







通过cloudera manager界面发现线上hadoop环境的某一个datanode节点load average 过高(>160)和cpu利用率过高(>90),top发现绝大部分为lqz(此处已脱敏)的进程在占据cpu和负载,如下截图:
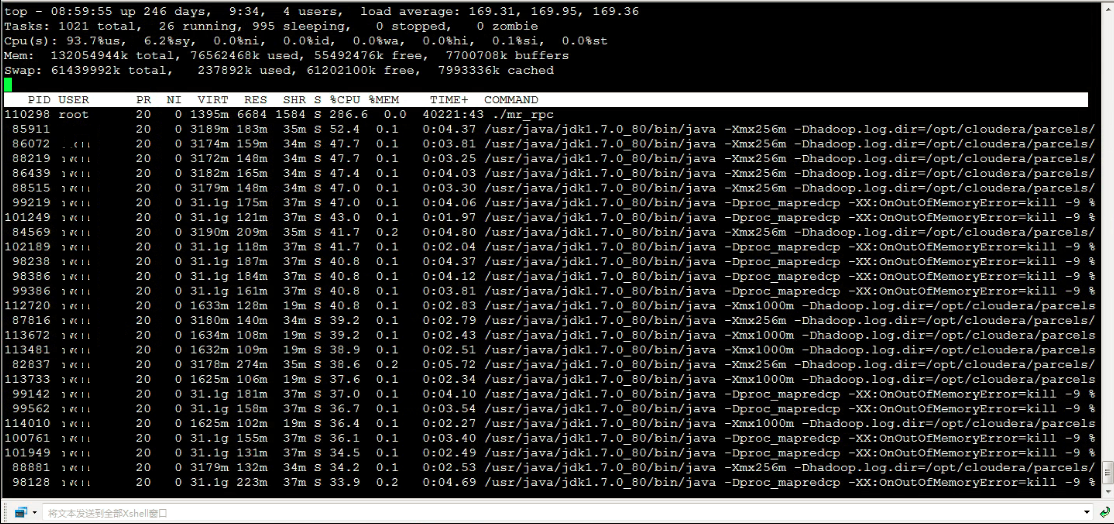
使用如下命令查看具体是哪些java进程
jps -mlv |grep lqz # 此处已进行脱敏经查发现大部分为org.apache.hadoop.hive.cli.CliDriver,共计40个进程
$ /usr/java/default/bin/jps -mlv | grep org.apache.hadoop.hive.cli.CliDriver | wc -l
40 使用如下命令,定位出这些java进程都在执行hive -e hql
ps -ef结合开发分析后,这些java进程进行细颗粒度分区建立操作,调整代码后,机器的负载恢复正常值。
另外,同时在该机负载过高的状态下,cloudera manager 界面显示该节点报“DataNode Pause Duration”,该状态也是间接反映出该节点资源吃紧的问题。















 4166
4166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









