






树的查找
查找,又叫作搜索 search。查找跟遍历的概念不同,遍历是全部的节点都要走一遍,而查找,找到目标节点就立刻返回,不会继续遍历了。当然,如果什么都没查找到,就是一次完整的遍历过程了。
查找的依据是什么?假设我们对 K/V 结构,也就是 Map,对其增加 id 字段,用来作为查找的依据,那么用户输入如果符合 id 就返回节点,表示查找成功。
单层的查找很好做,在递归的函数里 if(id = map.get("id") ) 判断一下就可以了。JSON 是多层的,怎么做多层的呢?
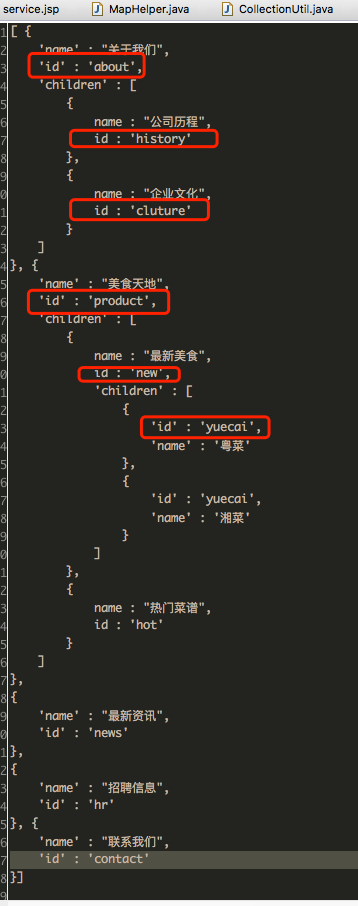
还是那个 json 例子,已经有 id 字段存在了。我们希望输入查找条件如 "product/new/yuecai" 返回 {id:yuecai, name : 粤菜} 这个节点。
调用方式如下
JsonStruTraveler t = new JsonStruTraveler();
assertEquals("关于我们", t.findByPath("about", list).get("name"));
assertEquals("企业文化", t.findByPath("about/cluture", list).get("name"));
assertEquals("粤菜", t.findByPath("product/new/yuecai", list).get("name"));findByPath 返回是 map 类型,就是这个节点。如果你有了解过 JSONPath,其实是有点相似的。
由于水平有限,当前只能做的从根节点一步一步查找,非常简单的原理。不支持从非第一级节点开始的查找。
查找的原理
原理还是非常简单,依然是递归的调用。不过在输入条件的处理上,使用了一点技巧,就是队列的运用。
/**
*
* 根据路径查找节点
* @param str
* Key 列表字符
* @param list
* 列表
* @return Map
*/
public Map<String, Object> findByPath(String str, List<Map<String, Object>> list) {
if (str.startsWith("/"))
str = str.substring(1, str.length());
if (str.endsWith("/"))
str = str.substring(0, str.length() - 1);
String[] arr = str.split("/");
Queue<String> q = new LinkedList<>(Arrays.asList(arr));
return findByPath(q, list);
}
/**
* 真正的查找函数
*
* @param stack
* 栈
* @param list
* 列表
* @return Map
*/
@SuppressWarnings("unchecked")
private Map<String, Object> findByPath(Queue<String> queue, List<Map<String, Object>> list) {
Map<String, Object> map = null;
while (!queue.isEmpty()) {
map = findMap(list, queue.poll());
if (map != null) {
if (queue.isEmpty()) {
break;// found it!
} else if (map.get(children) != null) {
map = findByPath(queue, (List<Map<String, Object>>) map.get(children));
} else {
map = null;
}
}
}
return map;
}首先拆分输入的字符串,变为队列( Queue 窄化了 LinkedList)。当 findMap 函数找到有节点,此时已消耗了队列的一个元素(queue.poll())。如果队列已经空了,表示已经查找完毕,返回节点。否则再看看下级节点 children 是否有,这一步是递归的调用,私有函数 private Map<String, Object> findByPath 就是专门为递归用的函数。
如果不使用队列,也可以完成,但就比较累,要自己写多几行代码控制,就操作如下代码。
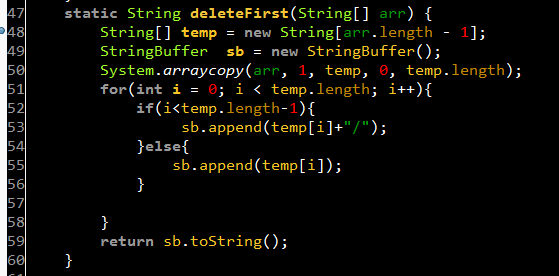
最开始的时候,我先想到的不是 队列,而是 栈。后来想想了,生成栈的过程比较繁琐,因为字符串 split 之后,是要反转数组才能变为栈的:
String[] arr = str.split("/");
Stack<String> stack = new Stack<>();
for (int i = arr.length - 1; i >= 0; i--)
stack.push(arr[i]);而后来想了下既然要反转数组,那不与直接使用与栈相反的 队列 好了。这里用栈或是队列是有差别的但差别不大,我们只是避免手写更多的行数来控制数组,对精简代码有好处。
扁平化 Map
JSON 树变成 MapList 之后,仍然是多层结构,如访问其中某个值(注意不是“节点”),必须逐级别访问。每级访问时都要判断对象是否为空,这就是要避免的 Java 空指针问题。例如 ((Map<String, Object>)list.get(0)).get("level"),比较繁琐。于是,我们希望可以写一个表达式就可以直接访问某个节点。上述如 product/new/yuecai 路径的方式是一种思路;这里再介绍一种不同的方式,它把 / 变成 . 如 product.new.yuecai,而且内部实现完全不同,速度会快很多。这就是扁平化 Map。
之所以强调扁平化 Map 中的 Map ,其意思是只强调处理 K/V 的 Map,输入类型要求是 Map,对于遇到 List 类型的 Value 不会去区分那是值还是子节点,一律当作下一级的子节点集合处理。这与“product/new/yuecai” 指定 children 项的方式来处理子集合稍有区别的,后者要求输入的是 List。而且前者通常是返回某个值,后者返回的是节点(Map),返回的内容其意义不一样。
首先定义内部接口 TravelMapList_Iterator,有三个方法:
/**
* 遍历 MapList 的回调
* @author Frank Cheung frank@ajaxjs.com
*/
public static interface TravelMapList_Iterator {
/**
* 当得到了 Map 的 key 和 value 时调用
*
* @param key 键名称
* @param obj 键值
*/
public void handler(String key, Object obj);
/**
* 当得到一个新的 key 时候
* @param key 键名称
*/
public void newKey(String key);
/**
* 当退出一个当前 key 的时候
* @param key 键名称
*/
public void exitKey(String key);
}接着定义递归函数遍历 MapList
/**
* 遍历 MapList,允许 TravelMapList_Iterator 控制
*
* @param map
* 输入 Map
* @param iterator
* 回调
*/
@SuppressWarnings("unchecked")
public static void travelMapList(Map<String, Object> map, TravelMapList_Iterator iterator) {
for (String key : map.keySet()) {
Object obj = map.get(key);
if (iterator != null)
iterator.handler(key, obj);
if (obj != null) {
if (obj instanceof Map) {
if (iterator != null)
iterator.newKey(key);
travelMapList((Map<String, Object>) obj, iterator);
if (iterator != null)
iterator.exitKey(key);
} else if (obj instanceof List) {
List<Object> list = (List<Object>) obj;
for (Object item : list) {
if (item != null && item instanceof Map)
travelMapList((Map<String, Object>) item, iterator);
}
}
}
}
}TravelMapList_Iterator 到底有什么用?说到底是为了进栈和退栈用的。堆栈有后入先出的特性,在这里使用最适合不过了——用来记录所在层级。
/**
* 扁平化多层 map 为单层
* @param map
* @return
*/
public static Map<String, Object> flatMap(Map<String, Object> map) {
final Stack<String> stack = new Stack<>();
final Map<String, Object> _map = new HashMap<>();
travelMapList(map, new TravelMapList_Iterator() {
@Override
public void handler(String key, Object obj) {
if (obj == null || obj instanceof String || obj instanceof Number || obj instanceof Boolean) {
StringBuilder sb = new StringBuilder();
for (String s : stack) {
sb.append(s + ".");
}
_map.put(sb + key, obj);
// System.out.println(sb + key + ":" + obj);
}
}
@Override
public void newKey(String key) {
stack.add(key); // 进栈
}
@Override
public void exitKey(String key) {
stack.pop(); // 退栈
}
});
return _map;
}外界调用 API 其实就是这个 flatMap 方法。
调用例子:
Map<String, Object> f_map = JsonStruTraveler.flatMap(map);
assertEquals(7, f_map.get("data.jobCatalog_Id"));输入 JSON
{
"site" : {
"titlePrefix" : "大华•川式料理",
"keywords" : "大华•川式料理",
"description" : "大华•川式料理饮食有限公司于2015年成立,本公司目标致力打造中国新派川菜系列。炜爵爷川菜料理系列的精髓在于清、鲜、醇、浓、香、烫、酥、嫩,擅用麻辣。在服务出品环节上,团队以ISO9000为蓝本建立标准化餐饮体系,务求以崭新的姿态面向社会各界人仕,提供更优质的服务以及出品。炜爵爷宗旨:麻辣鲜香椒,美味有诀窍,靓油用一次,精品煮御赐。 ",
"footCopyright":"dsds"
},
"dfd":{
"dfd":'fdsf',
"id": 888,
"dfdff":{
"dd":'fd'
}
},
"clientFullName":"大华•川式料理",
"clientShortName":"大华",
"isDebug": true,
"data" : {
"newsCatalog_Id" : 6,
"jobCatalog_Id" :7
}
}最后得到 map 结构是这样子的,根节点的话则没有 . (点)。
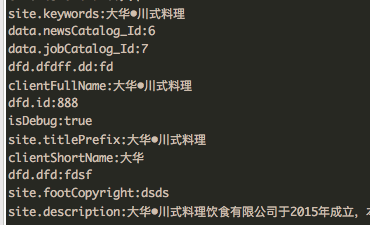
由于是 map 查找,所以查找的速度会很快。
格式化 JSON
如果对栈的技术不甚明了,可以尝试通过格式化 JSON 这个例子去理解。尽管这例子没有使用的栈,但是有相仿的地方,都是异曲同工的,大家可以细细品味。
/**
* 格式化 JSON,使其美观输出到控制或其他地方 请注意 对于json中原有\n \t 的情况未做过多考虑 得到格式化json数据 退格用\t
* 换行用\r
*
* @param json
* 原 JSON 字符串
* @return 格式化后美观的 JSON
*/
public static String format(String json) {
int level = 0;
StringBuilder str = new StringBuilder();
for (int i = 0; i < json.length(); i++) {
char c = json.charAt(i);
if (level > 0 && '\n' == str.charAt(str.length() - 1))
str.append(StringUtil.repeatStr("\t", "", level));
switch (c) {
case '{':
case '[':
str.append(c + "\n");
level++;
break;
case ',':
if (json.charAt(i + 1) == '"')
str.append(c + "\n"); // 后面必定是跟着 key 的双引号,但 其实 json 可以 key 不带双引号的
break;
case '}':
case ']':
str.append("\n");
level--;
str.append(StringUtil.repeatStr("\t", "", level));
str.append(c);
break;
default:
str.append(c);
break;
}
}
return str.toString();
}其中,level 表示缩进数,level++ 可看着“进栈”的操作,反之,level-- 为“退栈”,这一退一进是不是与栈的 push/pop 很像?
StringUtil.repeatStr 是重复字符串多少次的函数,比较简单,这里就不贴出了。















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









