







Region 概念
Region是表获取和分布的基本元素,由每个列族的一个Store组成。对象层级图如下:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
Region 大小
Region的大小是一个棘手的问题,需要考量如下几个因素。
Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上,但并不是存储的最小单元。
Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。
HBase通过将region切分在许多机器上实现分布式。也就是说,你如果有16GB的数据,只分了2个region, 你却有20台机器,有18台就浪费了。
region数目太多就会造成性能下降,现在比以前好多了。但是对于同样大小的数据,700个region比3000个要好。
region数目太少就会妨碍可扩展性,降低并行能力。有的时候导致压力不够分散。这就是为什么,你向一个10节点的HBase集群导入200MB的数据,大部分的节点是idle的。
RegionServer中1个region和10个region索引需要的内存量没有太多的差别。
HBase split概述
HBasesplit是HBase根据一定的触发条件和一定的分裂策略将HBase的一个region进行分裂成两个子region并对父region进行清除处理的过程。Region是HBase中一个非常核心的组织单元,所有的region组成了整个HBase集群,如下面的HBase的体系结构所示:
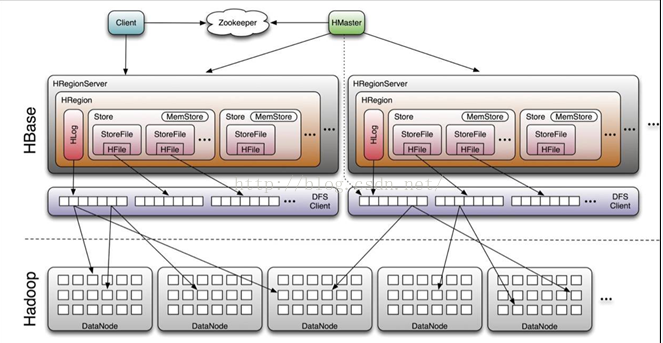
因此在HBase的整体region分裂过程中达到一生二,二生三,三生万物的效果。
HBase为啥要split
在HBase中,split其实是进行sharding的一种技术手段,通过HBase的split条件和split策略,将region进行合理的split,再通过HBase的balance策略,将分裂的region负载均衡到各个regionserver上,最大化的发挥分布式系统的优点。HBase这种自动的sharding技术比传统的数据库sharding要省事的多,减轻了维护的成本,但是这样也会给HBase带来额外的IO开销,因此在很多系统中如果能很好的预计rowkey的分布和数据增长情况,可以通过预先分区,事先将region分配好,再将HBase的自动分区禁掉。
触发条件:
HBase中共有3种情况会触发HBase的split,分别是:
1.当memstore flush操作后,HRegion写入新的HFile,有可能产生较大的HFile,HBase就会调用CompactSplitThread.requestSplit判断是否需要split操作。
2.HStore刚刚进行完compact操作后有可能产生较大的HFile,当满足HBase的某一分裂策略后就会进行split操作。
3.当HBaseAdmin手动发起split时,也会触发split操作。
split策略
1.采用ConstantSizeRegionSplitPolicy策略,即storefile固定大小策略:
在0.94版本之前ConstantSizeRegionSplitPolicy 是默认和唯一的split策略。当某个storefile(对应一个columnfamily)的大小大于配置值 ‘hbase.hregion.max.filesize’的时候(默认DEFAULT_MAX_FILE_SIZE = 10 * 1024 * 1024 *1024L=10G)region就会自动分裂:
2.采用IncreasingToUpperBoundRegionSplitPolicy策略,即根据region数来决定:
0.94.0(包含)之后,默认采用此策略,即当同一table在同一regionserver上的region数量在[0,100)之间时按照如下的计算公式算,否则按照上一策略计算:
Min (R^3* "hbase.hregion.memstore.flush.size"*2, "hbase.hregion.max.filesize")
R为同一个table中在同一个regionserver中region的个数,
hbase.hregion.memstore.flush.size默认为128M,
hbase.hregion.max.filesize默认为10G。
3.KeyPrefixRegionSplitPolicy策略
即根据rowkey指定长度的前缀来划分region:
即保证相同的前缀的row保存在同一个region中。指定rowkey前缀位数划分region,通过读取 KeyPrefixRegionSplitPolicy.prefix_length 属性,该属性为数字类型,表示前缀长度,在进行split时,按此长度对splitPoint进行截取。此种策略比较适合固定前缀的rowkey。当table中没有设置该属性,指定此策略效果等同与使用IncreasingToUpperBoundRegionSplitPolicy。
4.DelimitedKeyPrefixRegionSplitPolicy策略:
保证以分隔符前面的前缀为splitPoint,保证相同RowKey前缀的数据在一个Region中。
HBase split的整体流程
Region的分割操作是不可见的,因为Master不会参与其中。RegionServer拆分region的步骤是,先将该region下线,然后拆分,将其子region加入到META元信息中,再将他们加入到原本的RegionServer中,最后汇报Master。
执行split的线程是CompactSplitThread。
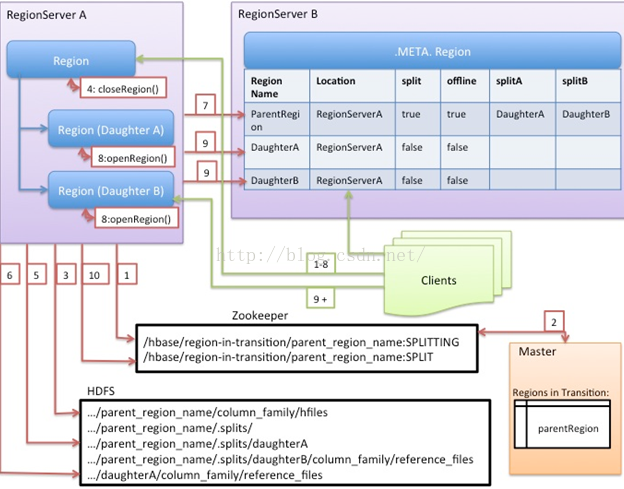
1、RegionServer决定本地的region分裂,并准备分裂工作。第一步是,在zookeeper的/hbase/region-in-reansition/region-name下创建一个znode,并设为SPLITTING状态。
2、Master通过父region-in-transition znode的watcher监测到刚刚创建的znode。
3、RegionServer在HDFS中父region的目录下创建名为“.split”的子目录。
4、RegionServer关闭父region,并强制刷新缓存内的数据,之后在本地数据结构中将标识为下线状态。此时来自Client的对父region的请求会抛出NotServingRegionException ,Client将重新尝试向其他的region发送请求。
5、RegionServer在.split目录下为子regionA和B创建目录和相关的数据结构。然后RegionServer分割store文件,这种分割是指,为父region的每个store文件创建两个Reference文件。这些Reference文件将指向父region中的文件。
6、RegionServer在HDFS中创建实际的region目录,并移动每个子region的Reference文件。
7、RegionServer向.META.表发送Put请求,并在.META.中将父region改为下线状态,添加子region的信息。此时表中并单独存储没有子region信息的条目。Client扫描.META.时回看到父region为分裂状态,但直到子region信息出现在表中,Client才直到他们的存在。如果Put请求成功,那么父region将被有效地分割。如果在这条RPC成功之前RegionServer死掉了,那么Master和打开region的下一个RegionServer会清理关于该region分裂的脏状态。在.META.更新之后,region的分裂将被Master回滚到之前的状态。
8、RegionServer打开子region,并行地接受写请求。
9、RegionServer将子region A和B的相关信息写入.META.。此后,Client便可以扫描到新的region,并且可以向其发送请求。Client会在本地缓存.META.的条目,但当她们向RegionServer或.META.发送请求时,这些缓存便无效了,他们竟重新学习.META.中新region的信息。
10、RegionServer将zookeeper中的znode /hbase/region-in-transition/region-name更改为SPLIT状态,以便Master可以监测到。如果子Region被选中了,Balancer可以自由地将子region分派到其他RegionServer上。
11、分裂之后,元数据和HDFS中依然包含着指向父region的Reference文件。这些Reference文件将在子region发生紧缩操作重写数据文件时被删除掉。Master的垃圾回收工会周期性地检测是否还有指向父region的Reference,如果没有,将删除父region。
实际例子
做个实际的例子分析一下:
我们在测试环境上对某张表(初始化时只有一个region),通过3次split,变成了8个region。下图是具体的每个parent region split成两个daughter region的过程。这里只缩写每个region的后四位编号:
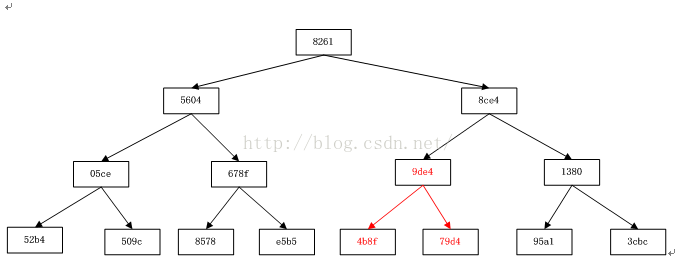
最终分裂完之后在hdfs上的region是这样的:

注意事项
1.不能对元数据表进行split;
2.不能对正在recovery的region做split;
3.如果某个region存在引用文件的不能split;
4.在split的过程执行到将parent region offline之后,daughter region还未创建之前,客户端如果此刻正访问的是parent region,在客户端没有更新缓存的情况下,会报NotServingRegionException异常,因此客户端需要做好重试机制;
5.在split的整个过程中有个关键的点,即PONR,即point of no return,无法回退的点,发生在将.META.表中的parent region更新为offline之前,如果进入PONR之后,由于种种原因更新.META.失败,需要重启所在的regionserver进行回滚。















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









