







文章翻译
FlameScope是一个新的开源性能可视化工具,它使用次秒级偏移热图和火焰图来分析周期活动、方差、扰动。我们在Netflix TechBlog上面,发表了技术文章Netflix FlameScope,以及工具的源代码。火焰图很好理解,次秒级偏移热图理解起来要困难些(我最近发明的它)。FlameScope可以该帮助你理解后者。
总而言之,次秒级偏移热图是这样的:x轴是一整秒,y轴是这一秒里的几分之一秒。这每个几分之一秒都被称作一个桶(或者说盒),表示这几分之一秒里,事件数量的聚合。盒子颜色深度表示发生的次数,颜色越深表示次数越多。
下图一个真实的CPU上的次秒级偏移热图样本:
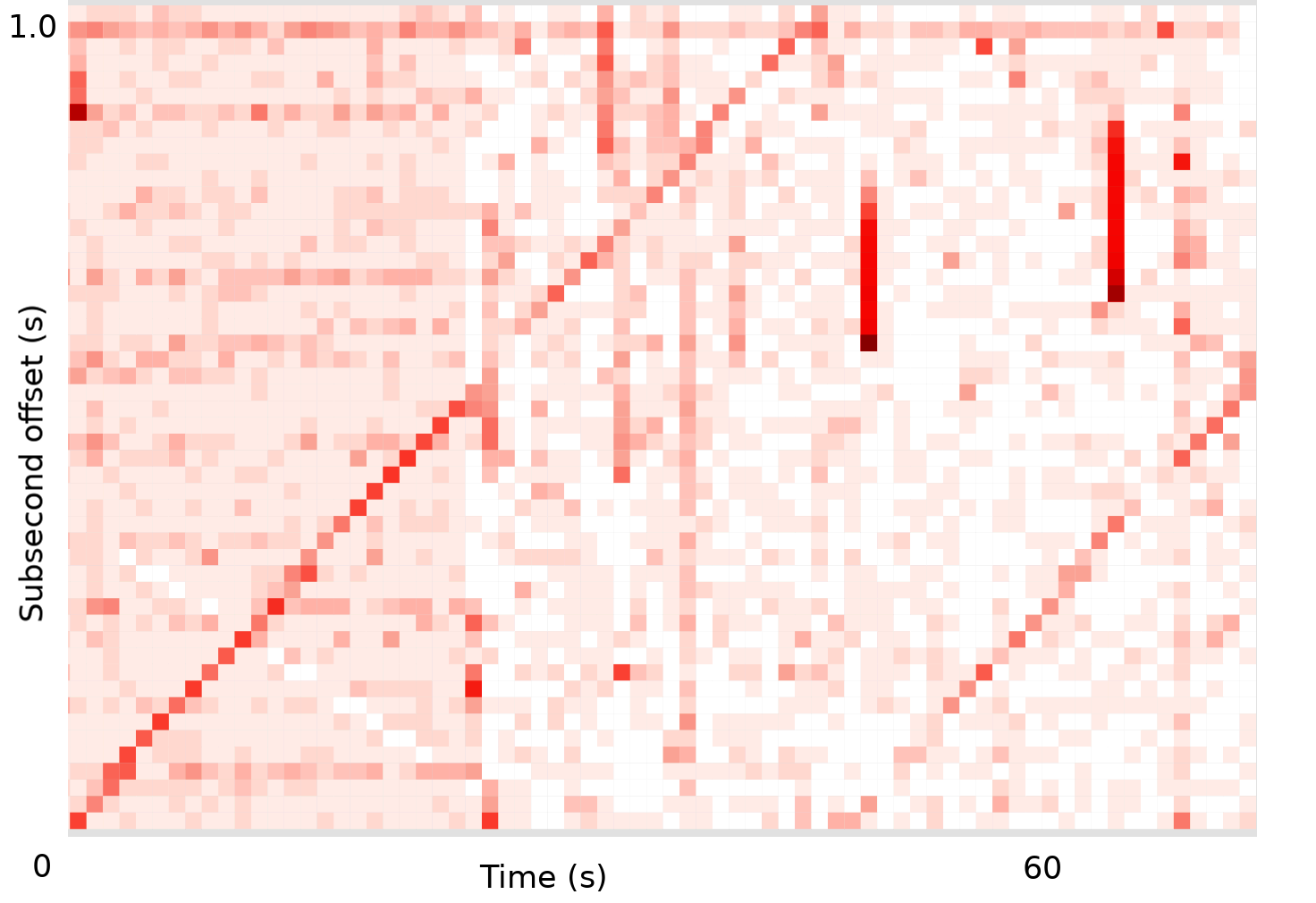
这张图中能分析出什么信息来呢?为了能把各种不同模式区分开来展示,我在这篇文章里先画了一些人工合成的样本。实际使用FlameScope工具时,可以选择你的各个模式,还能生成火焰图,显示对应的代码路径(这里我不展示火焰图)。
周期活动
1 . 一个线程,每秒一次

线程在每秒钟内的同样的偏移里醒来,做几毫秒的工作,然后回到睡眠。
2 . 一个线程,两次每秒

每500ms唤醒一次。既可能是两个线程,也可能是一个线程500ms 唤醒一次。
3 . 两个线程

看起来像两个线程均1s唤醒一次
4 . 一个忙等待线程,每秒一次

这个线程做约20ms的工作,然后睡1s。这是一个常见的模式,导致每秒钟唤醒抵消匍匐前进。
5 . 一个忙等待线程,两次每秒

每500ms唤醒一次。有可能是单线程程序,每秒唤醒两次。
6 . 一个计算较密集的忙等线程

斜率高,每秒做更多的工作,大约是80毫秒。
7 . 一个计算较不密集的忙等线程

斜率低,每秒做的工作较少,可能只有几毫秒。
8 . 一个忙等待线程,每5秒钟唤醒一次

现在5秒唤醒一次。
我们可以根据夹角和唤醒的时间间隔,计算每个唤醒的CPU繁忙时间:
busy_time = (1000 ms / (热图行数 时间长度) tan(夹角)
例如45°夹角的线:
busy_time = (1000 ms / (501)) tan(45) = 20ms
方差
9 . cpu利用率100%

这是CPU完全被用满的样子
10 . cpu利用率50%

真实的工作负载更像是这样,是由短请求、随机到达组成的。
11 . cpu利用率25%

相同的工作负载类型,大小在25%。
12 . cpu利用率5%

相同的工作负载类型,大小在5%。
13 . 负载增加
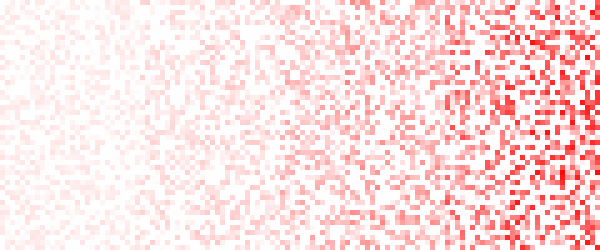
在2分钟的尺度上,负载在变重。
14 . 变化的负荷

每30秒就有5秒的工作负载较重。
扰动
15 . CPU扰动
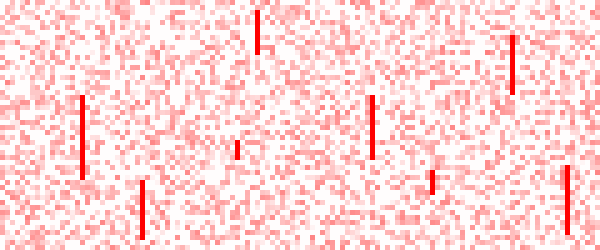
时不时地所有CPU都满载个100ms。(比如垃圾回收)
16 . CPU阻塞

时不时地所有CPU都空载个100ms。(比如等I/O)
17 . 单线程阻塞

时不时地,只有一个CPU没有idle(表现为粉红色长条,而不是白色长条)。(比如全局锁)
最后这个模式很有趣:它发生在一个当前运行的线程持有一把锁,而其它所有线程都阻塞在这把锁上。
那么该线程在做什么呢?点击FlameScope的粉色线,就能看到此时的火焰图。复杂的性能问题立刻变简单。
总结
你能从这张图中分析出什么结论?
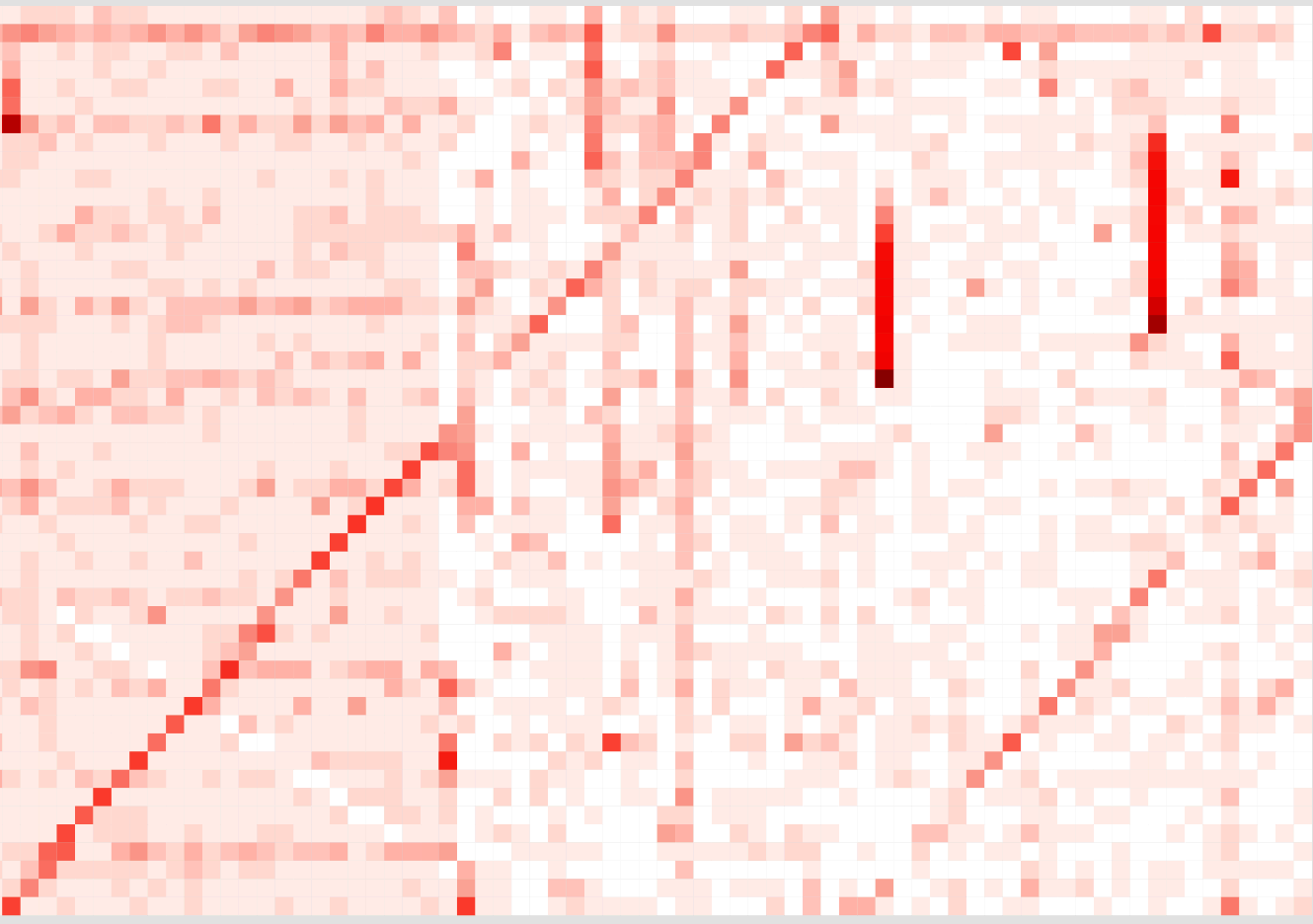
实际使用FlameScope工具时,可以选择你的各个模式,还能生成火焰图,显示对应的代码路径。
我和同事Martin Spier(也是该工具的主开发人员)11月8日在LinkedIn性能meetup上发表演讲。
祝你使用FlameScope愉快,欢迎截图分享你遇到有趣的模式!
Brendan
实践
需要补充的是,作者最新的工作,将强大的Differential Flame Graph也集成到FlameScope中了,现在交互式地在FlameScope上,选择两个测试集以及对应的时间段,对比两个测试组的事件采样。
我在使用FlameScope时,发现并fix了FlameScope的若干bug。也包括Differential Flame Graph跑不起来的一些bug。之后我便用它来进行了一些性能问题的复现。还发现其中一些有趣的模式。
首先,我想分析两个测试组的调度特征。我对他们分别进行了perf sched record采样,并使用FlameScope进行了数据可视化。
性能好的分组
客户端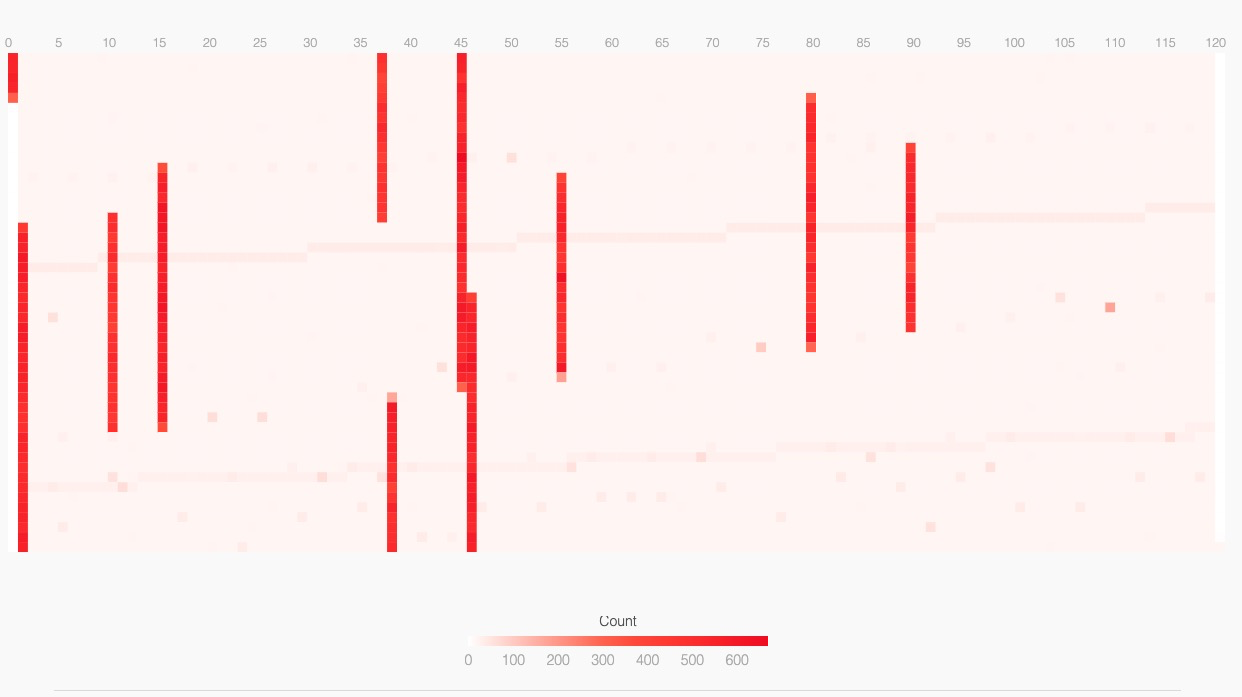 

服务端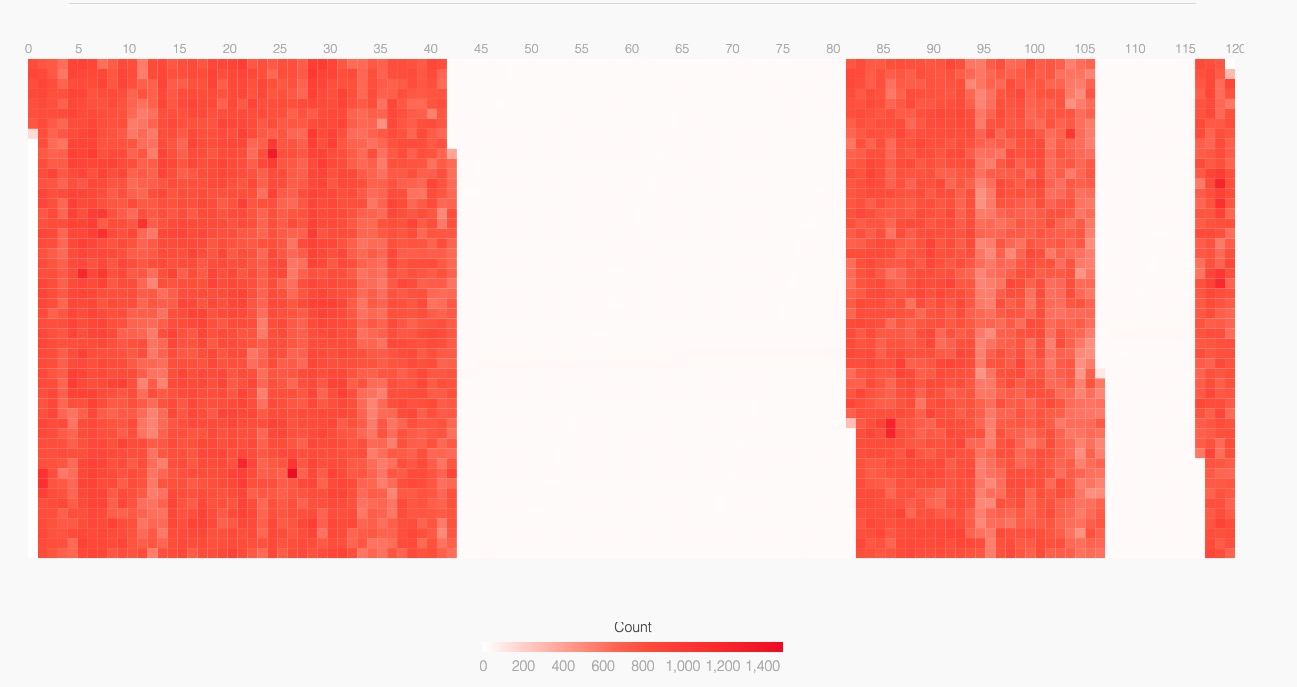 

性能差的分组
客户端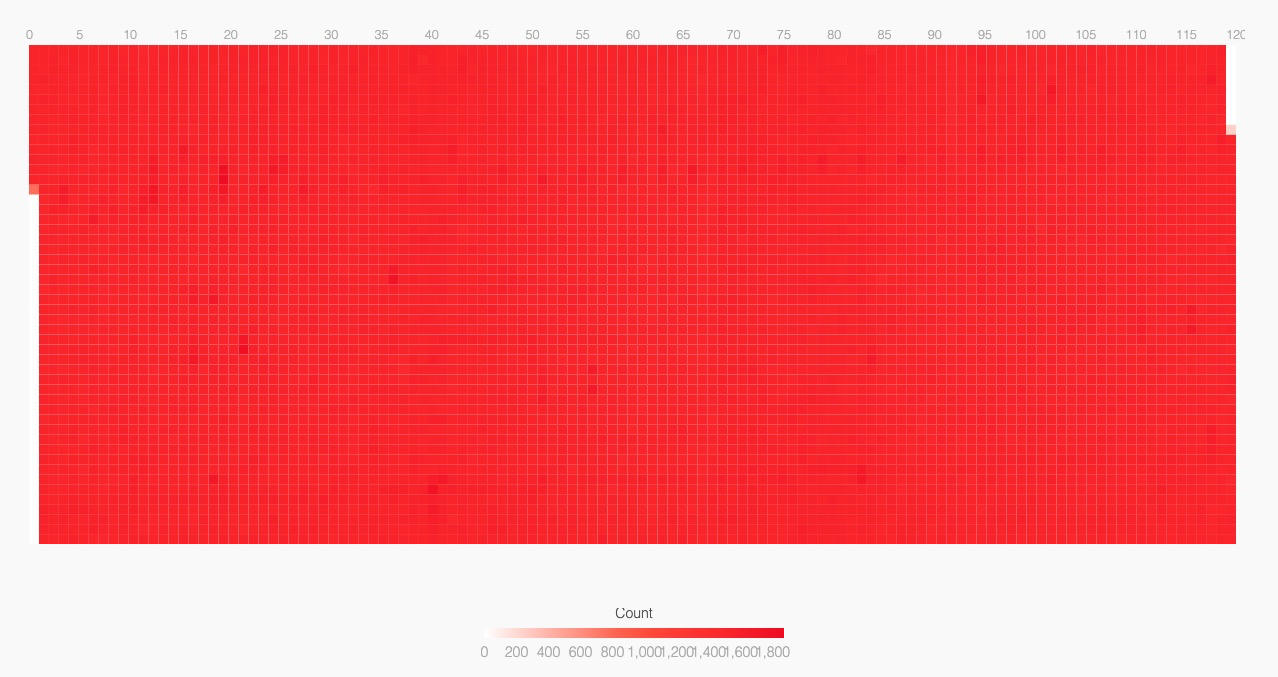
服务端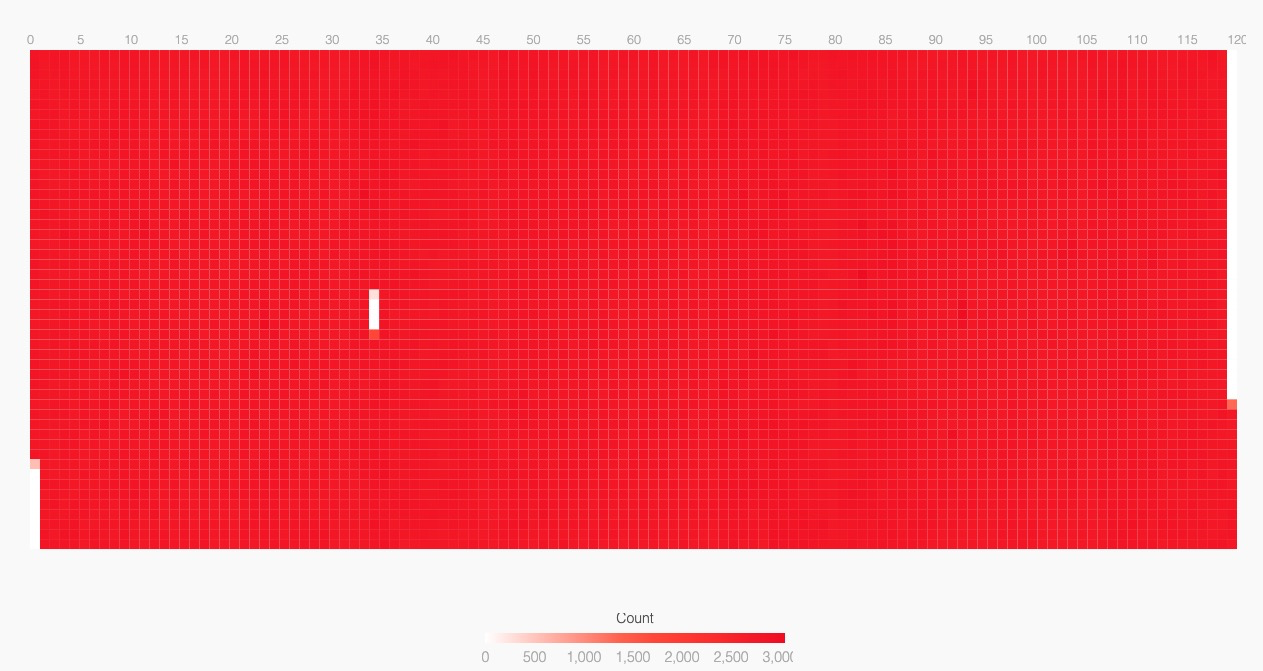 

我们发现性能差的分组,有大量的调度事件,而且发生地非常均匀。性能好的分组则是周期性地繁忙工作若干毫秒(深红色长条),我们还能发现背景里有周期性的轻松任务(浅红色长条)
这个对比,给了我们这两个测试集的调度特征一个直观的感受。但看来分析问题需要借助更多的信息。
于是我使用了Differential Flame Graph分析两个测试集的完整调用栈上的采样。
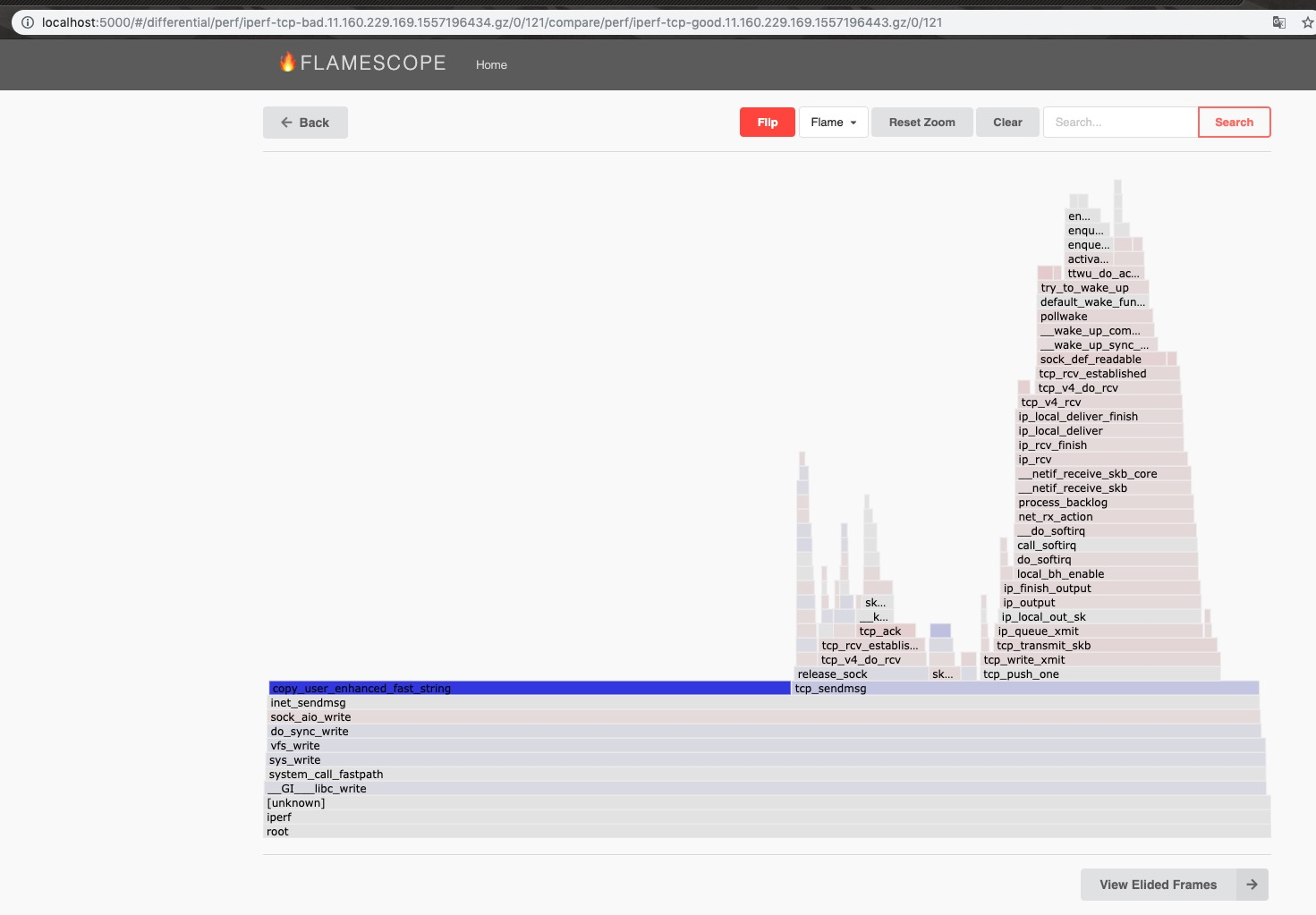
该图便给出一个重要线索,两个测试集最重大的区别,在vfs_write->do_sync_write->sock_aio_write->inet_sendmsg->copy_user_enhanced_fast_string这条路径上。(注意由于内核编译优化等原因,调用路径略有不准确)
性能好的测试组,多调用了很多次copy_user_enhanced_fast_string,性能差测试组的则很少。
之后的工作便于FlameScope关系不大了。这便是我使用FlameScope工具进行测试和性能调优的一个实践。Bredan Gregg大神主导的这个软件,对性能数据阐释的直观性真的太强了~
阅读原文
本文为云栖社区原创内容,未经允许不得转载。














 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









