






=== 相关系数与协方差 ===
相关系数(Correlation coeffieient):
是研究变量之间线性相关程度的量,一般用字母 r 表示。
协方差(Convariance,COV):
反应了两个样本之间的相互关系和关联程度。
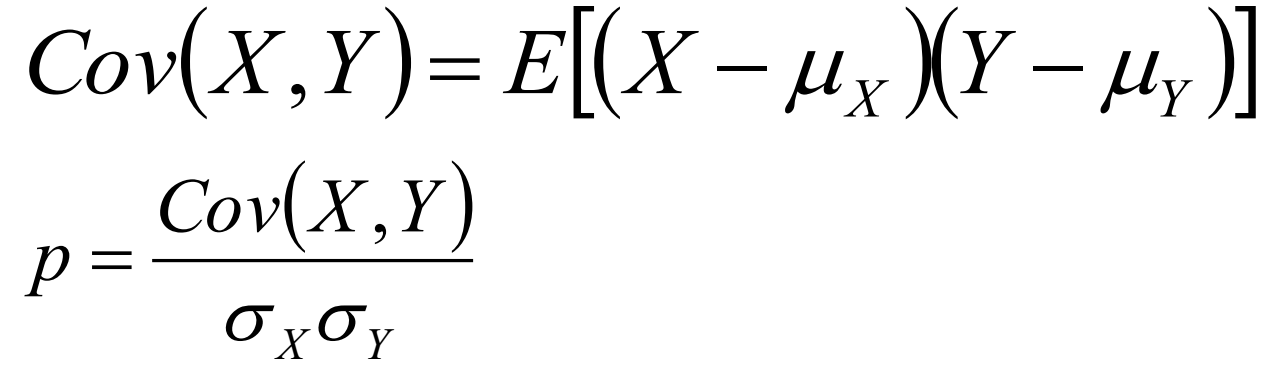
协方差COV
有一组年龄和身高的数据
import pandas as pd
import numpy as np
data = pd.DataFrame({
"年龄":[8,9,10,11,12],
"身高":[130,135,140,141,150]
})
1、协方差
研究年龄和身高成一个什么样的关系
data['年龄'].cov(data['身高'])
11.5
如果返回的是正数,代表两组数据“同向”发展,数值越大,“同向”程度越高
这组数据的返回值是11.5,代表年龄的身高之间还是有点关系的
如果身高的数据改成 "身高":[150,145,140,131,130] 越长越矮
则返回 -11.5,代表两组数据“反向”发展,数值越大,“反向”程度越高
2、 相关系数 - 判断两组数据是否相似
取值为[-1,1] 越接近1,代表相似程度越高
data['年龄'].corr(data['身高'])
0.9745412767961823
如果将身高其中一项改成145,使得数据完全相似
"身高":[130,135,140,145,150]
即年龄每长1岁,身高必长5厘米
则返回值为1,表示完全相似
=== 去重 ===
stu_info = pd.read_excel('student_info1.xlsx',sheetname='countif').head(5)
stu_info
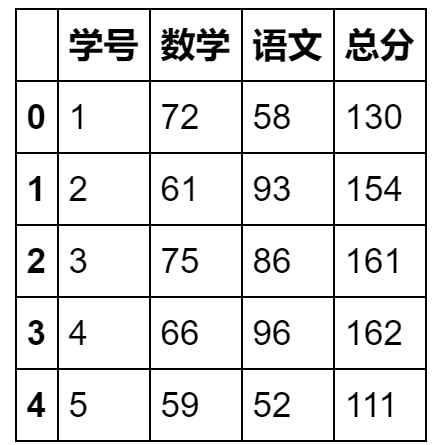
数据去重 unique
unique只能针对Series进行去重
print(type(stu_info))
print(type(stu_info['语文']))
print(type(stu_info['语文'].unique()))
stu_info['语文'].unique()
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
<class 'numpy.ndarray'>
array([58, 93, 86, 96, 52], dtype=int64)
=== 计数 ===
每个成绩出现的次数 value_counts
value_counts只能用于Series
stu_info['语文'].value_counts()
86 1
93 1
52 1
58 1
96 1
Name: 语文, dtype: int64
=== 成员资格 ===
判断DataFrame的Series中是否存在某个值
语文成绩中是否有93或96
stu_info['语文'].isin([93,96])
0 False
1 True
2 False
3 True
4 False
Name: 语文, dtype: bool














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









