






Pandas是一个开源Python库,它在Python编程中提供数据分析和操作。
它是数据表示,过滤和统计编程中非常有前途的库。Pandas中最重要的部分是DataFrame,您可以在其中存储和播放数据。
在本教程中,您将了解DataFrame是什么,如何从不同的源创建它,如何将其导出到不同的输出,以及如何操作其数据。
安装熊猫
您可以使用pip在Python中安装Pandas 。在cmd中运行以下命令:
pip install pandas

此外,您可以使用conda安装Pandas,如下所示:
conda install pandas
阅读Excel文件
您可以使用read_excel() Pandas中的方法从Excel文件中读取 。为此,您需要再导入一个名为xlrd的模块。
使用pip安装xlrd:
pip install xlrd
下面的示例演示了如何从Excel工作表中读取:
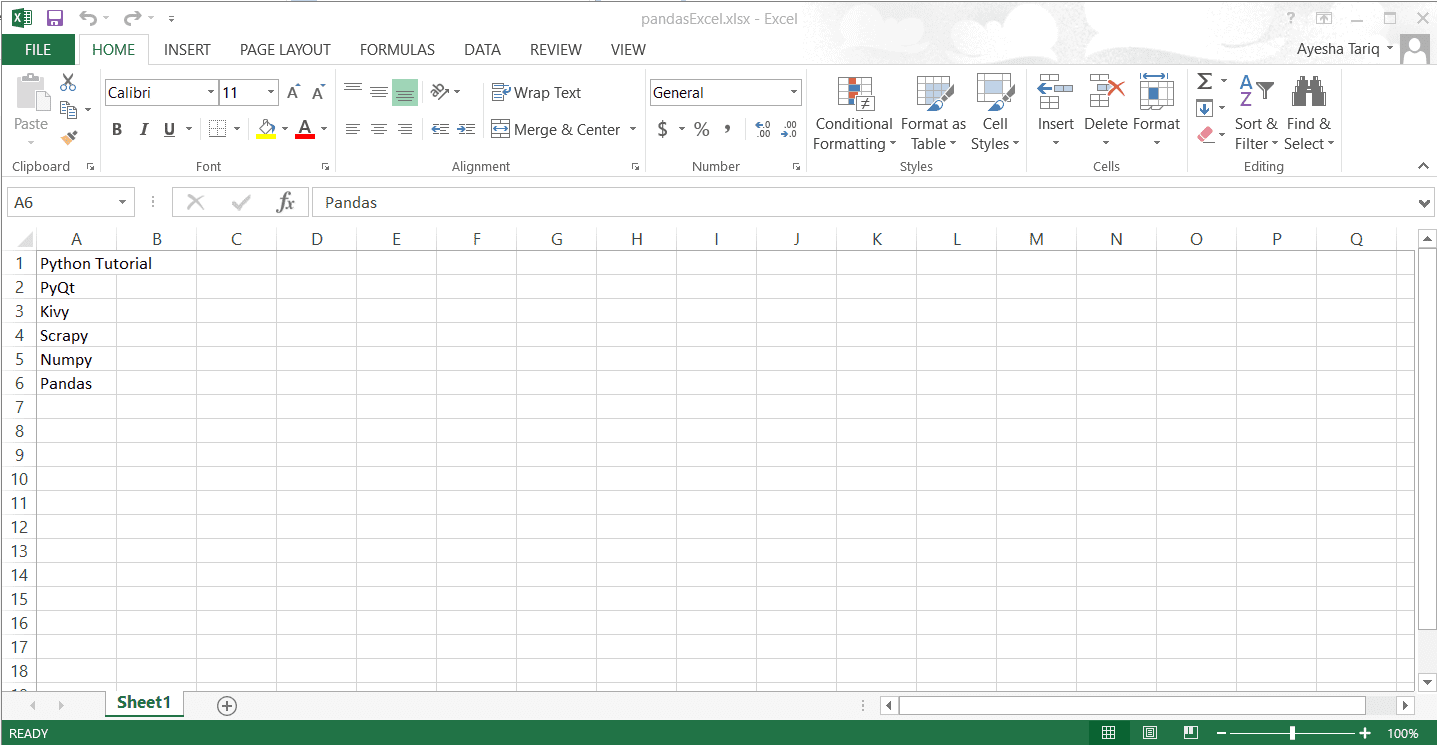
我们创建了一个包含以下内容的Excel工作表:
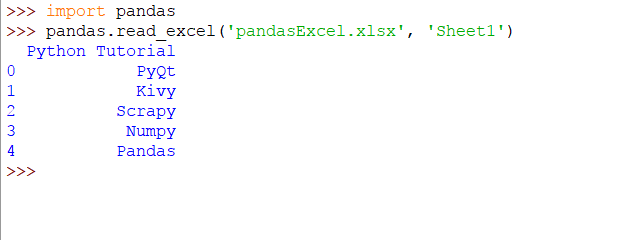
导入Pandas模块:
import pandas
上面的代码片段将生成以下输出:
如果使用type关键字检查输出的类型,它将为您提供以下结果:
< 类 'pandas.core.frame.DataFrame' >
这称为DataFrame!这是我们将在本教程中处理的Pandas的基本单元。
DataFrame是一个带标签的二维结构,我们可以存储不同类型的数据。DataFrame类似于SQL表或Excel电子表格。
导入CSV文件
要从CSV文件中读取,您可以使用read_csv() Pandas 的 方法。
导入pandas模块: import pandas
现在调用 read_csv() 方法如下:
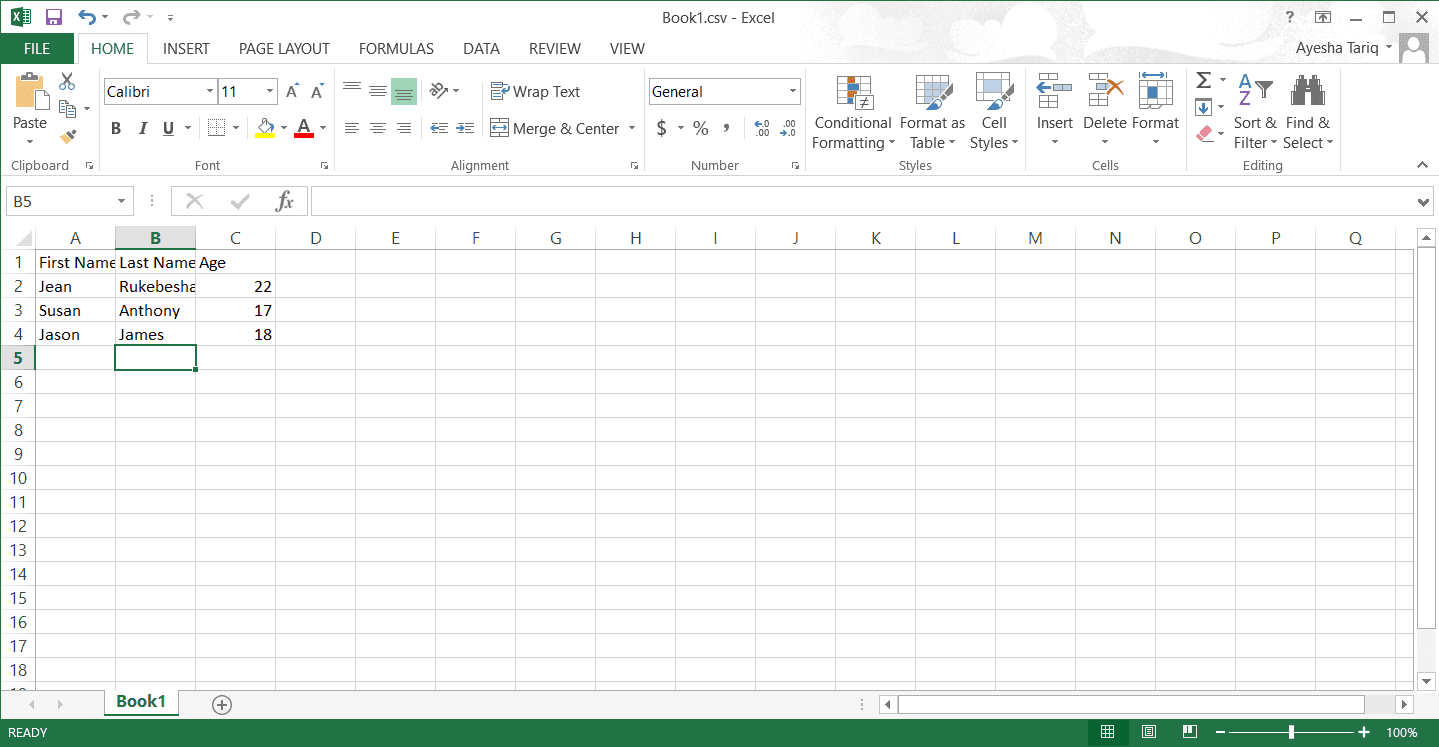
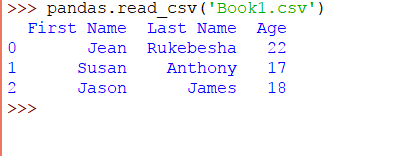
Book1.csv具有以下内容:
该代码将生成以下DataFrame:
阅读文本文件
我们也可以使用read_csv Pandas 的 方法从文本文件中读取; 考虑以下示例:
进口 大熊猫
大熊猫。read_csv('myFile.txt')
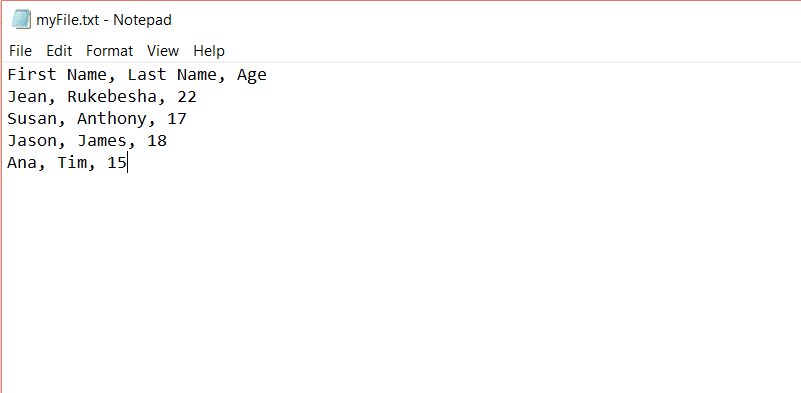
myFile.txt如下所示:
上面代码的输出将是:
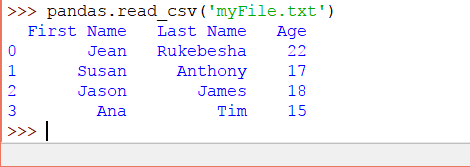
此文本文件被视为CSV文件,因为我们使用逗号分隔的元素。该文件还可以使用其他分隔符,例如分号,制表符等。
假设我们有一个制表符分隔符,文件如下所示:
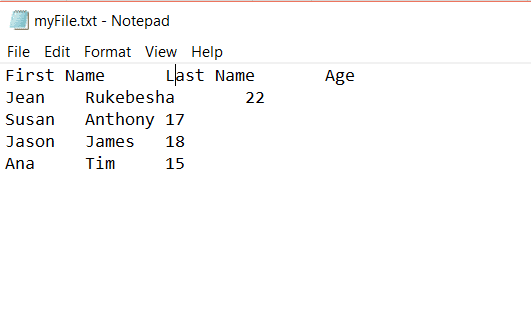
当分隔符是制表符时,我们将得到以下输出:
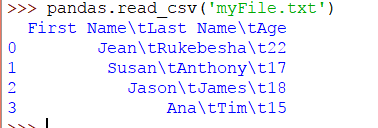
由于Pandas不知道分隔符,因此它将选项卡转换为\t。
要将制表符定义为分隔符,请传递分隔符参数,如下所示:
大熊猫。read_csv('myFile.txt',delimiter = '\ t')
现在输出将是:
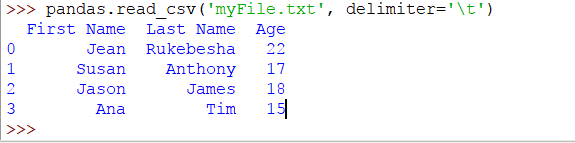
现在看起来正确。
阅读SQL
您可以使用read_sql() Pandas 的 方法从SQL数据库中读取。这在以下示例中进行了演示:
import sqlite3
进口 大熊猫
con = sqlite3。connect('mydatabase.db')
大熊猫。read_sql('select * from Employee',con)
在此示例中,我们连接到一个SQLite3数据库,该数据库具有名为“Employee”的表。使用read_sql() Pandas 的 方法,然后我们将查询和连接对象传递给该 read_sql() 方法。查询将获取表中的所有数据。
我们的Employee表如下所示:
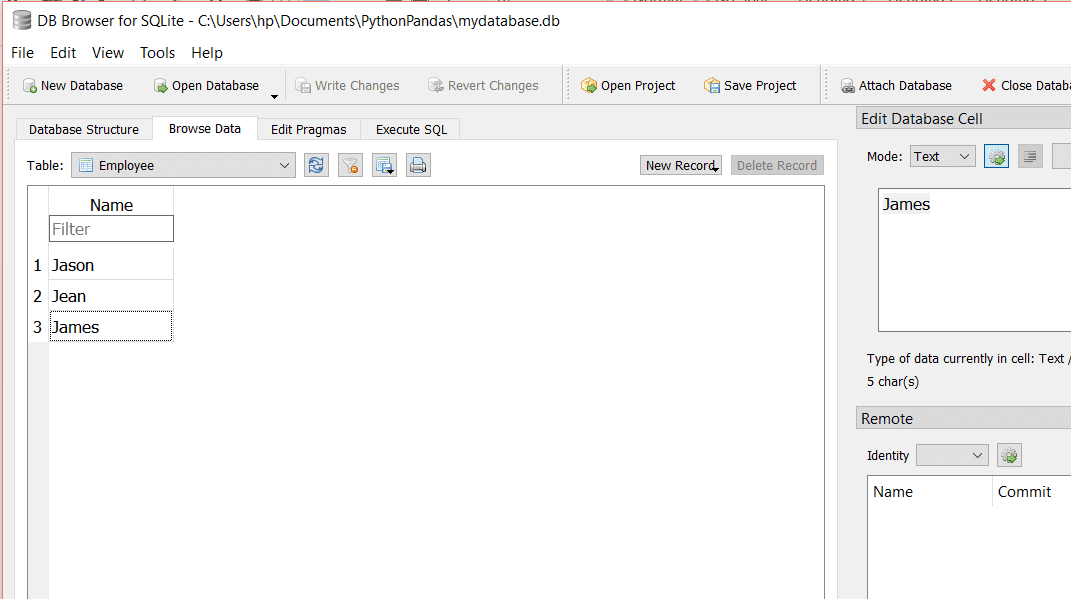
运行上面的代码时,输出将如下所示:

选择列
假设我们在Employee表中有三列,如下所示:
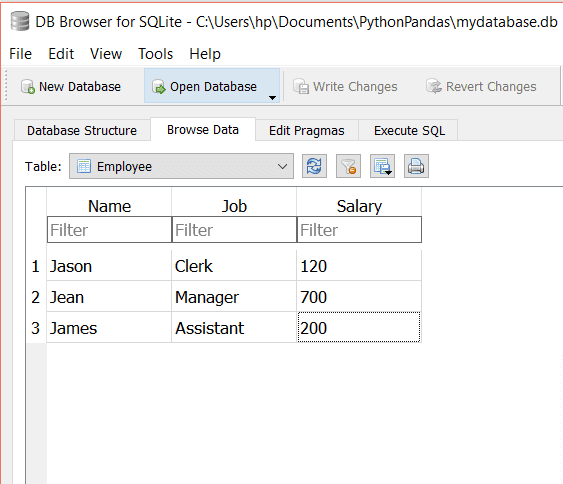
要从表中选择列,我们将传递以下查询:
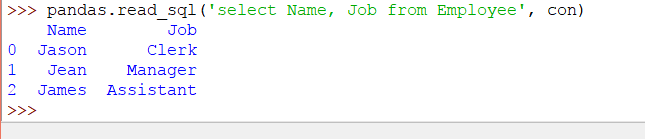
从员工中选择姓名,工作
Pandas代码声明如下:
大熊猫。read_sql('select Name,Job from Employee',con)
我们还可以通过访问DataFrame从表中选择一列。请考虑以下示例:
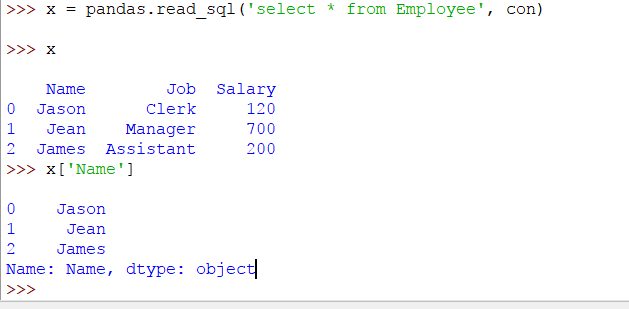
x = 熊猫。read_sql('select * from Employee',con)
x [ '姓名' ]
结果如下:
按值选择行
首先,我们将创建一个DataFrame,我们将从中选择行。
要创建DataFrame,请考虑以下代码:
进口 大熊猫
frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ] }
df = 熊猫。DataFrame(frame_data)
在这段代码中,我们使用DataFrame() Pandas 的方法创建了一个包含三列和三行的DataFrame 。结果如下:

要基于值选择行,请运行以下语句:
df。loc [ df [ 'name' ] == 'Jason' ]
df.loc[] 或者 DataFrame.loc[] 是一个布尔数组,可用于按值或标签访问行或列。在上面的代码中,将获取行,其中名称等于Jason。
输出将是:

选择按索引排序
要通过索引选择行,我们可以使用slicing(:)运算符或 df.loc[] 数组。
请考虑以下代码:
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ]}
>> > DF = 大熊猫。DataFrame(frame_data)
我们创建了一个DataFrame。现在让我们使用df.loc[]以下方法访问一行:
>>> df.loc[1]
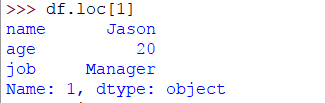
如您所见,获取了一行。我们可以使用切片运算符执行相同的操作,如下所示:
>>> df[1:2]
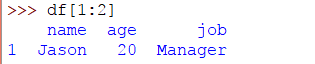
更改列类型
可以使用astype() DataFrame 的属性更改列的数据类型 。要检查列的数据类型,我们使用dtypes DataFrame 的 属性。
>>> df.dtypes
输出将是:

现在将数据类型从一个转换为另一个:
>> > DF。name = df。名字。astype(str)
我们从DataFrame中获取了列'name',并将其数据类型从object更改为string。
将函数应用于列/行
要在列或行上应用函数,可以使用apply() DataFrame 的 方法。
请考虑以下示例:
>> > frame_data = { 'A':[ 1,2,3 ],'B':[ 18,20,22 ],'C':[ 54,12,13 ]}
>> > DF = 大熊猫。DataFrame(frame_data)
我们创建了一个DataFrame,并在行中添加了整数类型的值。要在值上应用函数(例如平方根),我们将导入NumPy模块以使用sqrt 它中的 函数,如下所示:
>> > 进口 numpy的 为 NP
>> > DF。申请(NP。开方)
输出如下:
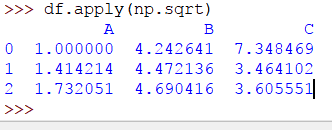
要应用该 sum 功能,代码将是:
>>> df.apply(np.sum)

要将函数应用于特定列,可以像这样指定列:
>>>df['A'].apply(np.sqrt)
排序值/按列排序
要对DataFrame中的值进行排序,请使用DataFrame的 sort_values() 方法。
使用整数值创建DataFrame:
>> > frame_data = { 'A':[ 23,12,30 ],'B':[ 18,20,22 ],'C':[ 54,112,13 ]}
>> > DF = 大熊猫。DataFrame(frame_data)
现在要对值进行排序:
>> > DF。sort_values(by = [ 'A' ])
输出将是:
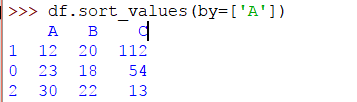
该 sort_values() 方法具有必要的属性“by”。在上面的代码中,值按列A排序。要按多列排序,代码将是:
>> > DF。sort_values(by = [ 'A','B' ])
如果要按降序排序,请将升序属性设置 set_values 为False,如下所示:
>> > DF。sort_values(by = [ 'A' ],ascending = False)
输出将是:

删除/删除重复项
要从DataFrame中删除重复行,请使用DataFrame的 drop_duplicates() 方法。
请考虑以下示例:
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯','杰森' ],'年龄':18,20,22,20 ],'工作':'助理','经理','职员','经理' ]}
>> > DF = 大熊猫。DataFrame(frame_data)
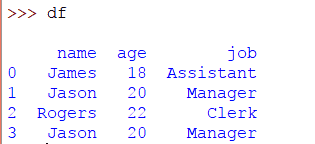
在这里,我们创建了一个具有重复行的DataFrame。要检查DataFrame中是否存在任何重复行,请使用DataFrame的 duplicated() 方法。
结果将是:

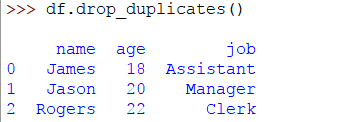
可以看出最后一行是重复的。要删除或删除此行,请运行以下代码行:
>> > DF。drop_duplicates()
现在的结果将是:
 按列删除重复项
按列删除重复项
有时,我们有数据列的值相同,我们希望删除它们。我们可以通过传递我们需要删除的列的名称来逐行删除。
例如,我们有以下DataFrame:
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯','杰森' ],'年龄':18,20,22,21 ],'工作':'助理','经理','职员','员工' ]}
>> > DF = 大熊猫。DataFrame(frame_data)

在这里你可以看到Jason是两次。如果要按列删除重复项,只需传递列名称,如下所示:
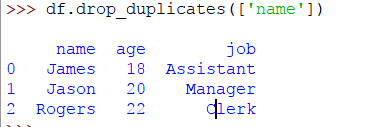
>> > DF。drop_duplicates([ 'name' ])
结果如下:
删除列
要删除整个列或行,我们可以drop() 通过指定列或行的名称来使用DataFrame 的 方法。
请考虑以下示例:
>> > DF。drop([ 'job' ],axis = 1)
在这行代码中,我们将删除名为“job”的列。这里需要axis参数。如果轴值为1,则表示我们要删除列,如果轴值为0,则表示将删除该行。在轴值中,0表示索引,1表示列。
结果将是:

删除行
我们可以使用该 drop() 方法通过传递行的索引来删除或删除行。
假设我们有以下DataFrame:
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ]}
>> > DF = 大熊猫。DataFrame(frame_data)
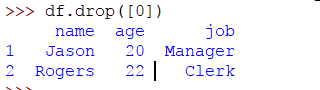
要删除索引为0的行,其中名称为James,age为18且作业为Assistant,请使用以下代码:
>>> df.drop([0])
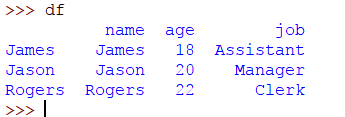
让我们创建一个DataFrame,索引是名称:
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ]}
>> > DF = 大熊猫。DataFrame(frame_data,index = [ 'James','Jason','Rogers' ])
现在我们可以删除具有特定值的行。例如,如果我们要删除名称为Rogers的行,则代码将为:
>>> df.drop(['Rogers'])
输出将是:
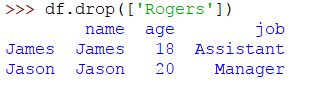
您还可以删除一系列行:
>>> df.drop(df.index[[0, 1]])
这将删除从索引0到1的行以及仅剩下一行,因为我们的DataFrame由3行组成:

如果要从DataFrame中删除最后一行并且不知道总行数是多少,那么可以使用负索引,如下所示:
-1删除最后一行。同样-2将删除最后2行,依此类推。
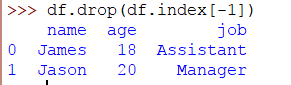
总结一列
您可以使用sum() DataFrame 的 方法对列项进行求和。
假设我们有以下DataFrame:
>> > frame_data = { 'A':[ 23,12,12 ],'B':[ 18,18,22 ],'C':[ 13,112,13 ]}
>> > DF = 大熊猫。DataFrame(frame_data)
现在总结A列的项目,使用以下代码行:
>>> df['A'].sum()
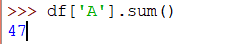
您还可以使用apply() DataFrame 的 方法并传入NumPy的sum方法来对值进行求和。
计算唯一值
要计算列中的唯一值,可以使用nunique() DataFrame 的 方法。
假设我们有如下的DataFrame:
>> > frame_data = { 'A':[ 23,12,12 ],'B':[ 18,18,22 ],'C':[ 13,112,13 ]}
>> > DF = 大熊猫。DataFrame(frame_data)
要计算A列中的唯一值:
>>> df['A'].nunique()

如您所见,A列只有2个唯一值23和12,另外12个是重复,这就是为什么我们在输出中有2个。
如果要计算列中的所有值,可以使用以下 count() 方法:
>>> df['A'].count()
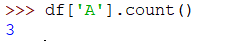
子集行
要选择DataFrame的子集,可以使用方括号。
例如,我们有一个包含一些整数的DataFrame。我们可以像这样选择或分配一行:
df.[start:count]
起点将包含在子集中,但不包括停止点。例如,要从第一行开始选择3行,您将编写:
>>> df[0:3]
输出将是:
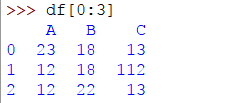
该代码表示从第一行开始,该行为0并选择3行。
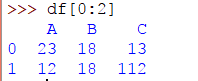
同样,要选择前两行,您将编写:
>>> df[0:2]
要选择或子集最后一行,请使用否定索引:
>>> df[-1:]
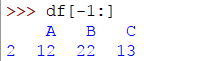
写入Excel
要将DataFrame写入Excel工作表,我们可以使用该 to_excel() 方法。
要写入Excel工作表,您必须打开工作表并打开Excel工作表,我们必须导入openpyxl模块。
使用pip安装openpyxl:
pip install openpyxl
请考虑以下示例:
>> > 进口 openpyxl
>> > frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ]}
>> > DF = 大熊猫。DataFrame(frame_data)
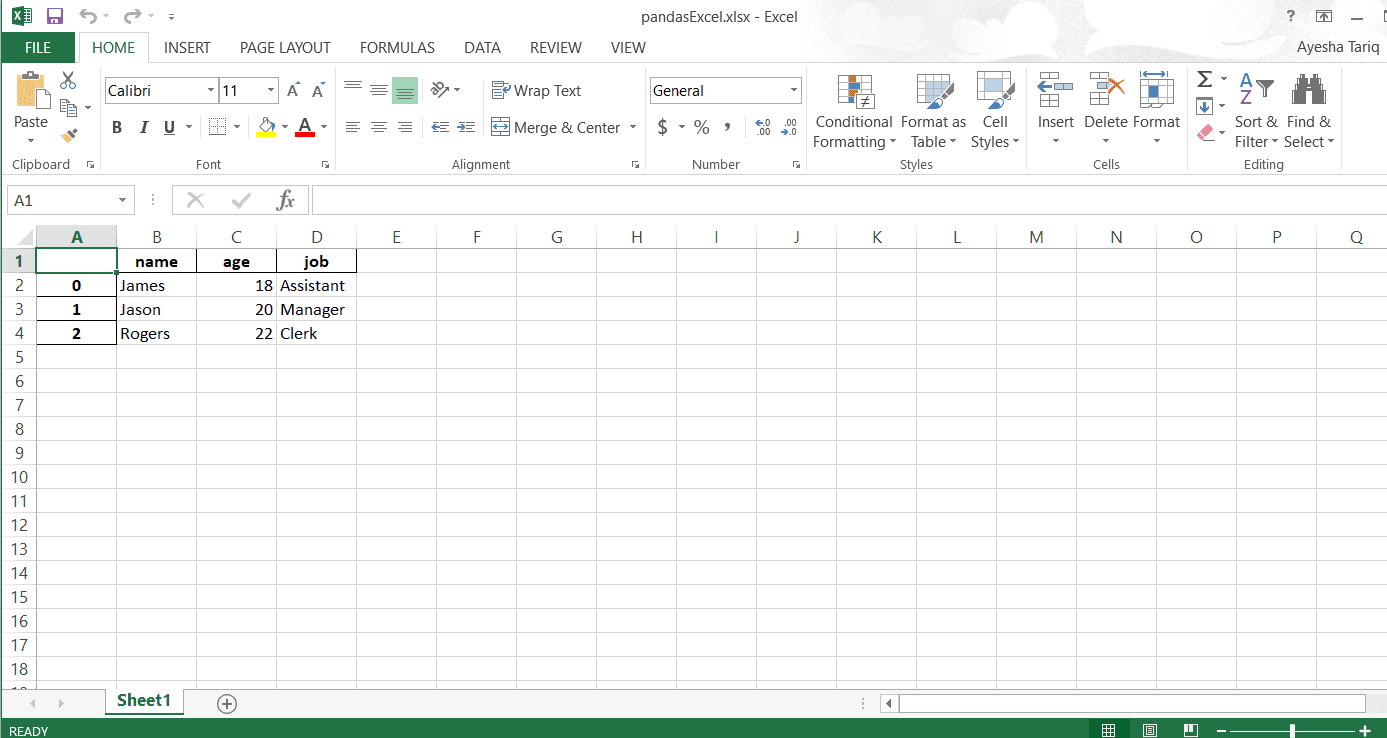
>> > DF。to_excel(“pandasExcel.xlsx”,“Sheet1”)
Excel文件如下所示:
写入CSV
同样,要将DataFrame写入CSV,您可以使用to_csv() 以下代码行中的 方法:
>>> df.to_csv("pandasCSV.csv")
输出文件如下所示:
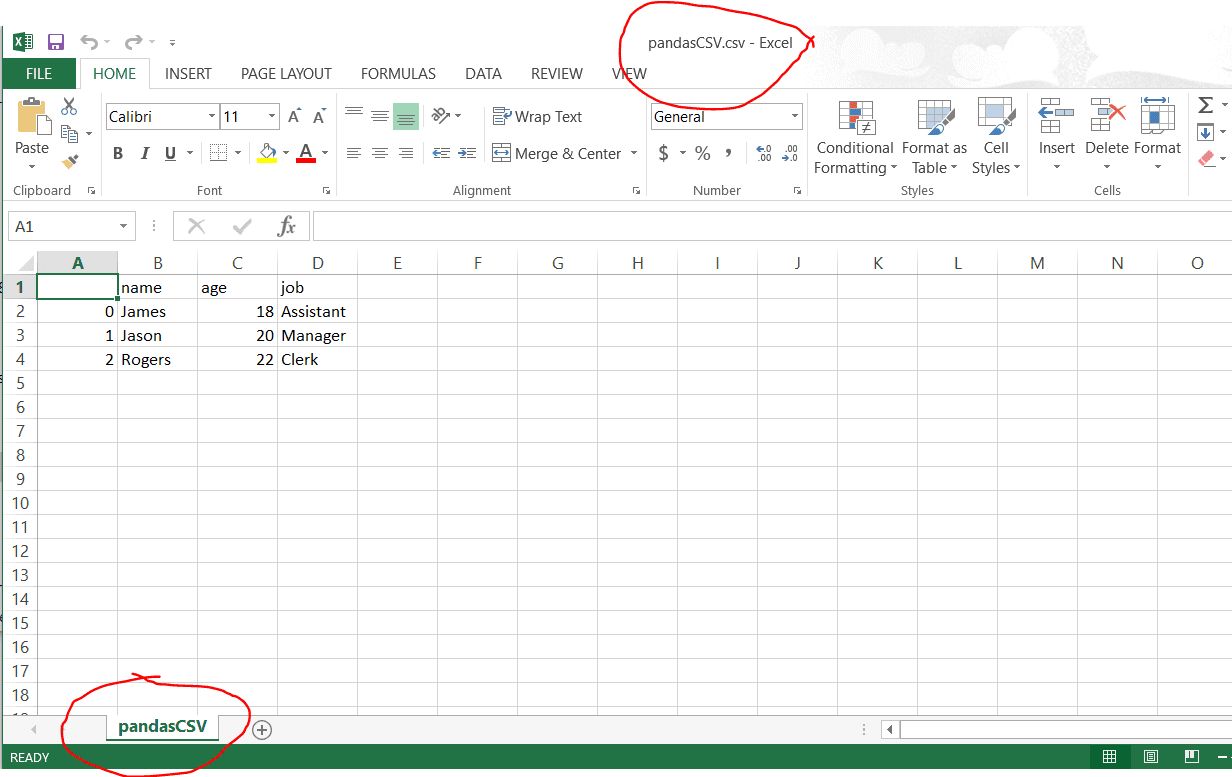
写入SQL
要将数据写入SQL,我们可以使用该 to_sql() 方法。
请考虑以下示例:
import sqlite3
进口 大熊猫
con = sqlite3。connect('mydatabase.db')
frame_data = { '名':'詹姆斯','贾森','罗杰斯' ],'年龄':18,20,22 ],'工作':'助理','经理','职员' ] }
df = 熊猫。DataFrame(frame_data)
df。to_sql('users',con)
在此代码中,我们创建了与SQLite3数据库的连接。然后我们创建了一个包含三行三列的DataFrame。
最后,我们使用to_sql 了DataFrame(df)的 方法,并传递了数据将与连接对象一起存储的表的名称。
SQL数据库将如下所示:
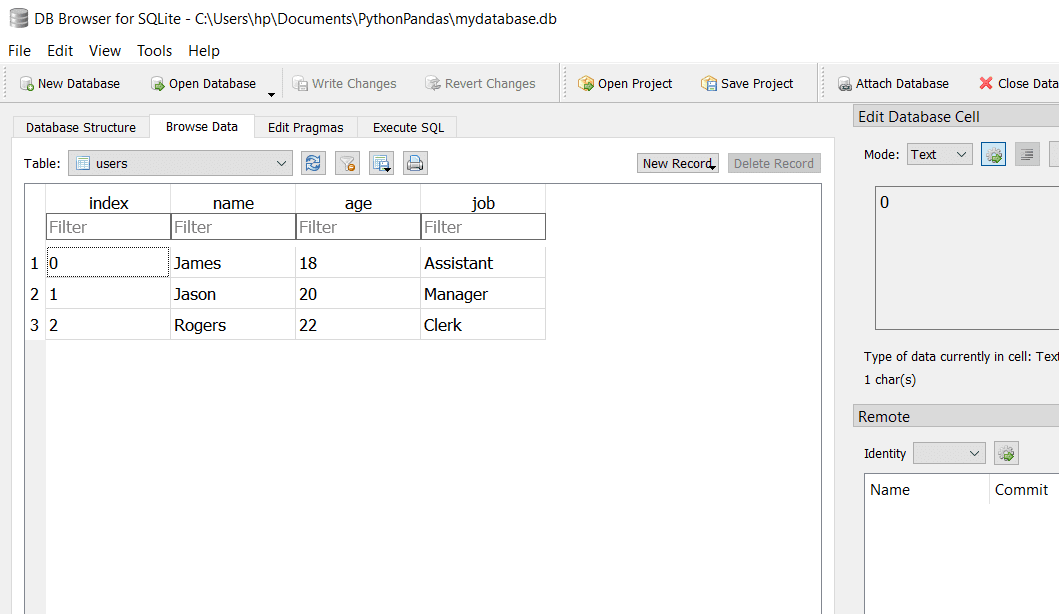
写信给JSON
您可以使用to_json() DataFrame 的 方法写入JSON文件。
这在以下示例中进行了演示:
>>> df.to_json("myJson.json")
在这行代码中,JSON文件的名称作为参数传递。DataFrame将存储在JSON文件中。该文件将包含以下内容:
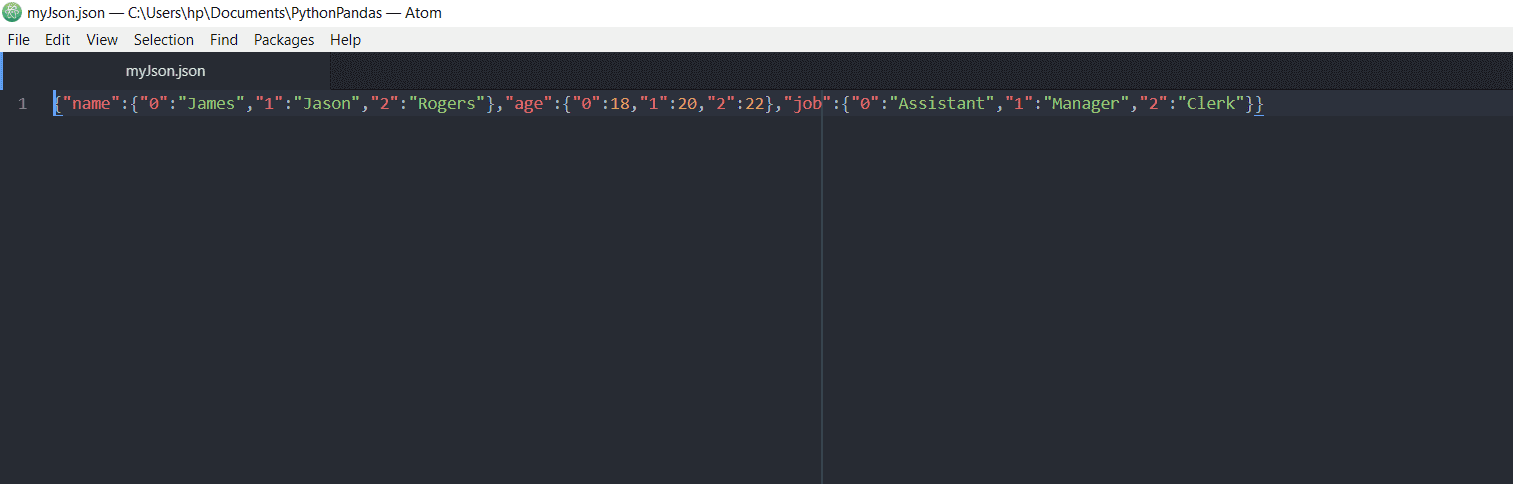
写入HTML文件
您可以使用to_html() DataFrame 的 方法创建包含DataFrame内容的HTML文件。
请考虑以下示例:
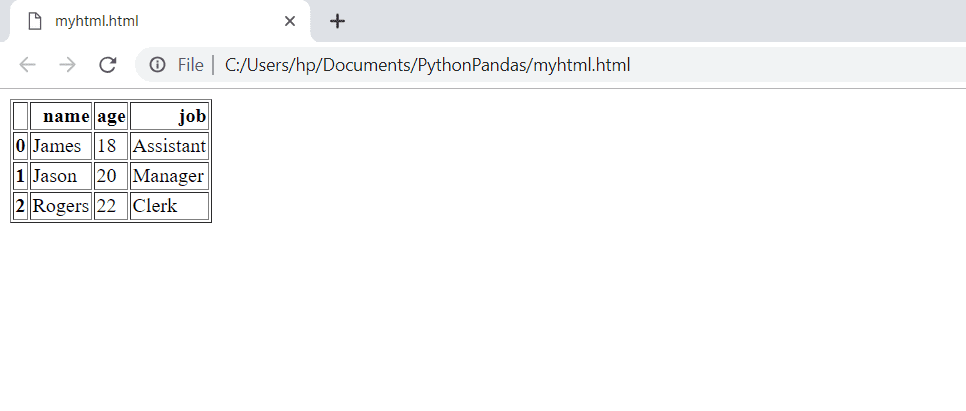
>>> df.to_html("myhtml.html")
结果文件将包含以下内容:
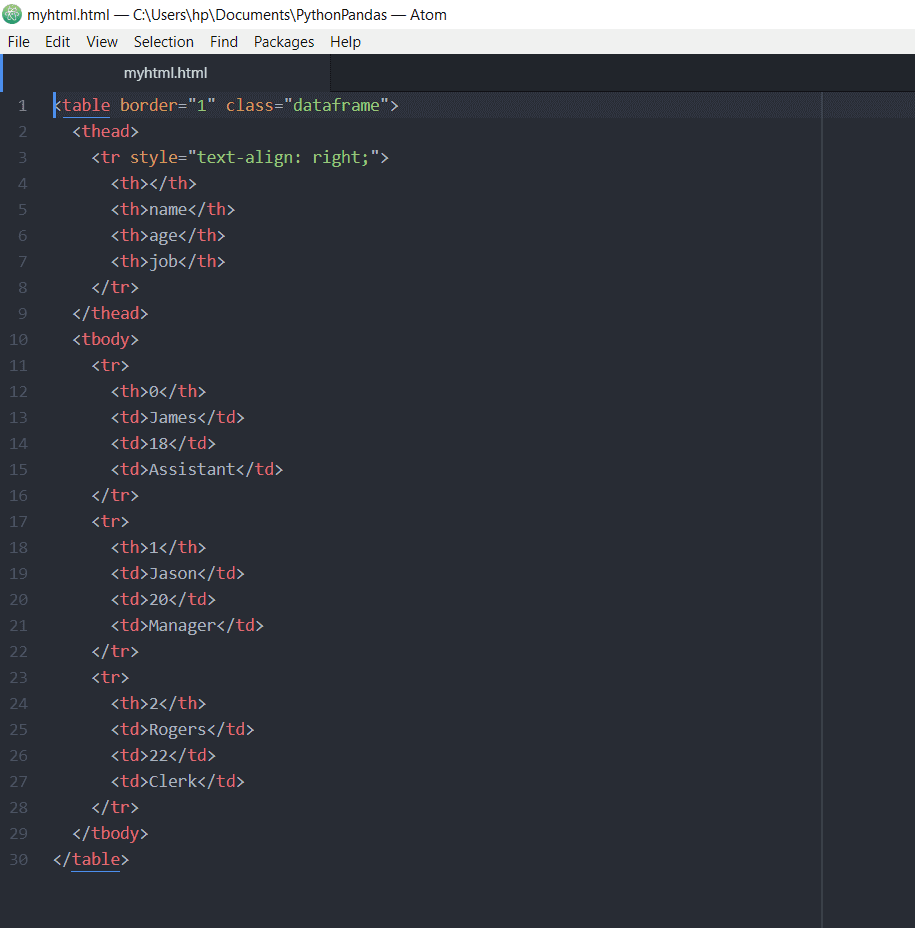
在浏览器中打开HTML文件时,它将如下所示:
使用大熊猫非常容易。这就像使用Excel工作表一样!Pandas DataFrame也是一个非常灵活的库。
我希望你发现这个教程很有用。继续回来。
转载于:https://blog.51cto.com/14009535/2383294















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









