






在之前写过
记一次数据同步需求的改进(一)之后,就开始着手对这个需求进行实践。
所谓实践出真知,在实际做的时候才发现可能计划的再好,做的时候还真不是那么回事。
在之前的邮件中已经确认目标库是一个统计分析库,首先拿到这个环境,先调查一番,发现了一个奇怪的现象。
查看这个库的归档情况的时候发现这个库每天的凌晨开始要切换20多次日志。
Redo Switch times per hour STATDB1 2015-Oct-28 11:37:52
MON DA 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23
--- -- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----
10 25 27 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
10 26 25 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
10 27 27 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
10 28 27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
可以抓取近几天的归档情况的图表来进一步验证,每天都会如此。可以看到在特定的时间内确实都发生一些额外的资源消耗,这是非常奇怪的。
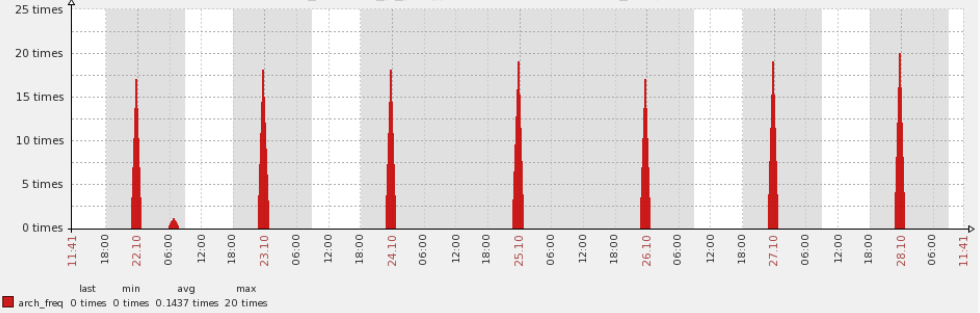
查看DB time的情况,发现在零点的时候也会出现一个大的抖动,这个是需要格外注意的。
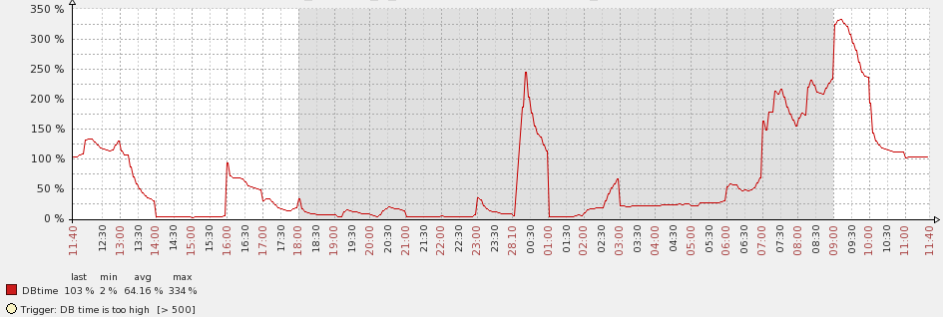
出于谨慎起见,准备先来分析一个这个问题,没想到这个问题对目前的这个需求来说意义重大,也算歪打正着。
首先查看了在问题时间段sql的DB time使用情况
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
37828 4yf9vjwa2yg5j 14 1433s 35%
37828 20v7cntjrscg7 1 725s 18%
37828 6yxdqb7mj3jys 5966 632s 15%
37828 d0hhst2fhvmsb 18 383s 9%
37828 1n3gxw12c2pap 12 99s 2%
然后逐个分析sql,发现sql_id 20v7cntjrscg7对应的sql竟然是一个job,每天都会尝试全量同步一次数据,当然这个代价还是很高的
$ sh showsqltext.sh 20v7cntjrscg7
DECLARE job BINARY_INTEGER := :job; next_date TIMESTAMP WITH TIME ZONE := :mydate; broken BOOLEAN := FALSE; job_name VARCHAR2(30) := :job_name; jo
b_subname VARCHAR2(30) := :job_subname; job_owner VARCHAR2(30) := :job_owner; job_start TIMESTAMP WITH TIME ZONE := :job_start; job_scheduled_start
TIMESTAMP WITH TIME ZONE := :job_scheduled_start; window_start TIMESTAMP WITH TIME ZONE := :window_start; window_end TIMESTAMP WITH TIME ZONE := :w
indow_end; chain_id VARCHAR2(14) := :chainid; credential_owner varchar2(30) := :credown; credential_name varchar2(30) := :crednam; destination_o
wner varchar2(30) := :destown; destination_name varchar2(30) := :destnam; job_dest_id varchar2(14) := :jdestid; log_id number := :log_id; BEGIN d
eclare
v_owner varchar2(30);
begin
execute immediate 'truncate table accstat.TEST_PROTECT_LOG';
v_owner :='ACC00';
accstat.LOAD_TEST_PROTECT_LOG(v_owner);
commit;
dbms_session.close_database_link(v_owner);
v_owner :='ACC02';
accstat.LOAD_TEST_PROTECT_LOG(v_owner);
commit;
。。。
:mydate := next_date; IF broken THEN :b := 1; ELSE :b := 0; END IF; END;
这个过程首先是truncate表然后开始通过db link来从各个源端来同步数据到这个表中,至于刷新细节是在一个存储过程LOAD_TEST_PROTECT_LOG中做的,其实所做的工作就是insert的方式,只是使用了bulk collect,和insert all等方式进行了包装和改进,所以每天都在默默的进行一次全量的同步,当然如果是一个简单的性能问题也就罢了,关键是开发需要我同步的其中一张表就是这个job中正在同步的表,所以我产生了一些问题。
经过和开发的同事沟通,他们对这个部分目前没有使用需求,和同事聊了聊,他们说印象中这种同步都是已经禁掉了,但是看来还是存在一个漏网之鱼,每天都在默默的进行着同步,而且没有使用到,想想就觉得悲凉。
所以发现了这个问题之后,开始重新审视这个需求,首先这个表是一个历史记录表,对于开发来说只需要去读取即可。然后他们需要的是增量数据,每天进行一次同步,如果按照这个需求,目前的job所做的工具已经满足了,可以直接告诉开发需求已经满足了即可,但是我DBA的角度来说,这个实现方式让人感觉还是太过于浪费,每天都需要全量同步一次数据,而且数据量也不小,每天同步势必浪费了不少的资源。而且还有一个难点比较困扰我,就是源端存在10多个用户表,如果根据之前的需求时间字段来抽取数据,还是需要创建索引,所以这样还需要在源端逐个创建索引,这个工作量也比较大,而且对于在线关键业务影响也很大。
那么增量数据的同步还有什么好的办法吗,物化视图的增量刷新就是一个很好的解决方案,我们只需要在源端创建物化视图日志即可,然后在目标端创建物化视图,每次刷新都采用增量的刷新模式。这种增量和原来需求中的字段抽取方式是完全吻合的。
对于这一点,和开发同事进行了沟通,他们非常赞同,因为不需要创建索引,而且刷新的流程似乎更加简单了,对于他们来说也不需要做更多的评估工作了。其实对于DBA来说也是如此。
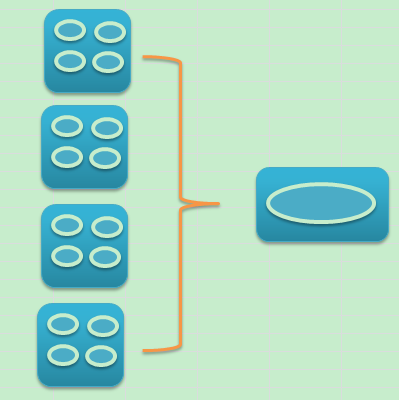
按照这种思路实现方式就会发生改变,原来的实现方式是这样的。
改进之后,需要创建一些物化视图来做增量刷新,方式就是下面的样子。
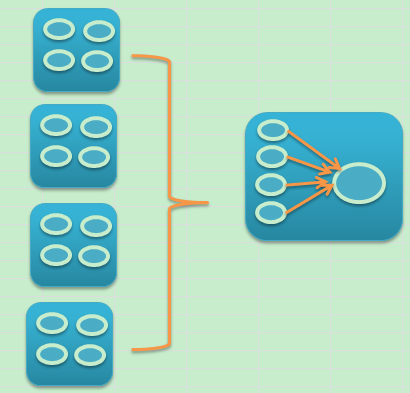
对于这种方式。实现方式如下,具体实现的时候也碰到了一些问题。
首先需要在源端创建物化视图日志,
> create materialized view log on acc00.test_protect_log;
Materialized view log created.
然后在目标端开始创建物化视图。但是奇怪的是竟然报错了。
SQL> create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00;
create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00
*
ERROR at line 1:
ORA-12018: following error encountered during code generation for
"ACCSTAT"."ACC00_TEST_PROTECT_LOG"
ORA-00942: table or view does not exist
Elapsed: 00:04:52.41
经过分析排查发现,db link基于的是一个源端的只读用户,没有物化视图日志的访问权限,所以简单修复即可。
在统计库中再次创建就没有问题了。
SQL> create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00;
Materialized view created.
Elapsed: 00:04:41.86
然后再次尝试刷新就很快了,因为是增量的方式,而且数据量相对要少很多。
SQL> exec dbms_mview.refresh('acc00_test_protect_log','F');
PL/SQL procedure successfully completed.
对于其它的源端用户表也进行了类似的操作,最开始的全量刷新还是会消耗一些额外的资源,但是以后就不会有这样的问题了。
最后一个问题就是对于开发人员来说,如何透明的显示为一个test_protect_log,可以直接使用视图来完成,因为开发只需要读取,不需要修改。
create or replace view accstat.test_protect_Log as
select * from ACCSTAT.ACC00_TEST_PROTECTLOG
union all
select * from ACCSTAT.ACC02_TEST_PROTECT_LOG
union all
。。。
当然工作做完了,刷新的过程还是很快的,基本十多秒回全部刷新完成。
最后来看看改进只有的归档情况,蓝色框中再也没有这种抖动了。
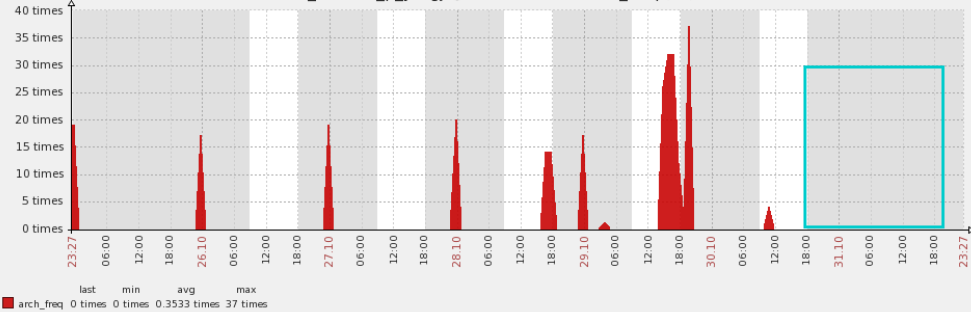
所以问题处理还是要谨慎,细心,考虑全面,多沟通,就去能有预期的改进。
所谓实践出真知,在实际做的时候才发现可能计划的再好,做的时候还真不是那么回事。
在之前的邮件中已经确认目标库是一个统计分析库,首先拿到这个环境,先调查一番,发现了一个奇怪的现象。
查看这个库的归档情况的时候发现这个库每天的凌晨开始要切换20多次日志。
Redo Switch times per hour STATDB1 2015-Oct-28 11:37:52
MON DA 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23
--- -- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----
10 25 27 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
10 26 25 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
10 27 27 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
10 28 27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
可以抓取近几天的归档情况的图表来进一步验证,每天都会如此。可以看到在特定的时间内确实都发生一些额外的资源消耗,这是非常奇怪的。
查看DB time的情况,发现在零点的时候也会出现一个大的抖动,这个是需要格外注意的。
出于谨慎起见,准备先来分析一个这个问题,没想到这个问题对目前的这个需求来说意义重大,也算歪打正着。
首先查看了在问题时间段sql的DB time使用情况
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
37828 4yf9vjwa2yg5j 14 1433s 35%
37828 20v7cntjrscg7 1 725s 18%
37828 6yxdqb7mj3jys 5966 632s 15%
37828 d0hhst2fhvmsb 18 383s 9%
37828 1n3gxw12c2pap 12 99s 2%
然后逐个分析sql,发现sql_id 20v7cntjrscg7对应的sql竟然是一个job,每天都会尝试全量同步一次数据,当然这个代价还是很高的
$ sh showsqltext.sh 20v7cntjrscg7
DECLARE job BINARY_INTEGER := :job; next_date TIMESTAMP WITH TIME ZONE := :mydate; broken BOOLEAN := FALSE; job_name VARCHAR2(30) := :job_name; jo
b_subname VARCHAR2(30) := :job_subname; job_owner VARCHAR2(30) := :job_owner; job_start TIMESTAMP WITH TIME ZONE := :job_start; job_scheduled_start
TIMESTAMP WITH TIME ZONE := :job_scheduled_start; window_start TIMESTAMP WITH TIME ZONE := :window_start; window_end TIMESTAMP WITH TIME ZONE := :w
indow_end; chain_id VARCHAR2(14) := :chainid; credential_owner varchar2(30) := :credown; credential_name varchar2(30) := :crednam; destination_o
wner varchar2(30) := :destown; destination_name varchar2(30) := :destnam; job_dest_id varchar2(14) := :jdestid; log_id number := :log_id; BEGIN d
eclare
v_owner varchar2(30);
begin
execute immediate 'truncate table accstat.TEST_PROTECT_LOG';
v_owner :='ACC00';
accstat.LOAD_TEST_PROTECT_LOG(v_owner);
commit;
dbms_session.close_database_link(v_owner);
v_owner :='ACC02';
accstat.LOAD_TEST_PROTECT_LOG(v_owner);
commit;
。。。
:mydate := next_date; IF broken THEN :b := 1; ELSE :b := 0; END IF; END;
这个过程首先是truncate表然后开始通过db link来从各个源端来同步数据到这个表中,至于刷新细节是在一个存储过程LOAD_TEST_PROTECT_LOG中做的,其实所做的工作就是insert的方式,只是使用了bulk collect,和insert all等方式进行了包装和改进,所以每天都在默默的进行一次全量的同步,当然如果是一个简单的性能问题也就罢了,关键是开发需要我同步的其中一张表就是这个job中正在同步的表,所以我产生了一些问题。
经过和开发的同事沟通,他们对这个部分目前没有使用需求,和同事聊了聊,他们说印象中这种同步都是已经禁掉了,但是看来还是存在一个漏网之鱼,每天都在默默的进行着同步,而且没有使用到,想想就觉得悲凉。
所以发现了这个问题之后,开始重新审视这个需求,首先这个表是一个历史记录表,对于开发来说只需要去读取即可。然后他们需要的是增量数据,每天进行一次同步,如果按照这个需求,目前的job所做的工具已经满足了,可以直接告诉开发需求已经满足了即可,但是我DBA的角度来说,这个实现方式让人感觉还是太过于浪费,每天都需要全量同步一次数据,而且数据量也不小,每天同步势必浪费了不少的资源。而且还有一个难点比较困扰我,就是源端存在10多个用户表,如果根据之前的需求时间字段来抽取数据,还是需要创建索引,所以这样还需要在源端逐个创建索引,这个工作量也比较大,而且对于在线关键业务影响也很大。
那么增量数据的同步还有什么好的办法吗,物化视图的增量刷新就是一个很好的解决方案,我们只需要在源端创建物化视图日志即可,然后在目标端创建物化视图,每次刷新都采用增量的刷新模式。这种增量和原来需求中的字段抽取方式是完全吻合的。
对于这一点,和开发同事进行了沟通,他们非常赞同,因为不需要创建索引,而且刷新的流程似乎更加简单了,对于他们来说也不需要做更多的评估工作了。其实对于DBA来说也是如此。
按照这种思路实现方式就会发生改变,原来的实现方式是这样的。
改进之后,需要创建一些物化视图来做增量刷新,方式就是下面的样子。
对于这种方式。实现方式如下,具体实现的时候也碰到了一些问题。
首先需要在源端创建物化视图日志,
> create materialized view log on acc00.test_protect_log;
Materialized view log created.
然后在目标端开始创建物化视图。但是奇怪的是竟然报错了。
SQL> create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00;
create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00
*
ERROR at line 1:
ORA-12018: following error encountered during code generation for
"ACCSTAT"."ACC00_TEST_PROTECT_LOG"
ORA-00942: table or view does not exist
Elapsed: 00:04:52.41
经过分析排查发现,db link基于的是一个源端的只读用户,没有物化视图日志的访问权限,所以简单修复即可。
在统计库中再次创建就没有问题了。
SQL> create materialized view acc00_test_protect_log refresh fast as select * from ACC00.test_protect_log@ACC00;
Materialized view created.
Elapsed: 00:04:41.86
然后再次尝试刷新就很快了,因为是增量的方式,而且数据量相对要少很多。
SQL> exec dbms_mview.refresh('acc00_test_protect_log','F');
PL/SQL procedure successfully completed.
对于其它的源端用户表也进行了类似的操作,最开始的全量刷新还是会消耗一些额外的资源,但是以后就不会有这样的问题了。
最后一个问题就是对于开发人员来说,如何透明的显示为一个test_protect_log,可以直接使用视图来完成,因为开发只需要读取,不需要修改。
create or replace view accstat.test_protect_Log as
select * from ACCSTAT.ACC00_TEST_PROTECTLOG
union all
select * from ACCSTAT.ACC02_TEST_PROTECT_LOG
union all
。。。
当然工作做完了,刷新的过程还是很快的,基本十多秒回全部刷新完成。
最后来看看改进只有的归档情况,蓝色框中再也没有这种抖动了。
所以问题处理还是要谨慎,细心,考虑全面,多沟通,就去能有预期的改进。














 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









