







date: 2017-8-28
1 ARMv8架构简介
1.1背景
2011年,ARM推出了第8代架构ARMv8(ARMv4之前的架构已经被废弃),ARMv8架构是迄今为止ARM历史上变革最大的架构。
如果知道了架构的历史背景,以及设计者的设计理念,那么理解架构的行为方式便很容易了。为了方便后续的研究,我们先来回顾下ARMv8的历史背景(具体可参考ARMv8白皮书,链接地址为:http://www.arm.com/zh/files/downloads/ARMv8_white_paper_v5.pdf,感兴趣的同学可以自行阅读)。
ARM为低功耗而生,过去20年,基于RISC指令集的ARM芯片在各个领域获得广泛的成功。除了移动设备领域,ARM芯片也已经悄悄渗透到PC领域(基于ARM的平板可以给用户带来PC级的体验,尤其是win10宣布支持ARM)、企业与服务器领域(这些领域一直是intel的天下)。为了更精准的响应市场的需求,从ARMv7开始,ARM将其架构分为三个品类,分别是:
- A类,针对Application,适用于追求高性能的场景,比如移动领域(手机)或者企业领域(服务器)
- R类,针对Real-time,适用于车用以及工业控制领域
- M类,针对Microcontroller,适用于微控制器领取
2011年10月,ARM推出了Cortex-A7以及大小核架构,再一次振奋了业界,在延迟电池寿命的同时,为用户提供优秀智能手机的体验。Cortex系列迅速成为ARM新业务中的王牌。
ARM芯片的性能上去了,那些包含复杂运算的大体量程序可以开心的跑起来了。但问题来了,这些大体量的程序需要更多的地址空间(比如超过4G的地址空间),于是AMR在AMRv7中增加了LAPE(Large Physical Address Extensions),使用48位虚拟地址,并将虚拟内存映射到40位物理内存地址上(支持高达1024G的物理内存)。
利用LAPE,内存空间的问题算是暂时解决了,但这只能是补救方案。如果你想继续搞企业级产品,想接着玩服务器,不搞64位操作系统行吗?不搞虚拟化行吗?因此ARM在设计v8架构时,它面临下面几个“刚需”:
- 支持64位
- 虚拟化支持
- 安全增强
1.2运行状态
由于基于32位ARMv7架构的Cortex系列大受欢迎,而且已经建立起完善的开发者生态。因此新架构(指ARMv8)不能推倒重来另起炉灶,必须兼容ARMv7架构中的主要特性。
为了兼容32位程序,新架构将运行状态分成AArch64和AArch32两种状态,这两种状态的具体情形见下表:
| AArch64: | 64bit的运行状态。地址存储在64bit的寄存器中,使用A64指令集,可以使用64bit寄存器 |
| 提供31个64位的通用寄存器(命名为X0-X30,可以通过W0~W30来访问低32位。X30一般用作程序链接寄存器); | |
| 一个64位的程序计数器(PC); | |
| 64位的堆栈指针SP(每个异常等级一个); | |
| 以及64位的异常链接寄存器ELR(每个异常等级一个),存储了从中断返回的地址 | |
| 提供32个128位的NEON浮点寄存器(命令为V0-V31),支持SIMD的向量运算以及标量浮点的运算 | |
| 使用A64指令集,A64指令集使用固定长度的指令,指令使用32位编码 | |
| 重新定义了异常模型,该模型定义了4个异常等级EL0-EL3,异常等级提供了执行权限的等级制度,层级越高,权限越大。 | |
| 支持64位的虚拟地址空间 | |
| 定义了一组Process state寄存器PSTATE(NZCV/DAIF/CurrentEL/SPSel等),用于保存PE当前的状态信息,A64指令集提供专门的指令来访问这些PSTATE | |
| 每个系统寄存器(System register)名称后面都带有一个后缀,该后缀表示可以访问该寄存器的最低EL级别 | |
| AArch32: | 32bit的运行状态。地址存储在32bit的寄存器中,可以使用T32或者A32指令,使用32bit的寄存器 |
| 提供13个32位的通用寄存器(R0-R12); | |
| 一个32位的程序计数器PC; | |
| 一个32位的堆栈指针寄存器SP; | |
| 一个32位的程序链接寄存器LR,LR不仅作为程序链接器也用作异常链接寄存器ELR | |
| 提供一个ELR,用来保存Hyp模式下异常返回的地址,Hyp模式与虚拟化有关。 | |
| 提供32个64位的浮点寄存器,支持Advanced SIMD的向量计算以及标量浮点运算 | |
| 使用A32(使用固定长度指令,指令32位编码)或者T32(使用变长指令,指令编码可以是16位的也可以是32位的)指令集 | |
| 支持ARMv7架构中基于PE模式(FIQ/IRQ/Abort/Undefined/Svc)的异常模型。本质上是将PE模式映射到ARMv8架构中基于异常等级的异常模型中来。 | |
| 支持32位的虚拟地址空间 | |
| 定义了一组Process state寄存器PSTATE(NZCV/DAIF/CurrentEL/SPSel等),用于保存PE当前的状态信息,A32/T32指令集提供专门的指令来访问这些PSTATE。指令可以通过APSR(Application Program Status Register)或者CPSR(Current Program Status Register)来访问PSTATE,就像在ARMv7架构中做的那样。 |
表1:AArch64与AArch32的对比
1.3异常等级
ARMv7及之前的架构,为PE定义了很多种模式:System/User/FIQ/Svc/Abort/IRQ/Undefined,每种模式都有自己的R13(用作SP)与R14(用作LR),FIQ模式还有自己的R8-R12。应用程序大部分时间跑在User模式下。这种设计,一方面是权限隔离,不同的模式有不同的资源访问权限;另一方面,FIQ/Abort/IRQ/Undefined这几种模式与异常或者中断关联,处理相应的异常时迅速切换到对应的模式提高了处理效率。
到了ARMv8,ARM摒弃了这种多模式的设计,重新定义了一套异常或者说等级模型:
- 该模型定义了4个异常等级EL0-EL4,层级越高,特权越大,EL0为非特权等级。
- 在进入异常时会把异常返回地址写入到异常链接寄存器ELR中。
- 异常可以在同异常等级中被处理,也可以上升到更高的异常等级中被处理。EL1/EL2/EL3有各自不同的异常向量基址寄存器VBAR(Vector Base Address Register)。
- Syndrome register提供了异常的详细信息,包括异常的类别、指令的长度、指令的具体信息
异常等级也可以理解为特权级别(Privilege Level)。特权级别划分出来了,那么在每个级别,都可以干那些事?ARM对这4个等级的设想可以描述如下:
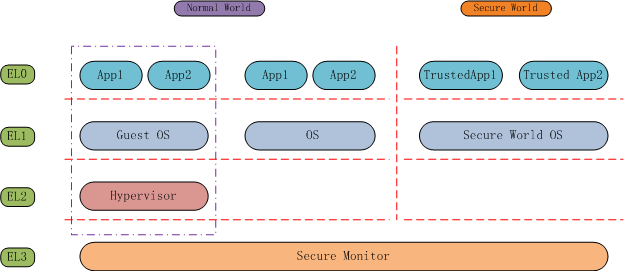
图1:四个异常等级的实施例
- EL0:用来跑应用程序,包括虚拟化中客户操作的程序;Secure状态的App也是运行在该层
- EL1:用来跑操作系统的内核,包括虚拟化中的客户操作系统;Secure状态下的安全操作系统也是运行在该层
- EL2:用来支持虚拟化的Hypervisro运行在该层
- EL3:用来支持Security的Secure Monitor运行在该层
在实现架构时(ARM只是出设计,具体的芯片由厂商实现),并不是所有的EL都要实现,其中EL0-EL1是必须要实现的,EL2主要是为了支持虚拟化,可以不用实现,EL3用来支持Security,也可以不实现。
AArch32运行状态兼容ARMv7中的多模式PE,是通过将不同的PE模式映射到不同的EL来实现的。
如果换做你,如何在ARMv8架构的等级模型上构建Linux操作系统呢?Linux操作系统只用到两个特权级别:用户空间程序与操作系统内核,用户空间的程序一般运行在非特权级别,操作系统内核运行在特权级别,用户空间发起的系统调用,以及触发的异常与中断,都需要交给“具有特权”的内核空间来处理。因此,针对ARMv8架构,用户空间可以落实到EL0层,内核空间可以落实到EL1层。
1.4 AArch32与AArch64之间的关联:
为了向下兼容,ARM v8a将运行状态分成AArch64和AArch32两种状态。AArch64就是64位指令集的运行态,而AArch32是兼容Arm-v7a的状态,所有Arm-v7a以及更早的软件都可以在这个状态上正常运行。对于应用程序来说,由于EL0没有权限进行AArch64和AArch32状态切换的,因此只能一条道走到黑地用一种态。这也是AArch64与AArch32使用各自独立指令集的原因,两种状态下的指令集保持着井水不犯河水的“克制”。但二者在同一个系统中可以共生,难免眉来眼去:
- AArch32与AArch64之间的切换只能发生在进入异常或者从异常返回时。提高异常等级时不能同时降低寄存器的宽度,反之亦然。无法通过分支跳转或者链接寄存器(在旧架构中可以通过BX指令实现ARM与Thumb状态的转换)来实施AArch32与AArch64之间的切换。
- AArch64状态下的操作系统内核之上可以跑AArch64的程序,也可以跑AArch32的程序,反之不行;
- AArch64 Hypervisor之上可以跑AArch64的guest OS,也可以跑AArch32的guest OS,反之不行;
- 允许AArch32 Secure与 AArch64 Non-secure的组合(当前的手机都是双系统,Android跑在AArch64 Non-secure一侧,支付等跑在Secure一侧)。
- 寄存器的映射关系如下:
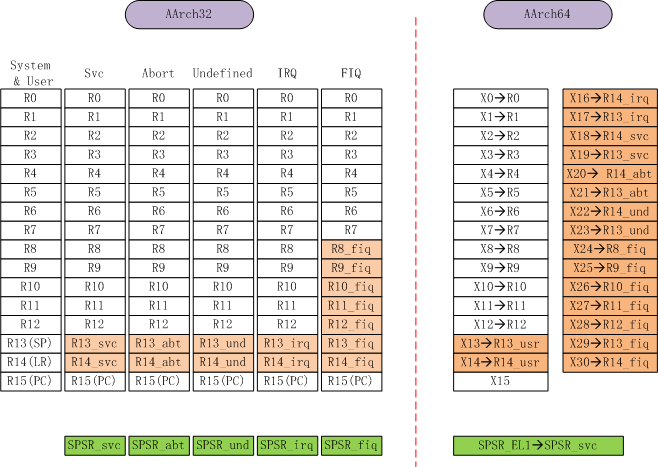
图2:AArch32状态的下用到的寄存器是用AArch64中的寄存器来模拟的
2.地址映射(虚拟地址映射为物理地址)
2.1 地址映射与EL
地址映射就是把PE发出的虚拟地址映射为内存的物理地址的过程。将虚拟地址映射为物理地址,显然这是一件需要“特权”才能干的事(出于安全考虑,不能在非特权级去执行,不然,那些坏人想攻破你的系统不要太容易),需要与特权等级也就是异常等级联系起来:
- EL0之上的异常等级有自己的地址映射context,包括:地址换换表基址寄存器(TTBR)、地址映射控制寄存器(TCR)以及异常syndrome(寄存器)。
- EL0的地址映射由EL1来负责。
- 在Non-Secure状态下,EL2可以为EL1/EL0新增一阶转换。新增的这一阶地址映射被称作Stage 2地址映射,相应的EL1/EL0中那阶转换被称作Stage1地址映射。EL2是为了支持虚拟化,Secure状态下没用EL2这一层;在Linux上可能也没用这一层。
异常等级及其支持的地址映射如下图所示:
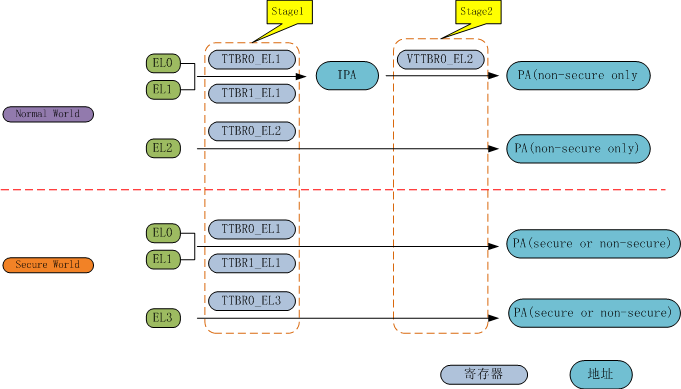
图3:stage1/stage2地址映射与异常等级的关系
安全与非安全是一种“物理隔离”。当PE运行在安全模式下,它可以访问那些标记为安全的内存(表示这些内存只能在安全模式下访问),也可以访问那些标记为非安全的内存。当PE运行在非安全模式,它只能访问那些标记为非安全的内存,而无法访问那些标记为安全的物理内存,从而实现物理隔离。
只有在非安全状态下,从EL1/EL0提升至EL2等级时,Stage2的地址映射才会开启。如果Stage2没有开启,那么Stage1从虚拟地址VA转换后得到的地址就是物理地址PA。而如果Stage2开启,那么Stage1从虚拟地址VA转换后得到的地址被称为“中间态”物理地址IPA,Stage2再将IPA转换为物理地址PA。
地址映射就是将虚拟地址映射为物理地址,Stage1就够了,为什在EL2层又加上Stage2呢?我们可以这样理解:
- 在Stage1,OS把VA转换为它自己认为的PA。这个过程中使用的是由OS管理的页表。如果没有虚拟化,则Stage 1转换得到PA就可以直接访问物理内存。
- Stage 2在虚拟系统(Hypervisor管理多个Guest OS)里有效。可以理解为,Hypervisor把Guest OS认为的“PA”进一步转化为真正的PA。这个过程使用的是另一套由Hypervisor维护的页表。在虚拟化环境中,只有经过Stage 2转换后得到的真正的PA才能访问内存。
在后面的讨论中,我们认为只进行stage 1的地址映射。
2.2地址空间与TTBR
64位系统可以支持更多的虚拟地址空间了,那么需要将虚拟地址直接提高到64位吗?一方面,虚拟地址空间越大,一次地址映射(TTW,translation table walk)就需要更多级(Level)的查找。比如在32位系统中,如果page的尺寸为4K,可能通过两级查找(目录表查找/页表查找)就能将一个32位的虚拟地址映射为对应的物理地址;如果虚拟地址提高到64位,则需要超过4级的查找才能完成一次地址映射,导致地址映射的开销增加。另一方面,当前也没有那么大的物理内存,用40位的物理地址就能覆盖1024G的物理内存了,已经足可以应付当前及未来很长一段时间的需求了。
因此,ARMv8的地址映射基于ARMv7的LAPE机制,LAPE的设计之初是要解决在如何在32位系统给程序提供超过4G内存空间的问题。LAPE使用48位虚拟地址,并且可以将虚拟内存映射到40位物理内存地址上。每个TTBR(地址映射表基址寄存器)最多可支持48位的虚拟地址空间,具体的位数在运行时设定。在一次TTW过程中,有多少个级别的查找,取决于使用多少位的虚拟地址。
如果地址映射只支持一个VA区间(TCR_ELx 中如果只有T0SZ域有效,说明地址映射只支持一个虚拟地址空间),则TTBR_ELx指向转换表的基址,且L0(第一级)查找必须使用该转换表。VA区间的虚拟地址位数=64-TTBR_ELx.T0SZE。
如果地址映射支持两个虚拟地址区间(TCR_ELx 中T0SZ域与T1SZ域都有效),则每个虚拟地址区间对应一个TTBR_ELx寄存器,其中TTBR0_ELx指向第一VA区域(起始地址为0x0000000000000000)的转换表的基址,第一VA区域的虚拟地址位数=64-TCR_ELx.T0SZ;TTBR1_ELx指向第二个VA区域(截止地址为0xFFFFFFFFFFFFFFFF)的转换表的基址,第二个VA区域的虚拟地址位数=64-TCR_ELx.T1SZ。
下图展示了EL1/EL0 Stage1的地址映射,该转换支持两个VA区域,虚拟地址位数为48,各个VA区域的地址空间范围如图中所示:
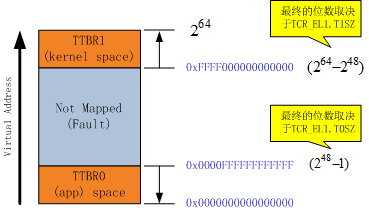
图4:当地址映射支持两个VA区域时每个VA区域的分布情况
- 两个区域分布在整个64区域的两端,区域起始是固定的,区域的大小可以单独指定,每个区域有自己专属的TTBR。在上图中,每个区域都覆盖了2^48-1 的地址空间
- 两个区域之间的区域没有映射,访问这里的地址会踩到雷——触发异常。
- 在linux系统中,可以将高端地址给内核使用,低端地址给用户空间使用。
虚拟地址的位数确定了为48位,那么我们要为48位的虚拟地址重新创建一种数据类型吗?完全没必要,我们用现成的64位整数来存储地址,只是在进行地址映射时,从64位中取出“有效地址位”即低48位作为虚拟地址。高16位完全可以拿来“变废为宝”,记录一些额外的信息。
2.3转换粒度与4级查找
虚拟地址的位数定下来了,那么地址映射过程中要经过几级查找,才能把虚拟地址对应的物理地址找到呢?这与地址映射粒度有关。转换粒度由两个含义:一是page的大小,二是查找表的大小即表中包含多少个表项。page大小与查找表之间有什么关联呢?为了提高效率,一般将查找表的尺寸与page对齐,这样一个page就能容纳一张查找表了。查找表的尺寸确定了,表中每一项的尺寸是固定的(为64位),那么整个查找表的大小就可以确定了。
ARMv8架构支持3种地址映射粒度,如下表:
| 4KB granule | 16KB granule | 64KB granule | |
| 查找表的大小(最多可以容纳的条目数) | 512 | 2048 | 8192 |
| 每级查找消耗虚拟地址中的位数 | 9-bit | 11-bit | 13-bit |
| 页内偏移offset | VA[11,0] | VA[13,0] | VA[15,0] |
| 支持几级查找 | 4级 | 4级 | 3级 |
| TCR_ELx.TG0域(共2bit)的取值 | 00b | 10b | 01b |
表2:3种转换粒度对比表
我们以4KB的粒度来说明上表中各项的含义。
- 在4KB粒度中,page的大小为4K,每个查找表的表项为8byte,4KB一共可以容纳512个表项(512*8=4096)。因此查找表的大小为512。
- 512=2^9,因此用9bit即可以覆盖整个查找表,所以每级别查找表消耗(或者说解析)虚拟地址中的9个bit。
- 通过多个级别(比如4个级别)的查找,我们找到了对应的物理内存在哪个page上,即容该物理内存的page的基址,那么最终的物理地址=page的基址+业内偏移。这个业内偏移就是虚拟地中,用查表之后剩余的未消耗的bit来表示。页的大小为4K,那么页的基址(这里已经是物理地址了哇)肯定是4K对齐的,即地址的低12为0(12bit能表示的最大范围是2^12-1 ,即4K-1,如果地址按4K对齐,低12位肯定为0,从13位开始的地址才是“有效”的),那么虚拟地址中的低12位即VA[11,0]就是用来表示页内偏移的。
- 虚拟地址中的最低几位是用来表示页内偏移的,那么其余的位段就是用来查表的,已知每级查找消耗的bit数,共有几级查找就很明了。对4KB的粒度来说,支持(48 – 12) / 9 = 4级查找。当转换粒度提高时,所需的查找级数(或者次数)就变少了,使得地址映射过程变得更平坦。平坦的含义是,之前需要4级查找,现在只需要两级了,把4层的楼房拍扁变成两层,可不就是更平坦了嘛。
- 转换粒度由TCR_ELx寄存器的TG0域来指定,参考上表中的定义。
如无特殊声明,后文中我们讨论的地址映射是以4KB为粒度的。4KB转换粒度下的4级查找,如下图所示:
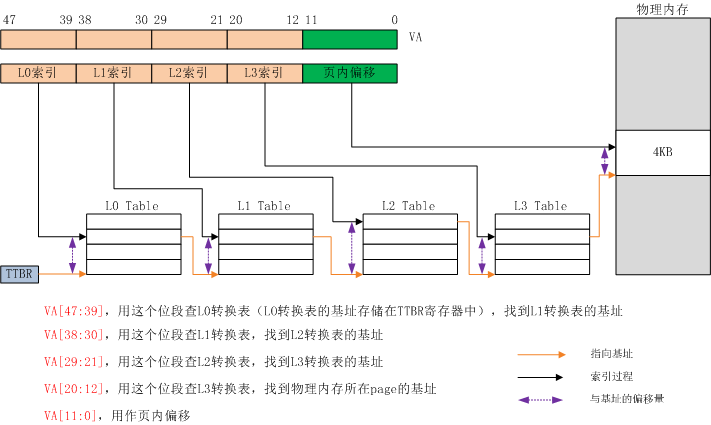
图5:查找粒度为4K时4级查找过程
我们历经4级查找,最终目的是为了找到容纳目标物理内存的物理页的起始地址。物理内存是以页为单位组织起来的,因此,要找物理内存,先找到它所在的页。这种内存管理方式被称作页式内存管理。
现在我们思考一个问题,为什么要创建这种层级查找结构,为什么不干脆搞一张超大的页表,表里的每一项指向一个页面的基址。这样只需要查一次表就可以完成地址映射了,整个结构更扁平了,如下图示意。
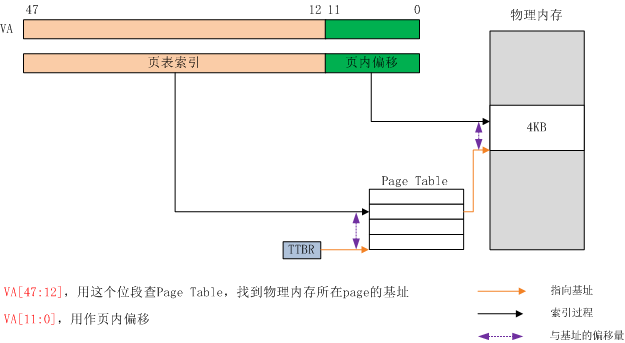
图6:一种设想的只需要一级查找的地址映射过程
这种架构至少存在下面几个问题:
首先,Page Table的大小问题。为了完成一次就能找到的目标,Page Table肯定是个线性表(不能玩hash表那一套),用索引做下标直接可以找到对应的项,而我们又是拿虚拟地址去索引这张表,因此虚拟地址覆盖多少个Page,Page Table中就应该有多少项。因此在32位系统中就有 4G/4K=1M个Page。所以Page Table中要有1048576个表项,每个表项4byte,则Page Table就要消耗掉4M的空间。如果实际的物理内存只有512M,那Page Table中的很多项就会白白浪费。而在4级查找中,通过4个层级的查找表,我们建立起了一个查找树(或者目录树),整棵查找树是动态形成的。一个进程不可能用光所有的虚存空间,虚存空间中肯定有不同大小级别的空洞,在树形结构中,对于空洞我们可以不创建对应的查找表从而节省空间。下图展示了AArch64的4级查找表构成的查找树。L0 Table中的一个表项领衔512G的地址空间,如果进程用不到这块地址空间,那么以该表项为根,衍生的1个L1 Table以及512个L2 Table,以及由512个L2 Table衍生的512*512个L3 Table都不会被创建。同样,L1 Table的一个表项领衔1G的地址空间,如果该1G空间不会被用到,那么由该表项衍生的所有查找表都不会被创建。
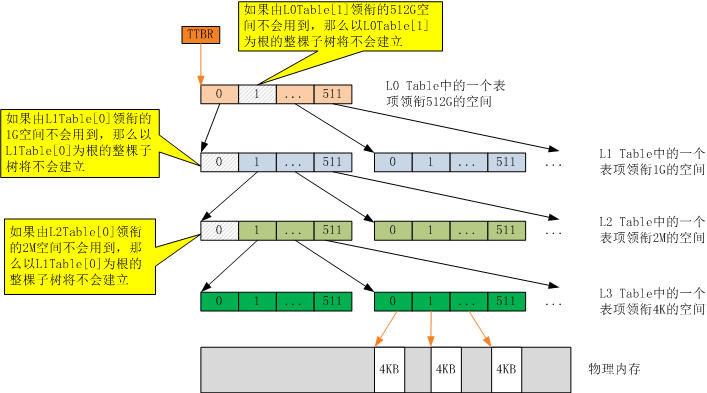
图7:4个层级组成的查找树
其次我们要考虑cache命中率的问题。由于那张Page Table太大了,cache每次只能装载其中的一部分。由于地址的跳跃,导致Page Table的索引跳跃,导致之前加载到cache中内容失效,需要重新装载cache。而在4级查找结构中,每个查找表的size与Page size对齐,提高了cache的命中率。
综合这两点,我们得到结论:页式内存管理是综合考虑空间与效率的结果。
2.4内存block
通过前面的介绍,我们已经看到了,4KB的转换粒度需要4个级别的查找(所以才用translation table walk来描述地址映射过程,转换过程就像在一条分叉众多的路上行走一样,每到一个路口,就需要拿出你的指南针,去找到前进的方向),这条路径并不短。有没有可以提前结束查找的方法呢?
ARM在内存页之外,提出内存block,一个block包含多个连续的页,一个块可以覆盖的空间更大。如果我们我们知道物理内存在某个块中,而且知道了相对于块基址的偏移,那么我们只需要找到这个块的基址,再加上块内偏移,便可以得到物理内存的地址,从而提前就是查找过程。因此查找表中,可能存在在两种表项:
- 一种表项指向下一级转换表的基址,就像上图展示的一样。这种表项记作table描述符
- 另一种指向一个物理块的基址,虚拟地址中剩余的位段作为块内偏移,如此便可以愉快地获取物理地址,提前结束查找之旅。这种表项记作block描述符
4KB转换粒度下的4级查找可以进化到这种样子:
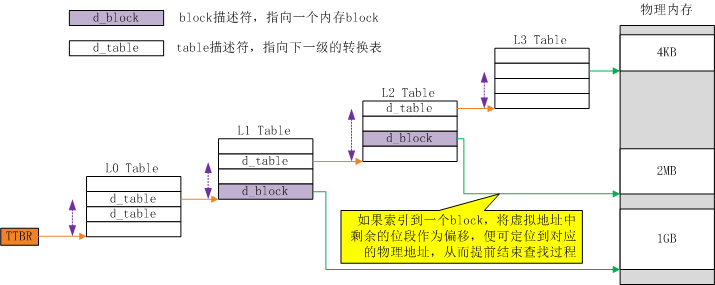
图8:考虑内存block后,4KB转换粒度下的4级查找
在上图中我们也看到,在4KB的转换粒度下的4级查找中,只有L1 Table以及L2 Table中可以出现block描述符。L1 Table中的一个block描述符领衔1GB的地址空间(因为剩下的位段为IA[29:0]共30bit,可以覆盖1G的空间),T2 Table中的block描述符领衔2MB的地址空间(因为剩下的位段为IA[20:0]共21bit,可以覆盖2MB的空间)。block描述符与转换粒度的关系见下表:
| 转换粒度 | block描述符 |
| 4KB | L0 不支持block描述符 L1 支持block描述符,一个block领衔1GB的地址空间 L2 支持block描述符,一个block领衔2MB的地址空间 |
| 16KB | L0/L1不支持block描述符 L2 支持block描述符,一个block领衔32MB的地址空间 |
| 64KB | 不支持L0级别的查找(只有三级查找:L1-L3) 如果ARMv8.2-LPA功能没开启的话,L1不支持BLOCK L2支持block描述符,一个block领衔512MB的地址空间 |
表3:3种转换粒度下block描述符对比
请大家思考下,当转换粒度为4K时,为什么L0不支持block呢?
因为L0如果支持block的话,一个block领衔512G空间。一方面当前Android手机的内存最大才12G,上哪去找一块连续的大小为512G的物理内存呢?另一方面block太大,也缺少一些必要的灵活性。
上表中并没有说L4是否支持block,要不要支持呢?答案是不需要支持。L4中维护的已经是页表了,在L4这个级别,即使支持block,block的尺寸已经与page一致了,当然就没必要多此一举再支持block了。
2.5查找表中的描述符
L0-L3查找表中的描述符格式:
前文说过,L0-L3的转换表中的描述符可能存在两种情况:table描述符与block描述符。下图列出转换粒度为4KB时,L0-L3的描述符格式:
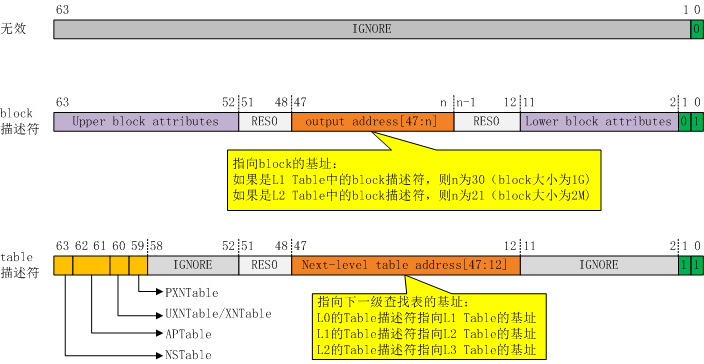
图9:4KB转换粒度下的L0-L2对应的描述符格式
我们拿64位的整数来表示地址,前文提到过,有效的虚拟地址只有48位,因此其他的位段可以挪作他用。由于转换表的尺寸与page对齐,转换表的基址与4K对齐,所以48位的基址中低12位肯定为0,这低12位也可拿来做文章。这里用bit[1:0]来指示该描述符的类型,如下表:
| Bit[1:0]取值 | 描述符类型 |
| ‘x0’ | 无效描述符 |
| ‘01’ | block描述符,output address指向一个block的基址 |
| ‘11’ | Table描述符,next-level table address指向下一级转换表的基址 |
表4:L0-L2描述符类型
在block描述符中,bit[63:52]与bit[11:2]这两个位段用来描述block属性(后文讨论这些属性)。
在table描述符中,bit[63:59]用来表示与table有关的属性,详细如下表:
| 标志位 | 描述 |
| NSTable | NS表示Non-Secure,该table描述符指向的下一级的转换表是否存储在secure memory之中。 为0表示存储在Secutre PA中,否则表示存储在Non-secure PA中。 当在non-secure状态下进行地址映射时,该标志别忽略 |
| APTable | AP表示Access Permission,这两个标志为指明了下一级转换表的访问权限,有如下4中情况: ‘00’——不做限制 ‘01’——EL0没有权限访问 ‘10’——任何异常等级都不能写(修改转换表) ‘11’——任何异常等级都不能写(修改转换表);而且EL0不能读 |
| UXNTable /XNTable | 当地址映射支持两个VA区域时,名称为UXNTable,当地址映射只支持一个VA区域时,名称为XNTable。 UXN 的含义是“Unprivileged Execute Never”,XN的含义是“Execute Never”。它们用来表示内存的执行权限。比如我们在加载动态库时,动态库的代码段所在的地址就具有执行(x)权限。如果标志位为0表示具有执行权限,否则没有执行权限。 |
| PXNTable | 该标志只有当地址映射支持两个VA区域时有效。PXN表示Privileged Execute Never,表示内存是否具有“特权执行”权限,比如内核的代码便具有“特权执行”的权限。 |
表5:Table描述符中的标志位
L3页描述符格式:
L3查找表即页表,4KB转换粒度下,页表的描述符格式如下:
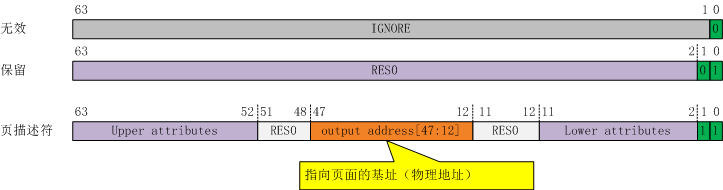
图10:4KB转换粒度下的L3页描述符格式
页描述符与block描述符中的属性字段:
从前文可知,block描述符与page描述符都有两个属性位段,主要的属性字段如下:
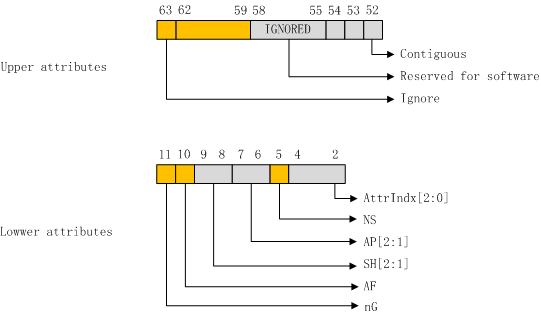
图11:block描述符与table描述符中的属性位段
这些属性的含义如下表:
| 属性位段 | 描述 | |||||||||||||||
| Contiguous | 该表项是否为连续表项中的一项。即转换表在该表项前后是连续的,没有空洞。这样,这些连续的表项便有可能一次性加载到cache中(比如由一个TLB entry缓存) | |||||||||||||||
| nG | not Global 如果该表项缓存在TLB中,该标志位指示TLB entry是全局有效还是仅仅对当前进程有效 | |||||||||||||||
| AF | Access Flag 当该标志为0,标明对应的内存区域(一个block或者一个page)是第一次访问 | |||||||||||||||
| SH | Shareability Field 参考后文 | |||||||||||||||
| AP[2:1] | Access Permission. control the stage 1 data access permissions, and: AP[2] Selects between read-only and read/write access. AP[1] Selects between Application level (EL0) control and the higher Exception level control. This provides four permission settings for data accesses: • Read-only at all levels. • Read/write at all levels. • Read-only at the higher Exception level, no access by software executing at EL0. • Read/write at the higher Exception level, no access by software executing at EL0. the following talbe shows the meaning of the AP[2:1] field for stage 1 of a translation regime that applies to both EL0 and a higher Exception level. In this table, an entry of None indicates that any access from that Exception level faults.
| |||||||||||||||
| NS | Non-secure 当从Secure状态访问内存时,该标志指示转换后的地址在Secure区域还是在Non-Secure区域 | |||||||||||||||
| AttrIndx | 指向内存区域的类型以及可缓存性。 参考后文 |
表6:block描述符与table描述符中的属性字段的含义
ARMv8中定义了如下两种内存类型(在ARM手册中,类型是从内存模型的角度来描述,这里摘自网络定义)
| 类型 | 特性 |
| Normal (普通) | 。读写经过Cache 。支持乱序,内存访问顺序同编程顺序可能不一致 。支持预读取 。支持内存非对齐访问 |
| Device (设备) | 。读写不经过Cache 。不支持乱序内存访问 。不支持预读取 。不支持内存非对齐访问 Device类型的内存还有三个属性,分别用G/R/E来表示,它们的定义是:
|
表7:内存类型分为normal与device
除了类型外,ARM还定义了其他内存特性,它们的含义如下:
| Shareability (可共享性) | 指当前内存页表项的数据是否可以同步到其它CPU上,多核CPU调用带有该属性页表项的数据,一旦某个CPU修改了数据,那么系统将自动更新到其它CPU的数据拷贝,实现内存数据一致性. 对于Normal类型的内存,有3种情况: • Inner Shareable, meaning it applies across the Inner Shareable shareability domain. • Outer Shareable, meaning it applies across both the Inner Shareable and the Outer Shareable shareability domains. • Non-shareable. |
| Cacheability (可缓存性) | 指当前内存页表项对于的数据是否可以加载到Cache当中 对于Normal类型的内存,有3种情况: • Write-Through Cacheable. • Write-Back Cacheable. • Non-cacheable. |
表8:内存的可共享性与可缓存性
3总结
本文首先介绍了ARMv8的历史背景,了解了ARMv8主要的发力点:一是为了支持更大的地址空间,ARMv8被设计成64为的架构,并且重新设计的指令集T64;二是为了应对企业级(服务器)的市场,提供对虚拟化的支持;三是对安全的增强。
为了兼容旧的架构,ARMv8定义了两种运行状态:AARch64与AArch32,在AArch64状态下运行64位指令,在AArch32状态下运行32位的ARM指令或者16位的Thumb指令。
ARMv7及之前的架构为处理器设置了7种模式(mode),并在此基础上搭建了ARM的异常处理架构。ARMv8摒弃了这种设计, 它定义了4个异常等级(简称EL),异常等级构成了一个特权的等级制度,ARMv8在此基础上构建新的异常处理架构。CPU厂家在实现自己的CPU时,只有EL0与EL1是必选项,EL2(主要用来支持虚拟化)与EL3(主要用来支持安全)是可选项。
当EL2存在时,ARM可以提供两个stage的地址映射。不过EL2主要用作虚拟化,手机上的CPU可以不实现。这个时候只需要经过一个stage的地址映射,就能将虚拟地址(VA)转换成物理地址(PA)。一个stage 的地址映射可以支持两个VA区域,比如第一VA区域(起始地址为0x0000000000000000)给用户空间使用,第二个VA区域(截止地址为0xFFFFFFFFFFFFFFFF)给内核使用。
ARMv8虚拟内存架构发展自ARMv7的LAPE机制,支持48位虚拟地址。不过最终虚拟地址的宽度可以通过TCR_ELx的T0SZ域或者T1SZ域(对于支持两个VA区域的地址映射来说)来指定。虚拟地址的宽度定好后,虚拟地址的空间大小便确定下来了。
ARMv8支持3种转换粒度(通过TCR_ELx寄存器的TG0域来指定):4KB、16KB与64KB。转换粒度不仅定义了page的size,也定义了查找表的尺寸。当转换粒度为4KB时,一个stage的地址映射支持4个level的查找(这与linux的4级内存管理暗合),这四个level分别记作L0~L3。这样,一个虚拟地址便被分成了5部分:L0 Index、L1 Index、L2 Index、L3 Index与offset。在查找时,拿Lx Index在Lx Table中查表(就是将Lx Index作为索引,拿Lx Table的基址 + Lx Index),得到下一级查找表的基址。L0 Table的基址存储在寄存器TTBR中。L3 Table是一个页表PT,页表中每个表项指向一个物理page的起始地址,当通过4级查找之后,就可以找到虚拟地址对应的物理地址。
为了加快地址映射过程,当转换粒度为4KB时,可以在L1 Table或者L2 Table中插入一些block描述符,block表示匹配到一块连续的物理内存。在地址映射过程中,如果虚拟地址与一个内存块匹配,则可以提前结束查找过程,从而提高地址映射效率。因此,在L0~L2 的Table中,存在两种描述符:block描述符与table描述符。
我们拿64位的整数来表示地址,L0~L3 Table中的描述符也是64位的,而有效的虚拟地址只有48位,因此描述符中的其他的位段可以挪作他用,比如用作标记或者用来指示转换表以及内存的相关属性。















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









