







最近在入门机器学习,本文作为入门阶段的 "Hello World",旨在学习一些Tensorflow的API和机器学习概念。
步骤
- 采集验证码图片
- 处理图片:灰度、去噪、分割
- 分类图片,准备训练数据:将0-9数字图片放入对应文件夹,转化成数据
- 编写训练模型
- 调用模型,形成识别系统
采集验证码图片
随便找一个需要输入图像验证码的网页,最好先简单一点的只有数字的,并且人眼识别也比较容易的。
这步比较简单,关键是去网页上识别验证码接口url,然后按照一些网上教程写个简单的Python程序抓取那些图片。python实现简单爬虫功能
处理图片
电脑装不上PIL,所以只能使用Java去处理,言语只是工具,注重方法。对图片进行灰度、去噪、分割处理。
灰度化
灰度处理是指将彩色图片转化成只有黑白灰色。
每个像素点有Red、Green、Blue三种颜色组成,每个分量用数字0-255表示(十六进制:0x00 - 0xff),当三个分量(RGB)一样时表现出来就是灰度色(白色RGB(255, 255, 255), 黑色RGB(0, 0, 0))。
所以,灰度化是将三分量转化成一样数值的过程
公式如下:
int gray = (int) (0.3 * r + 0.59 * g + 0.11 * b);再使用二值法将图片色彩转化成非黑即白,可以过滤一些感染的噪音,因为人眼在识别验证码时也会自动过滤掉一些颜色比较淡的点或者色块图形。
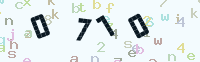
如上图,我们只会关注中间颜色比较深的数字而一些背景淡色小字会被过滤掉。
gray = gray < 127 ? 0 : 255;去噪处理
这里处理比较简陋,就是遍历所有图片中的像素点,如果这个点附近N个点(相邻的一共有8个点)颜色是白色,那么我们判定该是噪音点,将其颜色也设置为白色,这里我设置 N=8。
结合上面二值化处理后效果如下:

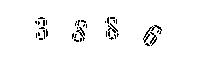
分割图片
比较恶的一步,因为数字旋转和字体大小不一所以宽度不定,而且还有重叠。
处理步骤:
- 扫描出每个数字左右边界,即找到最左最右的点
- 根据这个边界进行横向裁剪
- 如果发现最后裁剪出来不是4个数字而是3个或者更少,查看是否存在某个裁剪块的宽度比一般的要大,然后进行平均分割
- 对每个裁剪下来的图片再进行纵向裁剪,将上下多余的空白区裁剪掉
效果如下:
![]()
分类图片,准备训练数据
创建10个文件夹,命名为0、1、2.... 9,将裁剪后数字图片分类到那些文件夹中。
将图片转化为向量数据,形如:
0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,....如果规定图片大小为36*36,那么该向量长度为1296。(数字表示该点的颜色,0为白色,1为黑色)
然后再需要一个标签数据
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0] // 表示0
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0] // 表示5一条数据有10位,每个位置分别表示0到9
编写训练模型
刚开始只使用SVM做多分类,感觉有点复杂毕竟需要训练那么多组模型参数,所以放弃。后来单纯使用softmax训练,训练数据大概在1500左右,正确率在55%左右,可能需要更多的训练数据效果会好点,最后参照MNIST使用CNN去训练,同样的训练数据正确率达到80%左右,如果训练数据达到10000以上的话估计会更高(MNIST识别手写准确率在98%左右)。
CNN
TF提供2维卷积函数
tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')x是输入;W是卷积参数如[5,5,1,32],5*5是卷积核大小;第三个参数表示channel,这里因为是灰度所以是1,彩色的话是3;第四个参数表示卷积核的数量,即提取多少特征;strides是移动步长都是1表示遍历每个点;padding参数指定边界处理方式,“SAME”表示输入输出保持一样。
除此之外,还需要池化函数(降采样,将2x2降为1x1提取最显著的特征),这里使用最大池化max_pooling
tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')x是输入;ksize表示使用2x2池化,即将2x2的色块降为1x1,最大池化会保留灰度值最高的那个像素点;因为需要整体缩小图片所以这里strides在横向纵向的步长都为2。
构建处理层
这里还加入了dropout防止过拟合。
def weight_variable(shape, name):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=name)
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
#define weights & biases
weights = {
"h1": weight_variable([5, 5, 1, 32], "w_h1"),
"h2": weight_variable([5, 5, 32, 64], "w_h2"),
"f1": weight_variable([9*9*64, 1024], "w_f1"),
"f2": weight_variable([1024, 10], "w_f2")
}
biases = {
"h1": bias_variable([32], "b_h1"),
"h2": bias_variable([64], "b_h2"),
"f1": bias_variable([1024], "b_f1"),
"f2": bias_variable([10], "b_f2")
}
x_image = tf.reshape(xs, [-1, 36, 36, 1]) # [n_samples, 28,28,1]
## conv1 layer ##
W_conv1 = weights["h1"] # patch 5x5, in size 1, out size 32
b_conv1 = biases["h1"]
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 36x36x32
h_pool1 = max_pool_2x2(h_conv1) # output size 18x18x32
## conv2 layer ##
W_conv2 = weights["h2"] # patch 5x5, in size 32, out size 64
b_conv2 = biases["h2"]
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 18x18x64
h_pool2 = max_pool_2x2(h_conv2) # output size 9x9x64
## fc1 layer ##
W_fc1 = weights["f1"]
b_fc1 = biases["f1"]
# [n_samples, 9, 9, 64] ->> [n_samples, 9*9*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 9*9*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## fc2 layer ##
W_fc2 = weights["f2"]
b_fc2 = biases["f2"]
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)定义Loss和Optimizer
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)使用交叉熵作为Loss函数,优化器使用Adam,这些TF都有提供。
执行训练
for i in range(150):
sess.run(train_step, feed_dict={xs: datas, ys: labels, keep_prob: 0.5})执行150个迭代,这里有个需要优化的地方,datas可以每次选取其中部分训练数据而不是全量的训练,这样速度会快一点。
计算正确率
#y_pre 是每个数据对应各个类别(0-9)的概率如[[0.1,0.2,0.3,0.4...],[0.2,0.1,0.9....]]
y_pre = sess.run(prediction, feed_dict={xs: test_datas, keep_prob: 1})
#tf.argmax返回最大数的索引,再比较预测数据索引和测试数据真实索引
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(test_labels,1))
#将上面比较结果True转为1,False转为0,相加计算平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy)使用测试数据test_datas和测试数据对应的标签test_labels进行检验。
调用模型
上面已经执行训练了,当训练完成时可以保存模型,这样在使用模型时可以直接恢复然后调用,不用重新训练。
保存模型
saver = tf.train.Saver()
save_path = saver.save(sess, "./models/save_net.ckpt")恢复模型
saver = tf.train.Saver()
saver.restore(sess, "./final_models/save_net.ckpt")总结
代码等整理完成后会发布到github上,仓库地址在后续会贴出来。
如有不准确或者任何好的建议都可以提出来,谢谢!















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









