







SparkSQLExample
private def runBasicDataFrameExample(spark: SparkSession): Unit = {
val df = spark.read.json("hdfs://master:9000/sparkfiles/people.json")
df.show()
import spark.implicits._
df.printSchema()
df.select("name").show()
df.select($"name", $"age" + 1).show()
df.filter($"age" > 21).show()
df.groupBy("age").count().show()
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
}
people.json的文件内容如下所示:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
首先是读取文件,构建一个DataFrame,而DataFrame定义在package object sql当中,其实质上是Dataset[Row]的别名。
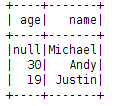
之后我们看一下df.show(),它的输出是这个样子的(真不嫌麻烦):
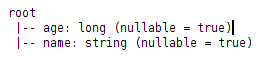
df.printSchema()输出的是json的结构信息:
df.select("name").show(),对于select方法而言,返回的还是一个DataFrame,当中只包含一列name。
df.select($"name", $"age" + 1).show(),返回一个DataFrame,所有人的年龄+1。
df.groupBy("age").count().show(),这行代码我们需要详细说一下,首先,groupBy的返回值是一个RelationalGroupedDataset, A set of methods for aggregations on a DataFrame, created by Dataset.groupBy. 当中提供了min,max,count等等聚合函数。count的结构又是一个DataFrame
最后一段很有趣,可以临时创建一个view,然后用sql进行查询。
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









