







模型与代码的反复修改会导致最终系统质量的下降
所以需要:
优化类模型
将关联映射到各个集合上
将操作和契约映射到各种异常上
将类模型映射到存储模式上
例子:指环王的出版过程,因为内容多模块多反复修改和更正最后导致整体出版质量不行
映射
转换:局部的-->发生在对象设计和活动实现的期间;
转换有一些行为:
优化:提高速度和有效性
实现关联:将关联或关联集映射成代码
契约:对应代码中的异常,转换为违反契约时的操作
将模型映射到某一存储模式如数据库
映射的概念
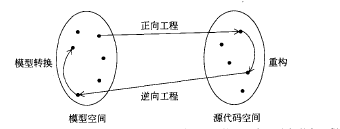
四种转换类型:
1. 在对象模型上的模型转换操作,如将某一简单属性转化到类
模型转换:作用于某一个模型上,产生另一个模型。对象模型转换的目的是简化或优化原始模型,使该模型与规格说明书中的需求一致。
2. 重构,对源代码操作进行转换,仅仅改进系统的某一方面而不改变他的功能。
重构是对源代码的转换,在不影响系统行为的前提下提高源代码的可读性和可修改性。重构可在一些列细化步骤层面下进行,且每一步包含着测试。
3. 正向工程产生于对象模型对应的源代码模板
正项工程应用于对象元素集合上,并且生成一组对应的源代码语句集合。目的是保持对象设计模型与代码间的高度一致并减少在时间期间引入的错误书,从而减少了实现尚需做的努力。
4. 逆向工程产生于源代码对应的模型
逆向工程应用于源代码元素集合,并产生模型元素集合,用于为显存系统重新构建模型,因为该模型已经对失火因为该模型从未构造过。
类型转换的原则:
每个转换对应一个单一判定准则,否则很可能会向源代码中引入错误。
每个转换必须是局部的,也就是说每次只应该改变少量的方法或者类。
每一个转换必须与其他更改活动相隔离。
每个转换之后必须进行确认。
映射活动:
优化对象设计模型
在这一节中我们将学习到四个简单但是通用的有优化方法;进行优化时,开发者应该在效率和清晰性之间找到平衡。
优化访问路径(增加关联)
关联的重复遍历:添加必须的关联,比如查询对象和被查询对象之间必须有一个直接连接,对整个系统进行动态分析,只添加关乎性能瓶颈的关联。
简化关联多的一端:可以通过限制关联或者对关联内容进行排序来做到
减少过度建模:对于一些类值调用到一两个接口的应该考虑将这些类重新整合封装。
分解对象为属性
经过一些优化,某些类只剩下很少的属性和行为,如果这些类仅与其他的一个类关联,则可以将类压缩为属性。
延迟高成本计算
用一个接口或者他低计算成本的方法来暂时代替原来的计算除非原来的计算确是必需。
缓存高成本计算结果
如果一个方法被调用多次而计算结果不总是发生变化是可以用一个私有属性来进行高速缓存。
将关系映射到集合上:
UML中有这个表示两个或多个对象之间的双向链表集合的概念,但程序设计语言里并没有,它们只有引用和集合。引用是发生在两个对象间的单项关系,我们可以借用它来实现关联,并考虑关联的重数和关联的方向。
一对一的单向关联
一对一的双向关联
一对多的关联
多对多的关联
受限关联:
受限关联解决的是与关联多的那一端相连的类的一个属性
使用映射对象Map来表示受限端,将受限属性作为一个参数进行传递,一访问关联的另一端。
关联类:使用一个关联类来保存关联的属性和操作。
一旦关联已经映射称为字段或者方法,类的公共接口就相应完成了。
这些关联的本质上也只是类中属性和方法的声明与实现。
将契约映射到异常
在java中我们使用throw关键字来抛出异常。
异常对象提供一个存储异常信息的空间,异常信息通常包括一个错误信息和一个使用throw调用栈描述的反向追踪信息。
throw展开调用栈直到找到相匹配的catch语句
一个简单的映射将独立地处理契约中的每个操作,并向方法实体中增加代码
检测前置条件
检测后置条件(只报第一个错误)
检测不变量,当作后置条件
处理继承:前置条件和后置条件的检测代码应该封装在子类中可以调用的特定方法中。
然而上述方案并不是很科学,因为:
编码工作量大
增加出错机会
代码混乱
性能缺陷
因此我们采取启发式方案:
忽略后置条件和不变量的检测
着重考虑子系统的接口,只考虑public的方法
复用约束检测代码
将对象模型映射到持久存储模式
面向对象程序设计语言通常不提供存储持久对象的有效方式。
我们需要将持久对象映射到一个可以通过系统设计期间决定的持久数据管理系统进行存储的数据结构上
对象模型中的类和对象数据库中的类是一一对应的
模式:模式是数据的描述,即数据的元模型
数据库模式描述可存储于数据库中的有效数据记录集中
关系数据库以表的形式存储持久数据
表由列组成,每个列表示一个属性
表的主关键字是唯一标识表中数据记录的属性集合

可以作为关键字的属性集合称为候选关键字(s)
外关键字是另一个表的关键字的引用

映射类和属性:将持久对象映射到关系模式是,我们首先关注的是类及其属性
将类映射到一个同名的表
每个属性对应表里面的一列
需要对数据库的列选择一个数据类型
着重讨论关键字:
两种选择:(因为关键字要求是每个对象都唯一)
表示出唯一标识对象的类的属性集合(即找出一个符合要求的属性)
增加一个我们生成的唯一标识符属性(创建一个符合要求的属性)
映射关联:
隐含映射:
重数为一的关联可以用外关键字实现。
一对多关联:往表中增加一个外关键字,该表表示是与关联中“多”的一端相连的类。

独立数据表:使用一个独立包含两列的表来实现多对多的关联,这个表包含对应两个关联类的外关键词。称为关联表。
关联表的每一行对应两个实体之间的一个链接
每一列都是一个类的标识属性
使用一个表来表示所有的关联将产生一个可以修改的数据库模式。不过这会增加模式中表的数量和遍历关联的总时间/
我们需要在应用上下文中评估这个这种方案,检查关联的重数是否会改变或者响应时间是否是关键的设计目标。
映射继承关系
关系数据库不直接支持集成,但将某一继承关系映射到一个数据库模式中主要有两种方案:
与一对一关联类似,每个类通过一个表里来表示用外关键词来链接子类和超类
超类属性被推至子类中,本质上是复制与子类相对应的表的列。
垂直映射
将超类和子类映射到独立的表
超类表有一个额外的列表示与数据记录相对应的子类。
所有表共享同一个关键字,即对象标识符。
超类和子类表中的关键字值相同的数据记录来源于同一个对象

水平映射:
将超类属性向下推入子类中,删除超类表。
每个子类复制了超类的列

这两种映射关系各有优劣,前者方便修改但是增加响应时间,后者反之,综合考虑进行取舍。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









