号为下标,只要本行的列中有重复数据则以该数据和该行行号为下标的数组元素加1。后面通过for循环取出下标,用split(j,b,SUBSEP)将两个下标分离赋值给新的数组b,此时b[1]中的数据就是我们想要的(不重复的列),最后判断b[2]与行号相等的则打印b[1]。执行命令后结果如下:
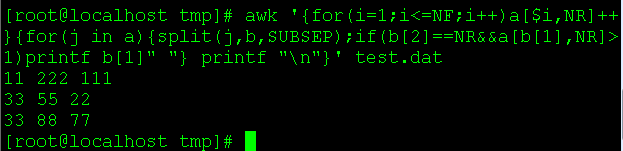
如果只想打印重复列,只需a数组的之是否大于1:awk '{for(i=1;i<=NF;i++)a[$i,NR]++}{for(j in a){split(j,b,SUBSEP);if(b[2]==NR&&a[b[1],NR]>1)printf b[1]" "} printf "\n"}' file
执行结果如下:
补充:
awk的二维数组使用
awk的多维数组在本质上是一维数组,更确切一点,awk在存储上并不支持多维数组。awk提供了逻辑上模拟二维数组的访问方式。例如,array[2,4] = 1这样的访问是允许的。awk使用一个特殊的字符串SUBSEP (\034)作为分割字段,在上面的例子中,关联数组array存储的键值实际上是2\0344。
类似一维数组的成员测试,多维数组可以使用 if ( (i,j) in array)这样的语法,但是下标必须放置在圆括号中。
类似一维数组的循环访问,多维数组使用 for ( item in array )这样的语法遍历数组。与一维数组不同的是,多维数组必须使用split()函数来访问单独的下标分量。split ( item, subscr, SUBSEP)。
转载于:https://blog.51cto.com/linux521/764555














 5829
5829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









