







本文分析基于Nginx-1.2.6,与旧版本或将来版本可能有些许出入,但应该差别不大,可做参考
在Nginx中对array、list、queue、RB tree和hash表进行了实现,这些结构所涉及的内存管理都是在内存池中进行,源代码都位于src/core目录下。
#Array# 相对来说,数组是Nginx中最简单的数据结构,它是在内存池中分配的,与语言原生的数组相比,增强了功能,使用时可把它当做变长的,不必担心越界访问。通过ngx_array_t结构体描述了数组的结构信息。
为方便描述,称ngx_array_t结构体为数组的头(header),为数组元素分配的连续空间为数组的体(body)。
其结构如下图所示:
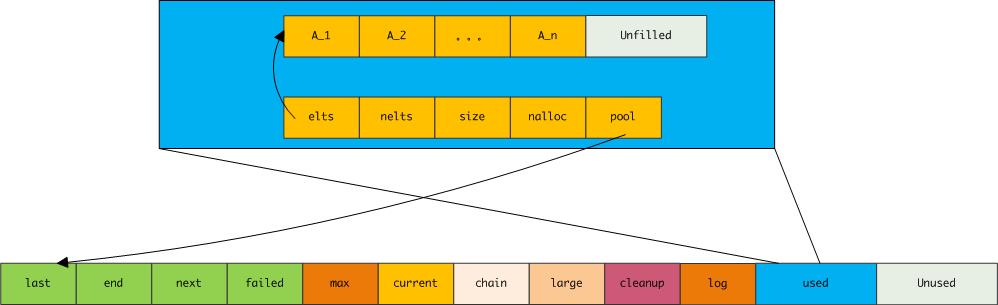
其中elts指向的是数组真实数据的存放位置,nelts是指数组中已经填充的元素个数,size是元素的大小,nalloc是分配的数组空间可容纳的元素数,pool指向的是数组内存所在的内存池。
数组操作比较简单,共有5个函数,
-
创建ngx_array_create:其过程是首先分配空间给一个ngx_array_t结构体(即header),然后分配n*size大小的空间供数组中元素存放,之后初始化header,并返回它的首地址。
-
初始化ngx_array_init:它与创建相比,只少了第一个步骤。
-
销毁ngx_array_destroy:它并不是真正地释放数组所占用空间(内存池中的内存释放由内存池统一进行),而是有条件地更新内存池信息。(条件是:数组空间在内存池已用空间的最后位置)
-
ngx_array_push:这也并不是真正地往数组中添加一个元素,而只是向数组请求划分出一个元素大小的空间并返回。此过程分两种情况,
-
如果数组body中还有空闲,则把第一个可填充元素的位置返回;
-
如果数组body已满,并且
-
数组body在内存池已用空间的最后位置,且紧挨数组body之后还有足够的空间存放元素,则由内存池划分紧挨body的一个元素空间给body。
-
否则,在内存池中分配原数组body两倍大小的空间,并把原数组中的元素复制到新空间,并更新数组的结构信息(header)。
-
ngx_array_push_n:同上面一样,这也只是向数组请求划分出n个元素大小的空间并返回,过程大同小异。
瞧下array的使用(这段代码在ngx_hash.c中,在下面分析hash表时会见到ngx_hash_key_t 结构,可见ngx_array_push只是返回可填充元素的位置,具体内容还得再调用之后赋值:
<!-- lang: cpp -->
ngx_array_t curr_names;
ngx_hash_key_t *name;
if (ngx_array_init(&curr_names, hinit->temp_pool, nelts,
sizeof(ngx_hash_key_t))
!= NGX_OK)
{
return NGX_ERROR;
}
name = ngx_array_push(&curr_names);
if (name == NULL) {
return NGX_ERROR;
}
name->key.len = len;
name->key.data = names[n].key.data;
name->key_hash = hinit->key(name->key.data, name->key.len);
name->value = names[n].value;
#List#
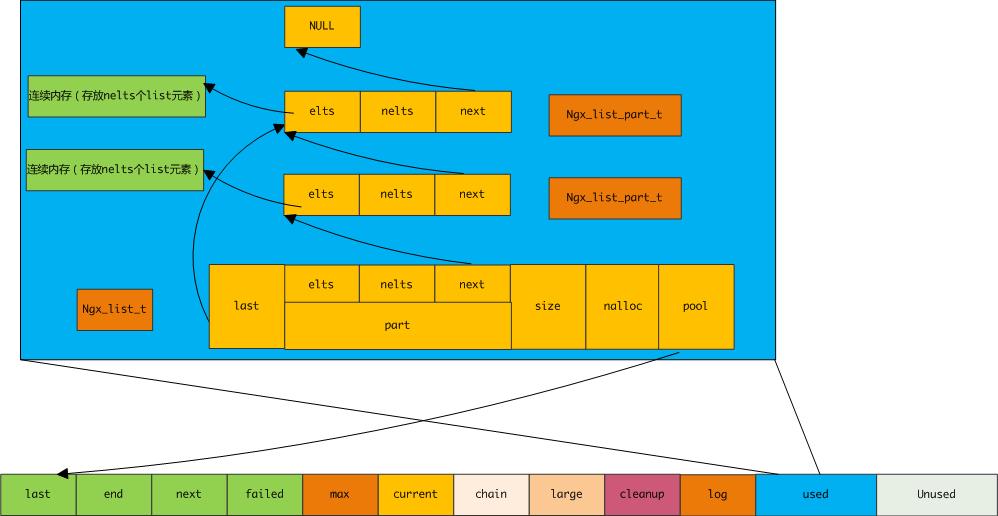
list结构中有个单向链表把所有的part串联起来,并在last域中记录下最后一个part便于在链表结尾插入新part,list中所有元素大小是相同的为size,nalloc指的是在list中已经分配了多少个元素的空间。
list中只有三个相关操作,create,init,push,在ngx_list.h和ngx_list.c中定义。
与array类似的是,ngx_XXX_create只是对array或list的空间进行分配,当然它们的空间都分两部分,一部分是header,一部分是body;ngx_XXX_push都只是返回一个可以填充元素的位置并对header进行更新,而body中的元素内容在调用此函数之后再赋值填充。
与array不同的是,在push操作中,当已分配的空间都填满元素时,list会新建一个part(ngx_list_part_t),并在新part中划出空间并返回。
源码中给出了遍历list的示例代码如下:
<!-- lang: cpp -->
/*
* the iteration through the list:
*/
part = &list.part;
data = part->elts;
for (i = 0 ;; i++) {
if (i >= part->nelts) {
if (part->next == NULL) {
break;
}
part = part->next;
data = part->elts;
i = 0;
}
... data[i] ...
}
#queue#
queue是中双向循环队列,设有一标记(sentinel),它之后是队列头,之前是队列尾。结构如下图所示。
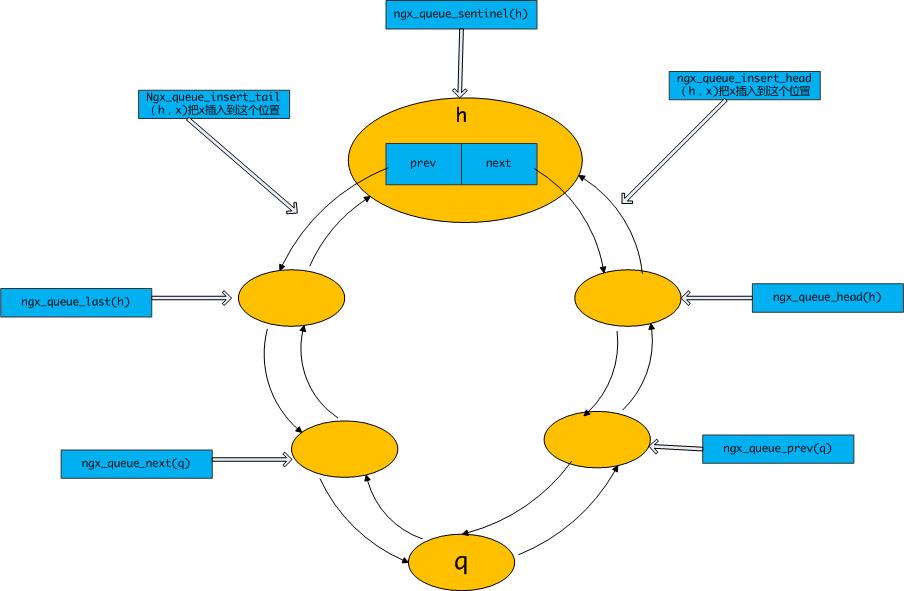
对queue的操作多用宏定义,除图中画出的,还有:
- ngx_queue_remove(x) :队列中移除节点x
- ngx_queue_split(h, q, n) :h为队列的标记,q为队列中的一个节点,这个宏意思是把原队列拆分成两个,一个是仍以h为标记的队列,其中包含了原队列q之前(到标记为止)的所有结点,另一个是一n为标记的队列,其中包含了原队列q之后(包括q,到标记为止)的所有节点。
- ngx_queue_add(h, n) :h和n是两个队列的标记,这个宏意思是将n队列中的节点(除了标记n)连接到h队列的末尾,将两个队列进行合并,这样组成了一个以h为标记包含原来两个队列所有节点的新队列。
ngx_queue_t中并没有存储数据,所以使用时需在自定义结构体中嵌入一个ngx_queue_t类型的变量,其使用方法如下图所示:
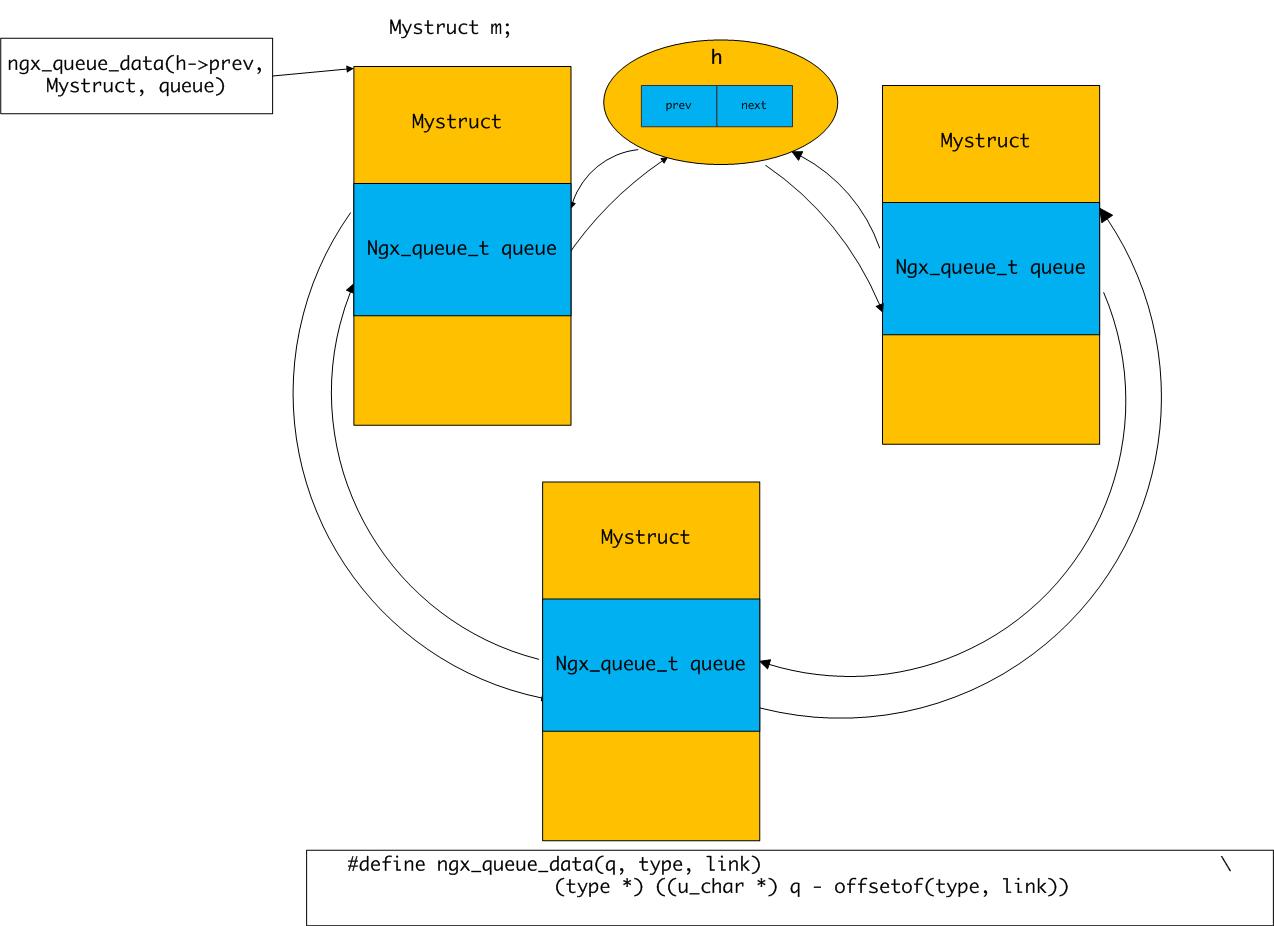
另外有两个函数:
- ngx_queue_middle(queue)有注释:寻找队列中间节点(find the middle queue element if the queue has odd number of elements or the first element of the queue's second part otherwise)
- ngx_queue_sort(queue, cmp)使用稳定插入排序算法对queue队列进行排序,完成后在next方向上为升序
#RB Tree#
红黑树是一种平衡的二叉查找树。其性质和操作在各种算法书上都有,搜一下,也很多,不细讲。贴上相关结构代码如下:
<!-- lang: cpp -->
typedef ngx_uint_t ngx_rbtree_key_t;
typedef ngx_int_t ngx_rbtree_key_int_t;
typedef struct ngx_rbtree_node_s ngx_rbtree_node_t;
struct ngx_rbtree_node_s {
ngx_rbtree_key_t key;
ngx_rbtree_node_t *left;
ngx_rbtree_node_t *right;
ngx_rbtree_node_t *parent;
u_char color;
u_char data;
};
typedef struct ngx_rbtree_s ngx_rbtree_t;
typedef void (*ngx_rbtree_insert_pt) (ngx_rbtree_node_t *root,
ngx_rbtree_node_t *node, ngx_rbtree_node_t *sentinel);
struct ngx_rbtree_s {
ngx_rbtree_node_t *root;
ngx_rbtree_node_t *sentinel;
ngx_rbtree_insert_pt insert;
};
其中*sentinel就是叶子节点(Nil)。
函数ngx_rbtree_insert_value和ngx_rbtree_insert_timer_value为实现的ngx_rbtree_insert_pt handler,是按普通二叉查找树的方式插入一个节点,并标记此节点的color为红色,这是红黑树中插入节点的第一个步骤。两者的区别,在于节点key值的比较,后者考虑了值溢出的情况,是针对节点key是timer值而实现的。
<!-- lang: cpp -->
/*在ngx_rbtree_insert_value中*/
p = (node->key < temp->key) ? &temp->left : &temp->right;
/* 在ngx_rbtree_insert_timer_value中*/
/*
* Timer values
* 1) are spread in small range, usually several minutes,
* 2) and overflow each 49 days, if milliseconds are stored in 32 bits.
* The comparison takes into account that overflow.
*/
/*
* 要比较的两个timer值通常相差不大,大概几分钟而已
* 而0xFFFFFFFF小于50天的毫秒数,所以当值超过50天时就会溢出
* 所以0xFFFFFFF0和0x0000000F的timer值比较,应该认为0x0000000F值溢出
* 其本来值应该大于0xFFFFFFF0,所以才有此区别。
*/
p = ((ngx_rbtree_key_int_t) (node->key - temp->key) < 0)
? &temp->left : &temp->right;
//红黑树tree中插入节点node
void ngx_rbtree_insert(ngx_thread_volatile ngx_rbtree_t *tree,ngx_rbtree_node_t *node)
//红黑树tree中删除节点node
void ngx_rbtree_delete(ngx_thread_volatile ngx_rbtree_t *tree, ngx_rbtree_node_t *node)
#hash# 这里已经有很好的分析,创建hash和查找的过程可参考他那里。
把他的图也复制了过来,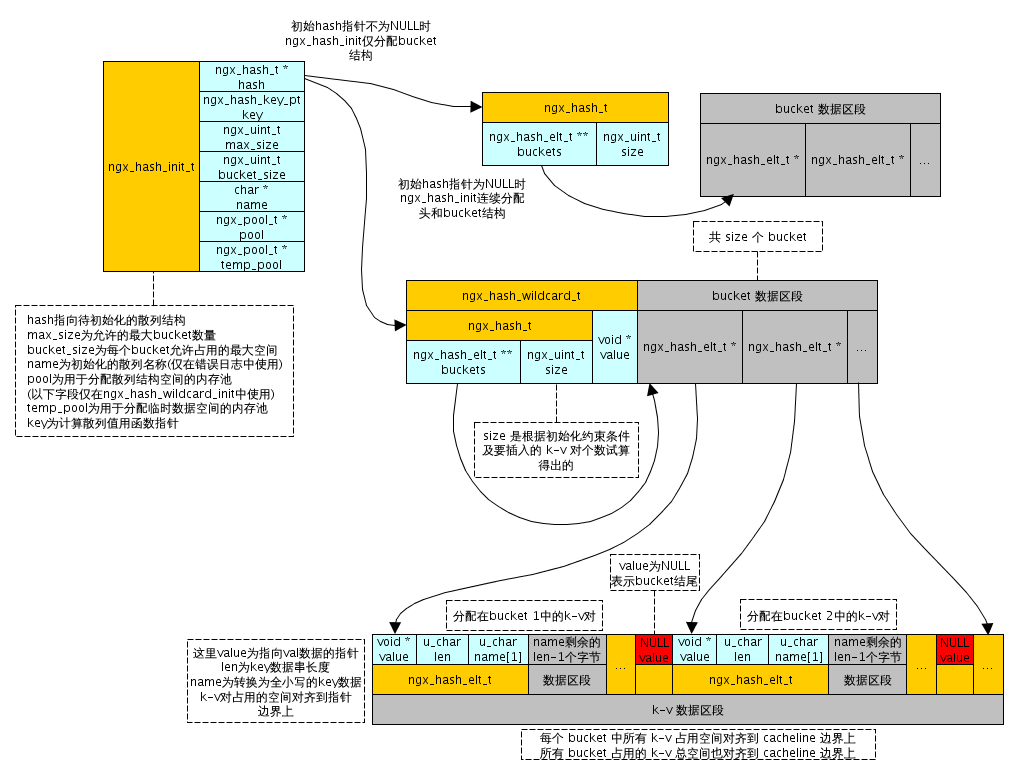
下面就注释下ngx_hash_init函数吧
<!-- lang: cpp -->
/* names数组中有nelts个ngx_hash_key_t ,是要填充到hash表中的数据*/
ngx_int_t
ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
/*bucket_size为每个桶允许占用的最大空间,通过这个循环保证桶有足够空间
* 盛放至少一个ngx_hash_elt_t,另外ngx_hash_elt_t可看做变长结构,因为如图所示
* 紧挨其结构体之后仍然存放这name剩余的len-1个字节
* NGX_HASH_ELT_SIZE(&names[n])意思是
* 与names[n]对应的的ngx_hash_elt_t所需的空间*/
for (n = 0; n < nelts; n++) {
if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *))
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should "
"increase %s_bucket_size: %i",
hinit->name, hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
}
/*test中存放的是每个桶所需的空间*/
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL) {
return NGX_ERROR;
}
bucket_size = hinit->bucket_size - sizeof(void *);
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100) {
start = hinit->max_size - 1000;
}
/*size为桶个数,从start开始,当分配的桶个数合适时跳到found*/
for (size = start; size < hinit->max_size; size++) {
ngx_memzero(test, size * sizeof(u_short));
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
if (test[key] > (u_short) bucket_size) {
goto next;/*如果有个桶所需空间超过了允许最大值则增加桶的数量*/
}
}
goto found;
next:
continue;
}
/*桶数量已经最大,仍然有某个桶没有足够的空间盛放对应的项*/
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build the %s, you should increase "
"either %s_max_size: %i or %s_bucket_size: %i",
hinit->name, hinit->name, hinit->max_size,
hinit->name, hinit->bucket_size);
ngx_free(test);
return NGX_ERROR;
found:
/*此时size是合适的桶个数*/
for (i = 0; i < size; i++) {
test[i] = sizeof(void *);
}
/*桶个数定下后,test中是每个桶应分配的内存大小*/
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
len = 0;
/*循环结束后len中存放的是为所有的桶应分配的内存大小*/
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
/*每个桶对齐到cacheline边界上时所需的内存大小*/
test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size));
len += test[i];
}
/*这个地方图上有解释*/
if (hinit->hash == NULL) {
hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t)
+ size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL) {
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **)
((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t));
} else {
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL) {
ngx_free(test);
return NGX_ERROR;
}
}
/*所有桶所占空间的起始位置也要对齐到cacheline边界上*/
elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size);
if (elts == NULL) {
ngx_free(test);
return NGX_ERROR;
}
elts = ngx_align_ptr(elts, ngx_cacheline_size);
/*将buckets中的每个桶指针指向对应的桶空间首地址*/
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
for (i = 0; i < size; i++) {
test[i] = 0;
}
/*填充每个元素到对应的桶的对应位置*/
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
elt->value = names[n].value;
elt->len = (u_short) names[n].key.len;
ngx_strlow(elt->name, names[n].key.data, names[n].key.len);
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
/*每个桶的结尾是一值为NULL的指针*/
for (i = 0; i < size; i++) {
if (buckets[i] == NULL) {
continue;
}
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
/*把分配的buckets连接到hash上,并在hash->size中记录下桶的个数*/
hinit->hash->buckets = buckets;
hinit->hash->size = size;
return NGX_OK;
}
ngx_hash_key和ngx_hash_key_lc是实现的两个ngx_hash_key_pt,用来对字符串生成hash值,区别是后者计算的是字符串全部小写后的hash值。
至于还有个ngx_hash_wildcard_init,里面有递归调用,现在还迷糊着,先放着吧。。















 3214
3214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









