







前文已经讲解很清晰,Spark Streaming是通过定时器按照DStream 的DAG 回溯出整个RDD的DAG。
细心的读者一定有一个疑问,随着时间的推移,生产越来越多的RDD,SparkStreaming是如何保证RDD的生命周期的呢?
我们直接快进到JobGenerator中,

交由JobHandler执行,JobHandler是一个Runnable接口
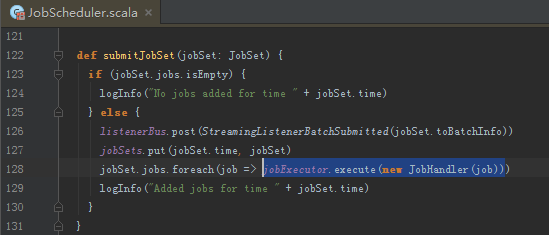 ,
,
咱们已经阅读过JobStarted事件,继续往下看。
// JobScheduler.scala line 202 spark 1.6.0
def run() {
try {
val formattedTime = UIUtils.formatBatchTime(
job.time.milliseconds, ssc.graph.batchDuration.milliseconds, showYYYYMMSS = false)
val batchUrl = s"/streaming/batch/?id=${job.time.milliseconds}"
val batchLinkText = s"[output operation ${job.outputOpId}, batch time ${formattedTime}]"
ssc.sc.setJobDescription(
s"""Streaming job from $batchLinkText""")
ssc.sc.setLocalProperty(BATCH_TIME_PROPERTY_KEY, job.time.milliseconds.toString)
ssc.sc.setLocalProperty(OUTPUT_OP_ID_PROPERTY_KEY, job.outputOpId.toString)
// We need to assign `eventLoop` to a temp variable. Otherwise, because
// `JobScheduler.stop(false)` may set `eventLoop` to null when this method is running, then
// it's possible that when `post` is called, `eventLoop` happens to null.
var _eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobStarted(job, clock.getTimeMillis())) // 之前已经解析过。
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobCompleted(job, clock.getTimeMillis())) // 本讲的重点在此。
}
} else {
// JobScheduler has been stopped.
}
} finally {
ssc.sc.setLocalProperty(JobScheduler.BATCH_TIME_PROPERTY_KEY, null)
ssc.sc.setLocalProperty(JobScheduler.OUTPUT_OP_ID_PROPERTY_KEY, null)
}
}

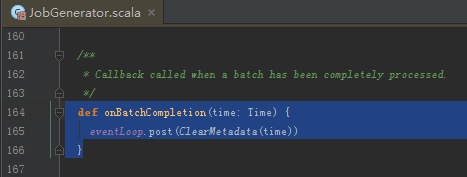


清理RDD

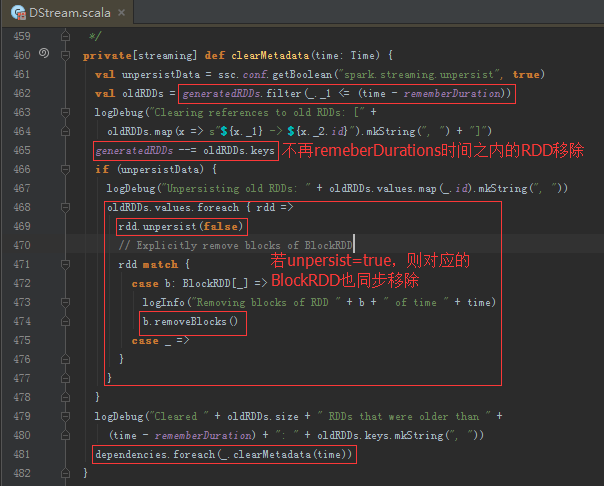

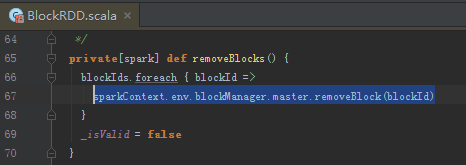
清理Checkpoint
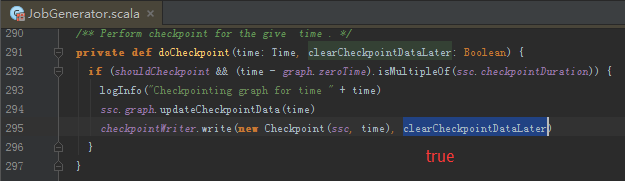

// Checkpoint.scala line 196
def run() {
// ... 代码...
jobGenerator.onCheckpointCompletion(checkpointTime, clearCheckpointDataLater)
return
} catch {
case ioe: IOException =>
logWarning("Error in attempt " + attempts + " of writing checkpoint to "
+ checkpointFile, ioe)
reset()
}
}
logWarning("Could not write checkpoint for time " + checkpointTime + " to file "
+ checkpointFile + "'")
}
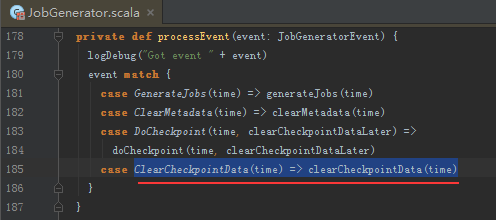
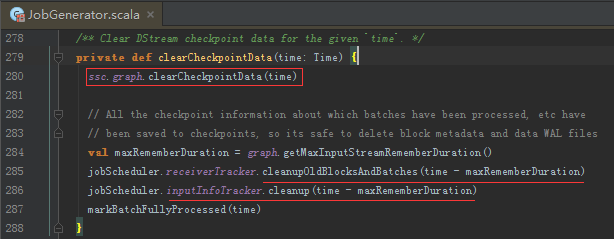
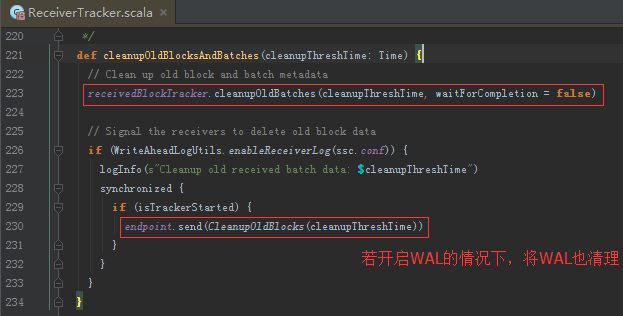
清理ReceiverTracker的block和batch




清理InputInfo
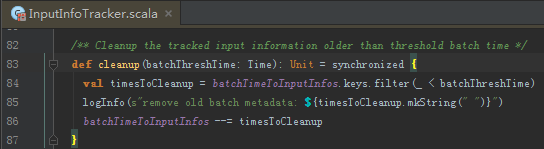
至此,所有的清理工作已经完成。
总结下:
JVM中对不使用的对象有GC,Spark Streaming中也是如此。
清理对象如下:
- Job
- RDD
- InputInfo
- Block 和 batch
- checkpoint的数据
- WAL的数据
最后配上日志截图:
















 6811
6811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









