







狗年开工毫无工作心情,胡思乱想后决定爬取豆瓣上的一下信息打发时间,毕竟之前基本没接触过爬虫,还是挺感兴趣的。
Scrapy简介
首先简单介绍一下Scrapy爬虫框架,主要是架构方面,这方面能快速理解scrapy是如何工作的。
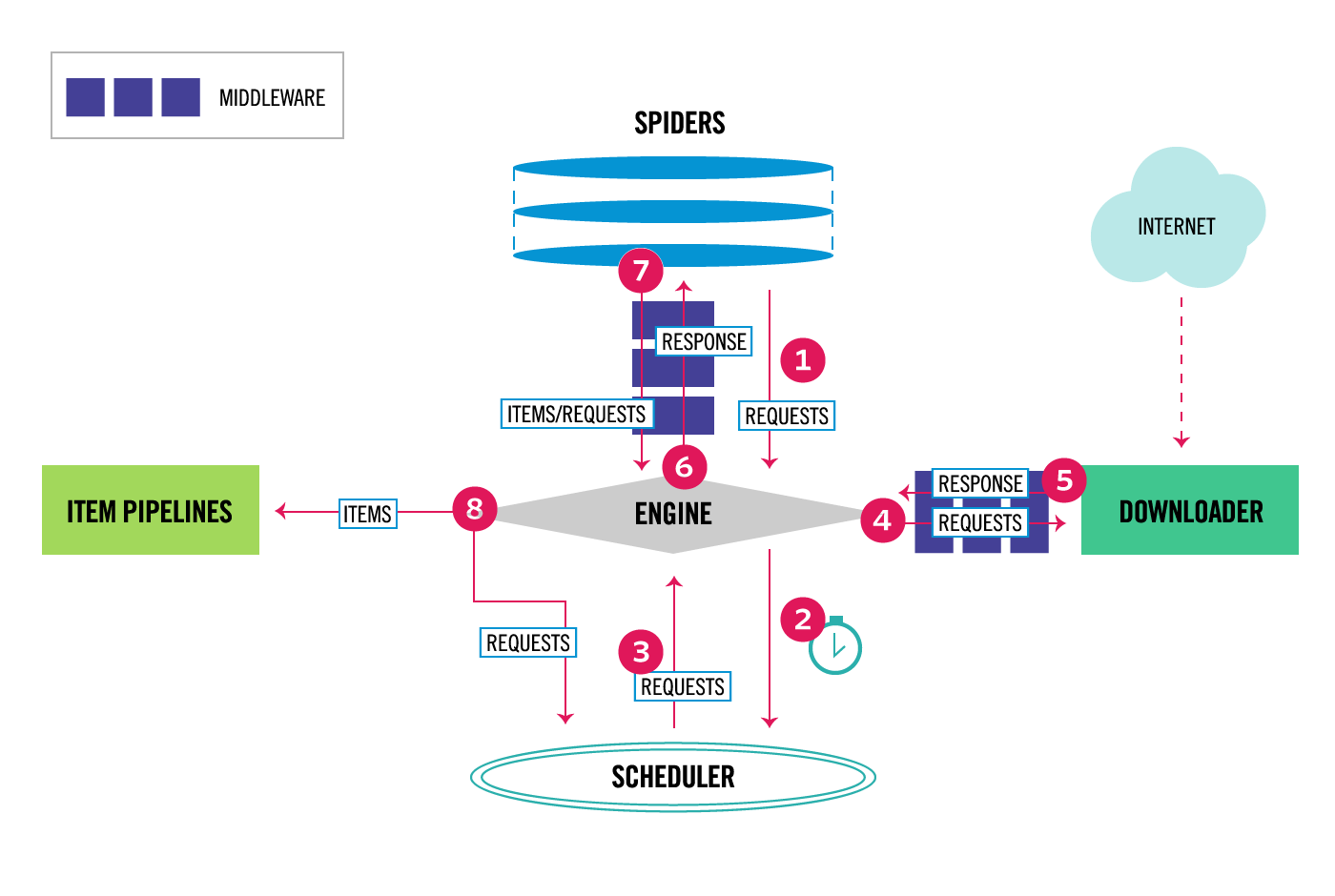
Scrapy的数据流由执行引擎(Engine)控制,其基本过程如下:
- 引擎从Spider中获取到初始Requests。
- 引擎将该Requests放入调度器,并请求下一个要爬取的Requests。
- 调度器返回下一个要爬取的Requests给引擎
- 引擎将Requests通过下载器中间件转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item交给ItemPipeline处理,将(Spider返回的)Request交给调度器,并请求下一个Requests(如果存在的话)。
- (从第一步)重复直到调度器中没有更多地Request。
使用Scrapy创建的项目架构如下
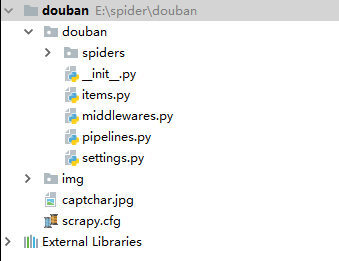
其中:
- spider 文件夹编写自己的爬虫;
- settings.py 配置爬虫的默认信息,功能开关,中间件执行顺序等;
- middlewares.py 中间件,主要是对功能的拓展,添加自定义功能,比如user-agent和proxy
- item.py 定义抓取处理的字段
- piplines.py 管道文件,处理item
爬取豆瓣小组
豆瓣小组的帖子主要核心内容是图片,因此要按不同的帖子分类下载。
settings.py
设置了user-agent,指定了中间件和piplines
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'douban (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'douban.middlewares.MyUserAgentMiddleware': 400,
}
COOKIES_ENABLES = True
DOWNLOAD_DELAY=1
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 1,
}
item.py
定义字段,包括作者,帖子名称,作者主页地址,图片地址
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
author=scrapy.Field()
author_homepage=scrapy.Field()
img_url=scrapy.Field()
pass
middlewares.py
设置user-agent
class MyUserAgentMiddleware(UserAgentMiddleware):
'''
设置User-Agent
'''
def __init__(self, user_agent, ip):
self.user_agent = user_agent
self.ip=ip
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('MY_USER_AGENT')
, ip=crawler.settings.get('PROXIES')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agentspiders/douban_spider.py
爬虫的处理代码,先登录然后爬取,如果有验证码,下载图片然后输入验证码
import urllib
import scrapy
from scrapy import Request, FormRequest
from douban.items import DoubanItem
import json
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = []
def start_requests(self):
yield Request("https://www.douban.com/login", callback=self.parse, meta={"cookiejar":1})
def parse(self, response):
captcha = response.xpath('//img[@id="captcha_image"]/@src').extract()
if len(captcha)>0:
print("此时有验证码")
localpath = "E:/spider/douban/captchar.jpg"
urllib.request.urlretrieve(captcha[0],filename=localpath)
print("请查看本地验证码图片并输入验证码")
captcha_value=input()
data = {
"form_email": "*******@126.com",
"form_password": "*******",
"captcha-solution": str(captcha_value),
"redir": "https://www.douban.com/group/haixiuzu/discussion?start=0" # 登录后要返回的页面
}
else:
print("此时没有验证码")
data = {
"form_email": "nofree1990@126.com",
"form_password": "8296926",
# "redir": "https://www.douban.com/group/haixiuzu/discussion?start=0" # 登录后要返回的页面
}
print("登陆中...")
yield FormRequest.from_response(response,meta={"cookiejar": response.meta["cookiejar"]}, formdata=data, callback=self.parse_redirect)
def parse_redirect(self, response):
print("已登录豆瓣")
title = response.xpath('//title//text()').extract()
baseurl='https://www.douban.com/group/haixiuzu/discussion?start='
for i in range(0, 625, 25):
pageUrl=baseurl+str(i)
yield Request(url=pageUrl, callback=self.parse_process,dont_filter = True)
def parse_process(self, response):
title = response.xpath('//title//text()').extract()
items = response.xpath('//td//a/@href').extract()
for item in items:
if 'topic' in item:
url=item
yield Request(url=item,callback=self.parse_img)
def parse_img(self,response):
img = DoubanItem()
title=response.xpath('//title//text()').extract()
img['title']=title
author=response.xpath('//div[@class="topic-doc"]//h3//a//text()').extract()
img['author']=author
author_homepage = response.xpath('//div[@class="topic-doc"]//h3//a/@href').extract()
img['author_homepage'] = author_homepage
img_url = response.xpath('//div[@class="image-wrapper"]//img/@src').extract()
img['img_url'] = img_url
yield img
piplines.py
在此保存帖子信息,没有使用自带的保存图片的类主要原因是不够灵活。
class DoubanPipeline(object):
def process_item(self, item, spider):
author=item["author"][0]
title=item["title"][0].replace('\n','').strip()
author_homepage=item["author_homepage"][0]
#路径
dir="E:/spider/douban/img/"
if not os.path.exists(dir):
os.mkdir(dir)
author_dir=dir+title
if not os.path.exists(author_dir):
os.mkdir(author_dir)
#用户信息txt
info=open(author_dir+"/用户信息.txt", "w")
info.write(author+'\n'+author_homepage)
info.close()
#保存图片
count=1
for url in item["img_url"]:
path=author_dir+"/"+str(count)+".jpg"
urllib.request.urlretrieve(url, filename=path)
count += 1
return item
爬虫结果
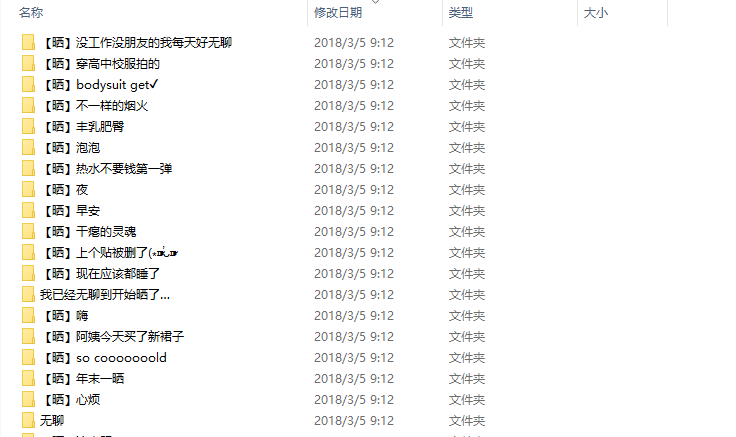
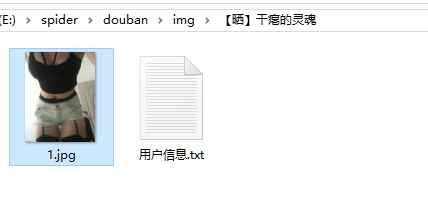
遇到的问题
主要问题就是爬取太频繁而被禁止,登录豆瓣也是想减少被禁止概率,但是发现没什么用。网上有很多解决方案,还是要伪造一些user-agent,使用proxy代理。也爬取过一些proxy存到数据库中,但是proxy比较慢,遂放弃。















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









