







sql优化方法:
一、定位问题的方法:
1.通过AWR报表 :sql statis 查看有问
2.执行/u01/oracle/11g/rdbms/admin/ashrpt.sql 出一个sql报表
top sql
top pl/sql
3.通过dbms_system ,dbms_monitor 两个包去跟踪有问题的会话
dbms_system.set_sql_trace_in_session(sid,serial#,true) //打开以后跟踪DDL,DML,DQL操作,至少要跟踪5分钟
dbms_system.set_sql_trace_in_session(sid,serial#,true) //关闭跟踪 ,可以通过跟踪文件查询到有问题的sql
select sid,serial# from v$session; //查找到会话
select sql_id,sql_text from v$sql ;//可以查看到做了什么sql操作
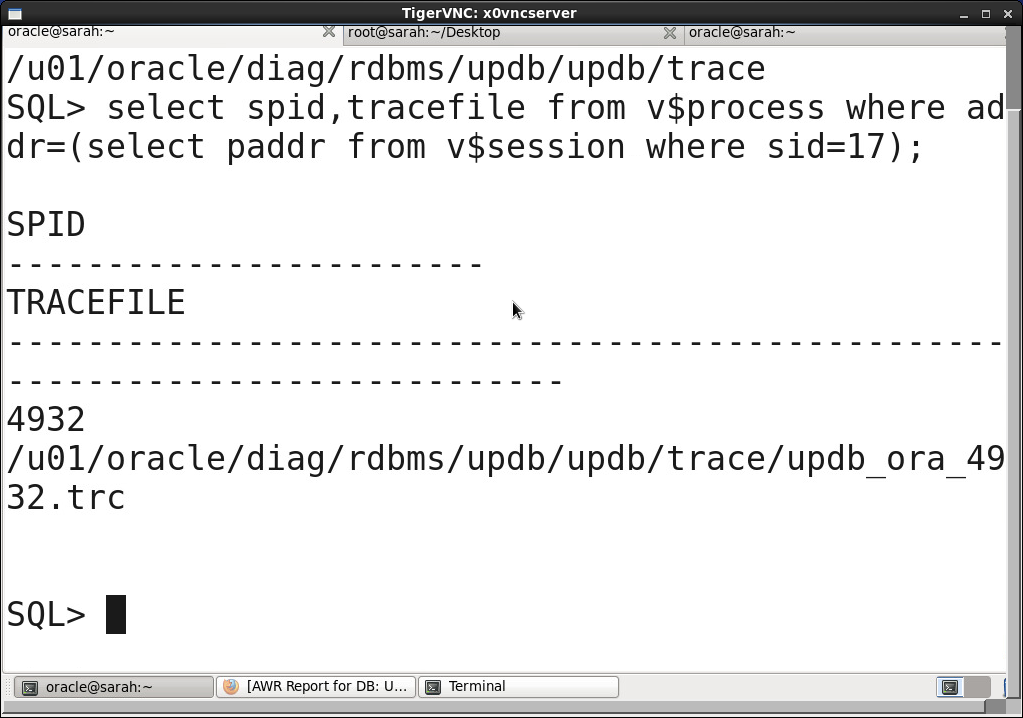
select spid from v$paddr, //tracefile 跟中

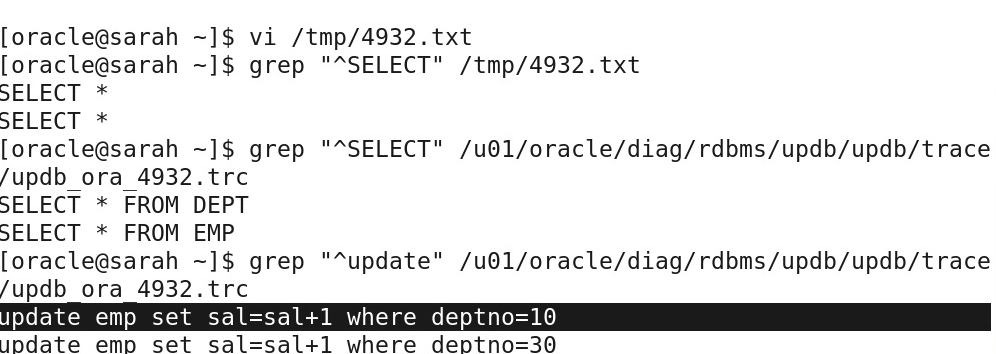
tkprof /u01/**/4931.trc /tmp/4932.txt //将跟踪文件转化为文本文件
4.dbms_monitor 通过跟踪的方式
desc dbms_monitor //查看使用方法
dbms_monitor.session_trace_enable (sid,serial#,true,true); //打开跟踪
。。。。。。。。 //操作
dbms_monitor.session_trace_disable(sid,serial#);//关闭跟踪
select spid,tarcefile from v$process where addr=(select paddr from v$session where sid=<>);
5.修改参数sql_trace 的方法,但是10g后已经不再使用因为会产生大量的跟踪文件
alter session set sql_trace=true; //打开跟踪文件,打开后做的所有操作都会记录到跟踪文件中。
alter system set sql_trace=true;//这个是跟踪系统中所有会话的操作,会产生大量的文件,建议一定不要使用
二、解读执行计划
set auto trace on //打开执行计划,可以看到我们语句的执行过程和结果,可以查看我们语句的性能
set auto trace exp //只查看执行计划
set auto trace stat //只查看统计信息
set auto trace //显示执行计划,统计信息
set auto off //关闭执行计划
以上在sqlplus中执行,其他的三方工具,我们直接F5就可以查看到执行计划
@ /u01/oracle/11g/sqlplus/admin/plustrce.sql //执行这个脚本后,在赋权给普通用户,普通用户就可以查看执行计划了
grant plustrace to scott ; //给普通用户赋权执行计划,普通用户就可以查看执行计划了
三、优化器(默认使用cbo)
rbo:rule 基于代价的优化器--10g以后已经基本不使用
cbo:cost 基于成本的优化器---all_rows 返回记录的所有值
show parameter _mode
SQL> show parameter _mode
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_mode string ALL_ROWS
remote_dependencies_mode string TIMESTAMP
result_cache_mode string MANUAL
SQL>
all_rows //cbo方式,代价最低,占用资源最少,相应的效率最高
cbo 依赖于统计信息,如果没有统计信息,cbo的值就不争取
如果没有统计信息我们就使用rbo --rbo只管返回结果而不管返回效率
SQL> alter system set optimizer_mode=1;
alter system set optimizer_mode=1
*
ERROR at line 1:
ORA-00096: invalid value 1 for parameter optimizer_mode, must be from among
first_rows_1000, first_rows_100, first_rows_10, first_rows_1, first_rows,
all_rows, choose, rule
//以最快的速度返回前多少条信息统计信息又称为动态采样:
更改的信息超过11% 10g才会收集统计信息
更改的信息超过13% 11g才会收集统计信息 ,晚上开始收集统计信息
采样等级:
一级:默认收集32个数据块
show parameter level //动态采样默认都是打开的
SQL> show parameter level;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
audit_syslog_level string
plsql_optimize_level integer 2
statistics_level string TYPICAL
二级:默认收集64个数据块
官方文档
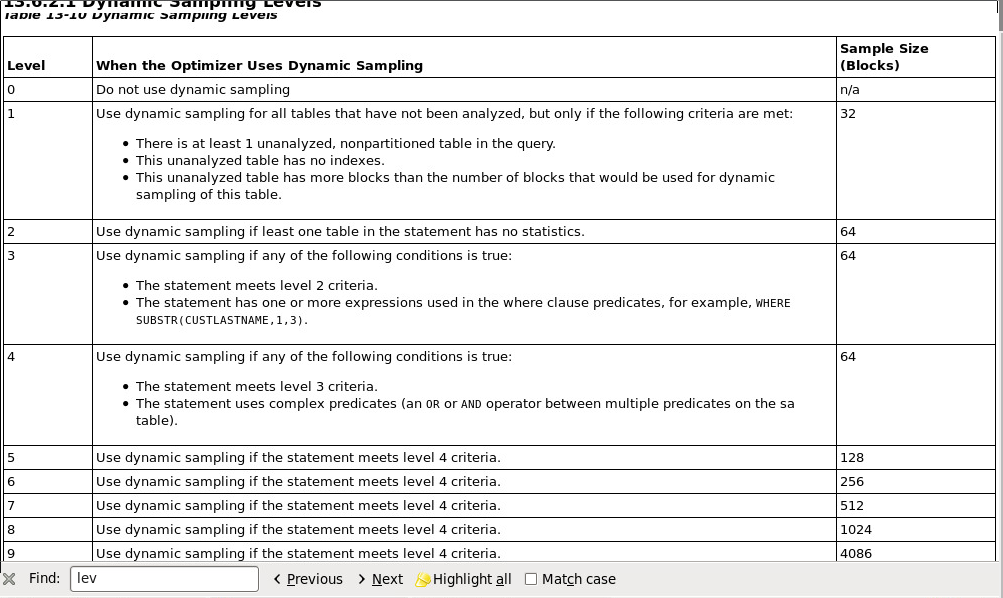
OLTP:不要使用动态采样
OLAP:数据量比较大,消耗时间比较长。但值得用动态采样
set autot trace stat
select * from tab;
SQL> set autot trace stat
SQL> select * from tab;
4872 rows selected.
Statistics
----------------------------------------------------------
15 recursive calls
0 db block gets
9604 consistent gets
0 physical reads
0 redo size
176486 bytes sent via SQL*Net to client
4088 bytes received via SQL*Net from client
326 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4872 rows processed
SQL> set autot trace stat
SQL> select * from tab;
4872 rows selected.
Statistics
----------------------------------------------------------
15 recursive calls //递归
0 db block gets
9604 consistent gets //读取数据块的个数
0 physical reads //.物理读,从磁盘文件中读取了多少数据
0 redo size //产生redo的大小
176486 bytes sent via SQL*Net to client //向客户段发送了多少个字节
4088 bytes received via SQL*Net from client //从客户端接受了多少个字节
326 SQL*Net roundtrips to/from client //
0 sorts (memory) //内存排序的次数
0 sorts (disk) //磁盘排序的次数
4872 rows processed
pins
dbms_shared_pool.keep('hash_value','a')
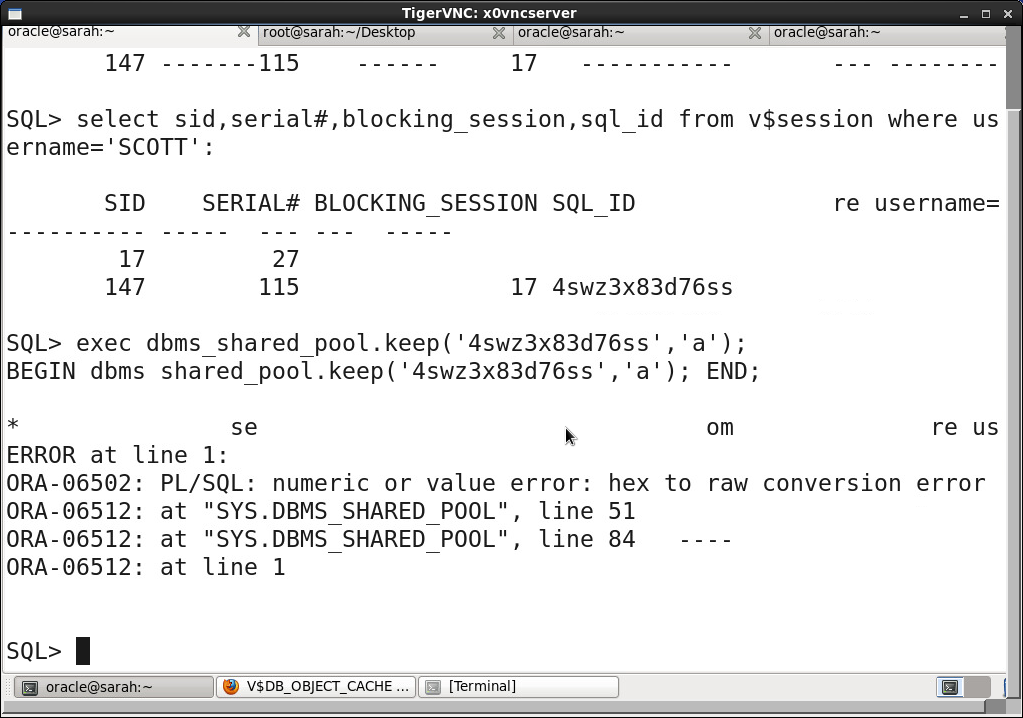
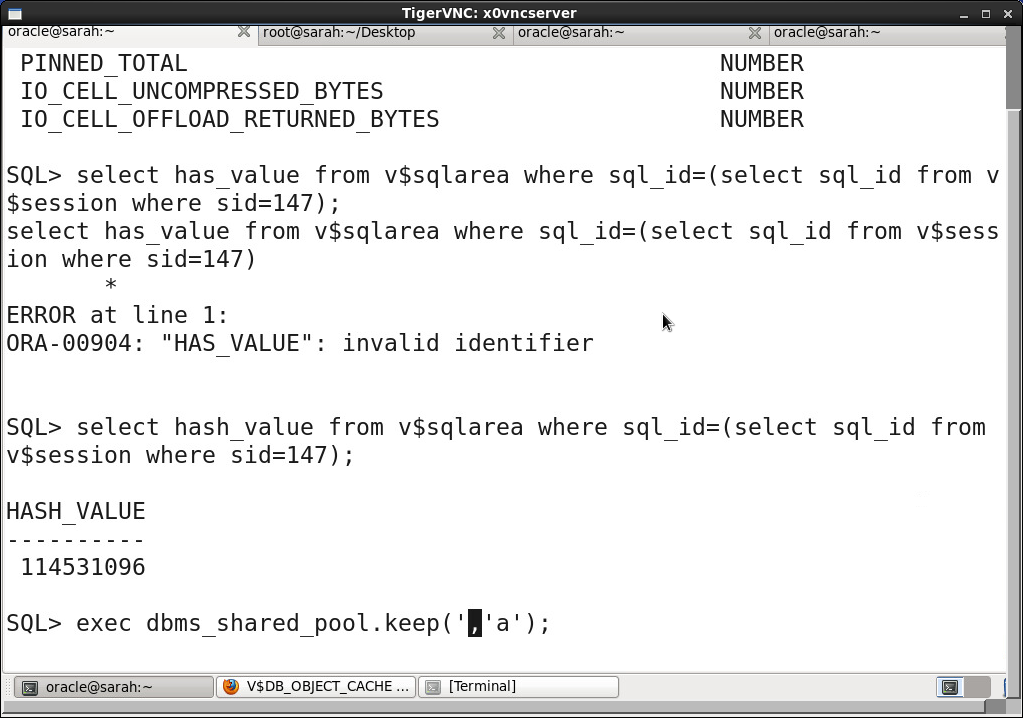
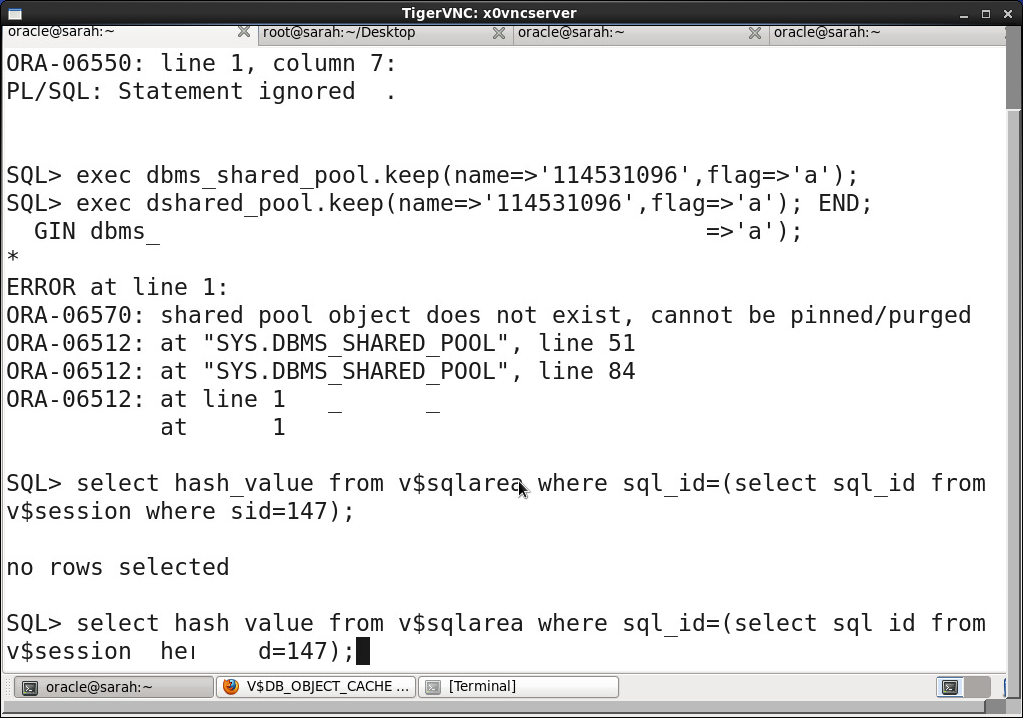
explain for select * from <>; //explain 方法查看执行计划
select * from tab(dbms_explain.display());
exec dbms_stats.gather_table_stats('owner','object_name');
exec dbms_stats.gather_index_stats(' ',' ');
exec dbms_stats.gather_schema_stats(' ');
exec dbms_stats.gather_database_stats(' ',' ');
analyze table <> compute statiscits;
analyze index <> computer statiscits;
select table_name ,to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss') from v$user_tables; //查看统计信息收集的时间
三、查看数据的访问方式
a.全表扫描
table access full //从第一个数据块开始扫描到最后一个数据块
2%返回的结果在全表的2%以下,效率就低,高于2%效率就高
show parameter db_file_m
SQL> show parameter db_file_m
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 100
linux----512k/8k=64 每次扫64块
没有浪费空间,效率才高
b.rowid 扫描---效率最高,rowid记录了数据的精确位置(几号数据文件,几号数据块)。缺点不支持多块扫描
select rowid from emp;
SQL> select rowid from emp;
ROWID
------------------
AAAS0SAAEAAAAILAAA
AAAS0SAAEAAAAILAAB
AAAS0SAAEAAAAILAAC
AAAS0SAAEAAAAILAAD
AAAS0SAAEAAAAILAAE
AAAS0SAAEAAAAILAAF
AAAS0SAAEAAAAILAAG
AAAS0SAAEAAAAILAAH
AAAS0SAAEAAAAILAAI
AAAS0SAAEAAAAILAAJ
AAAS0SAAEAAAAILAAK
ROWID
------------------
AAAS0SAAEAAAAILAAL
AAAS0SAAEAAAAILAAM
13 rows selected.
SQL> set autot trace exp;
SQL> select * from emp where rowid='AAAS0SAAEAAAAILAAA';
Execution Plan
----------------------------------------------------------
Plan hash value: 1116584662
--------------------------------------------------------------------------------
---
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
---
| 0 | SELECT STATEMENT | | 1 | 55 | 1 (0)| 00:00:0
1 |
| 1 | TABLE ACCESS BY USER ROWID| EMP | 1 | 55 | 1 (0)| 00:00:0
1 |
--------------------------------------------------------------------------------
---
c.索引扫描
1>索引范围扫描
2>索引全扫描
3>索引快速扫描
4>索引唯一性扫描
desc ind_column
1)使用算术表达式,索引无效,我们只能重建我们的索引成算术表达式的索引
2)使用函数,索引无效,优化方法,要么改写语句,要么将索引改为函数索引
3)索引列有空值,使用is null,is not null 索引无效,优化方法,避免使用这样的语句
4)索引中大量使用union,索引无效,优化方法,union(会去重排序)改为union all(不会去重排序)
d.表连接
1.表的敲套连接:适合用于一张表是大表,一张表是小表,小表作为驱动表,大表作为被驱动表。这样的访问效率是最高的。(工作中适合用)
强制嵌套连接
/*+ use_nl(table_name,table_name ...) */
2.表的合并排序连接(两个表都是大表,因为要排序要消耗大量的内存)
强制合并连接:/*+ use_merge (table_name,table_name ..) */
3.hash连接(两个表都是小表)
强制hash连接 :/*+ use_hash (table_name ,table_name...) */














 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









