






转载请注明出处:@http://blog.csdn.net/gamer_gyt,Thinkagmer 撰写
私人博客:http://blog.cyanscikit.top (尚在开发中)
Github:https://github.com/thinkgamer
=============================================================================
写在前边的话
动手准备写这篇博客,想的挺多,但是到了笔下,却很难说的一清二楚
上一篇博客中我介绍了如何部署Hadoop HA(High Availability),在这篇博客中我们就来看一下Hadoop容错机制的演变之路
一:1.x和2.x的架构对比
具体可参考之前的一篇博文:Hadoop1.X 与 Hadoop2.X比较
二:hadoop 1.X的单点故障
1)JobTracker 是 Map-reduce 的集中处理点,存在单点故障;
2)JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker 失效的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限;
在1.x版本中给出的解决方案主要有以下几种
1:Secondary NameNode
需要声明的是SNN不是NameNode的备份。他的作用是定期合并fsimage和edits文件,并推送给NameNode,以缩短集群启动的时间,当NN失效的时候,SNN并无法立刻提供服务,甚至无法保证数据的完整性,如果NN数据丢失,在上一次合并后的文件系统的改动就会丢失。
SNN的作用在2.x版本中可以被两个节点替换CheckpointNode和BackuoNode。
CheckpointNode可以理解为与SNN的作用一致,BackupNode是NN的完全备份
配置文件对应的core-site.xml
配置项为:
fs.checkpoint.period
fs.checkpoint.size
fs.checkpoint.dir
fs.checkpoint.edits.dirSNN定期合并流程,如下所示
[root@master1 current]# cat VERSION
#Tue Aug 30 05:46:05 CST 2016
namespaceID=1476026471
clusterID=CID-8ec4991f-2f2e-4579-be1a-cfa862c87ba1
cTime=0
storageType=JOURNAL_NODE
layoutVersion=-63layoutVersion 是一个负整数,保存了HDFS的持续化在硬盘上的数据
namespaceID 是文件系统的唯一标识符,在文件系统初次格式化时生成
cTime 此处为0
storageType 表示此文件夹中保存的是元数据节点的数据结构
NN进程挂掉之后,怎么进行数据恢复?
(1):删除SNN存放那个数据目录下in_use.lock文件
(2):执行恢复命令 hadoop-daemon.sh -importCheckpoint
(3):启动NN hadoop-daemon.sh start namenode
(4):进行校验检查根目录是否健康 hadoop fsck /
(5):查看数据 hadoop fs -lsr /
至此NN元数据恢复成功,但是仍然存在数据丢失的情况
2:CheckpointNode
作用和SNN是一样的,启动命令为 hadoop namenode -checkpoint
配置文件:core-site.xml
fs.checkpoint.period
fs.checkpoint.size
fs.checkpoint.dir
fs.checkpoint.edits.dir3:BackupNode
提供一个真正意义上的备用节点,在内存中维护一份从NN同步过来的fsimage,同时还把从MM接受edits文件的日志流,并把它们持久化硬盘。
BackupNode在内存中维护与NN一样的Matadata数据,启动命令为hdfs namenode -backup
配置文件:hdfs-site.xml
dfs.backup.address
dfs.backup.http.address 三:Hadoop HA(高可用性)
这里需要说明的是SNN在hadoop2.x依然存在,只不过已经有了HA,对其进行了工作的替代,所有就不必再配置了
1:基本原理
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如 active namenode挂了)。而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
2:NFS(Network File System)
NFS作为active namenode和standby namenode之间数据共享的存储。active namenode会把最近的edits文件写到NFS,而standby namenode从NFS中把数据读过来。这个方式的缺点是,如果active namenode或者standby namenode有一个和NFS之间网络有问题,则会造成他们之前数据的同步出问题。 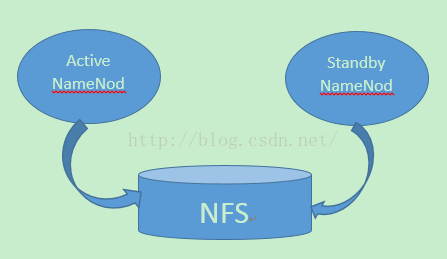
3:QJM(QuorumJournal Manager)
QJM的方式可以解决上述NFS容错机制不足的问题。active namenode和standby namenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。active namenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standby namenode就可以从journalnode上读取了。可以看到,QJM方式有容错的机制,可以容忍n个journalnode的失败。

4:主备节点切换
active namenode和standby namenode可以随时切换。当active namenode挂掉后,也可以把standby namenode切换成active状态,成为active namenode。可以人工切换和自动切换。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active namenode成为新的active namenode,HDFS继续正常工作。
主备节点的自动切换需要配置zookeeper。active namenode和standby namenode把他们的状态实时记录到zookeeper中,zookeeper监视他们的状态变化。当zookeeper发现active namenode挂掉后,会自动把standby namenode切换成active namenode。

四:ResourceManager HA
两个RM启动的时候都是standy,进程启动以后状态未被加载,转换为active以后才会加载相应的状态并启动服务,RM的转换可以通过Zookeeper来进行监控和切换
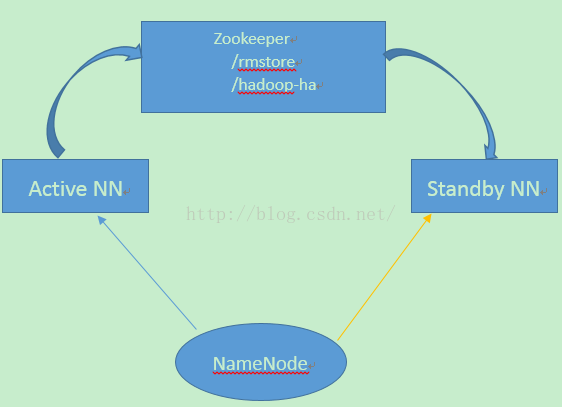
具体的流程如下:
(1)RM的作业信息存储在ZK的/rmstore下,Active RM向这个目录写APP 的信息
(2)RM启动的时候会通过向ZK的/Hadoop-ha目录下写一个Lock文件,写成功则成为Active,否则为Standy,Standy RM会一直监控Lock文件是否存在,如果不存在,则会试图去创建,则争取成为Active RM
(3)当Active RM 挂掉,另外一个StandyRM 成功转换为Active RM后,会从/rmstore读取相应的作业信息,重新构建作业的内存信息,然后启动内部服务,开始接受NM的心跳,构建集群资源信息,并接收客户端提交作业的请求等
 、
、RM的HA 配置为:
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value> <!-- 开启RM高可用 -->
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value> <!--启动自动故障转移,默认为false-->
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value> <!--启用一个内嵌的故障转移,与ZKRMStateStore一起使用。-->
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value> <!-- 指定RM的cluster id -->
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value> <!-- 指定RM的名字 -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value> <!-- 分别指定RM的地址 -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value> <!-- 分别指定RM的地址 -->
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node, we need this configuration</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,slaver1:2181</value> <!-- 指定zk集群地址 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>五:HDFS Federation(HDFS联邦)
参考之前的博客:HDFS Federation(HDFS 联邦)(Hadoop2.3)















 2577
2577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









