







1.wordcount示例开发
map阶段:将每行文本数据变成<单词,1>这样的k,v数据
reduce阶段:将相同单词的一组kv数据进行聚合,累加所有的v
1.1注意事项
mapreduce程序中:
1.map阶段的进,出数据
2.reduce阶段的进,出数据
类型都应该是实现了Hadoop序列化框架类型
比如:String对应Text;Integer对应IntWritable;Long对应LongWritable1.2wordcount程序整体运行流程示意图
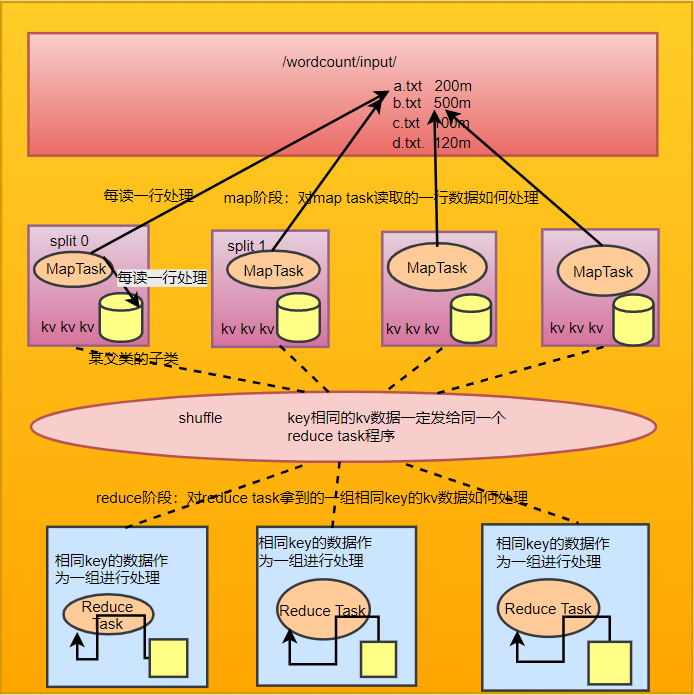
2.yarn的基本概念
yarn是一个分布式程序的运行调度平台
yarn中有两大核心角色:
1、Resource Manager
接受用户提交的分布式计算程序,并为其划分资源
管理、监控各个Node Manager上的资源情况,以便于均衡负载
2、Node Manager
管理它所在机器的运算资源(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器、回收资源
2.1.YARN的安装
node manager在物理上应该跟data node部署在一起
resource manager在物理上应该独立部署在一台专门的机器上
2.2修改配置文件
参考官网:https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
cd /root/apps/hadoop-2.7.2/etc/hadoop
vi yarn-site.xml2.3在<configuratiomn></configuration>里面添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>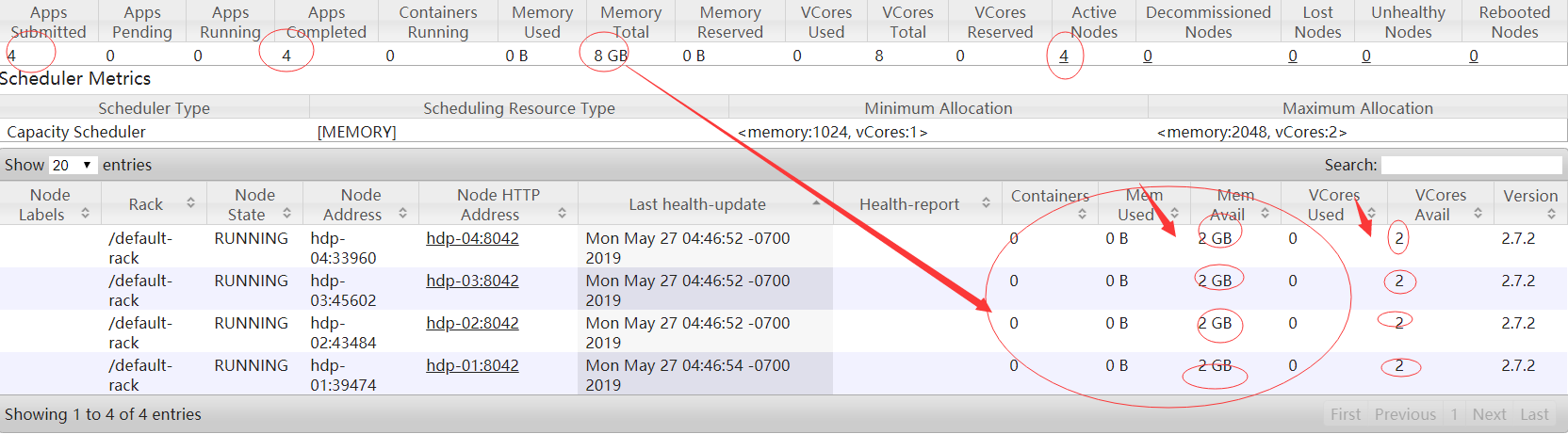
2.4拷贝配置文件到其它节点上
scp yarn-site.xml hdp-02:$PWD
scp yarn-site.xml hdp-03:$PWD
scp yarn-site.xml hdp-04:$PWD3.启动和停止hdfs集群和yarn集群命令
1.hdfs:
stop-dfs.sh:停止配置的namenode datanode
start-dfs.sh:启动namenode datanode
2.yarn:
start-yarn.sh:启动resourcemanager和nodemanager(注:该命令应该在resourcemanager所在的机器上执行)
stop-yarn.sh:停止resourcemanager和nodemanager4.其它命令
jps查看ResourceManager进程号
netstat -nltp | grep 进程号
8088是网页的
free -m:查看还剩多少内存5.编码实现
1.WordcountMapper类开发
2.WordcountReducer类开发
3.JobSubmitter客户端类开发
5.1.WordcountMapper类开发
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 1.KEYIN:是map task读取到的数据的key的类型,是一行的起始偏移量Long
* 2.VALUEIN:是map task读取到的数据的value的类型,是一行的内容String
* 3.KEYOUT:是用户的自定义map方法要返回的结果kv数据的key类型,在
* word count逻辑中,返回单词String
* 4.VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value类型,
* 在word count逻辑返回Integer
*
* 但是在mapreduce中,map 产生的数据需要传输给reduce,需要进行序列化和反序列化,
* 而Jdk 中的原生序列化机制产生的数据比较冗余就会导致数据在mapreduce运行过程比
* 较慢,Hadoop专门设计了自己序列化机制,那么,mapreduce 中传输的数据的数据类型
* 就必须实现Hadoop自己的序列化接口
* Hadoop为jdk 中常用的基本类型Long,String,Integer,Float等数据类型封装了自己
* 的实现Hadoop序列化接口类型:LongWritable,Text(String),IntWritable..
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1.切单词
String line = value.toString();
String[] words = line.split(" ");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
5.2.WordcountReducer类开发
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* 1.前面的Text,IntWritable:表示接收到map传过来的参数
* 2.后面的Text, IntWritable:表示Reduce返回的数据类型
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//idea快捷键(ctrl+o)查看重写的方法
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count=0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
}5.3.JobSubmitter客户端类开发
/**
* 用于提交MapReduce的客户端程序
* 功能:
* 1,封装本次job运行时所需要的必要参数
* 2.跟yarn进行交互,将mapreduce 程序成功的启动,运行
*/
public class JobSubmitter {
public static void main(String[] args)throws Exception {
//在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
//1.设置job运行时默认要访问的文件系统
conf.set("fs.defaultFS","hdfs://hdp-01:9000");
//2.设置job提交到哪里去运行(放本地local,这里放在yarn上运行)
conf.set("mapreduce.framework.name","yarn");
//3.指定位置
conf.set("yarn.resourcemanager.hostname","hdp-01");
//4.如果需要在Windows系统运行这个job提交客户端程序,则需要加这个跨平台提交参数
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//1.封装参数:jar包所在的位置
job.setJar("d:/wc.jar");
//动态获取jar包在哪里
//job.setJarByClass(JobSubmitter.class);
//2.封装参数:本次job所要调用的mapper实现类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//3.封装参数:本次job的Mapper实现类产生的数据key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//4.封装参数:本次Reduce返回的key,value数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
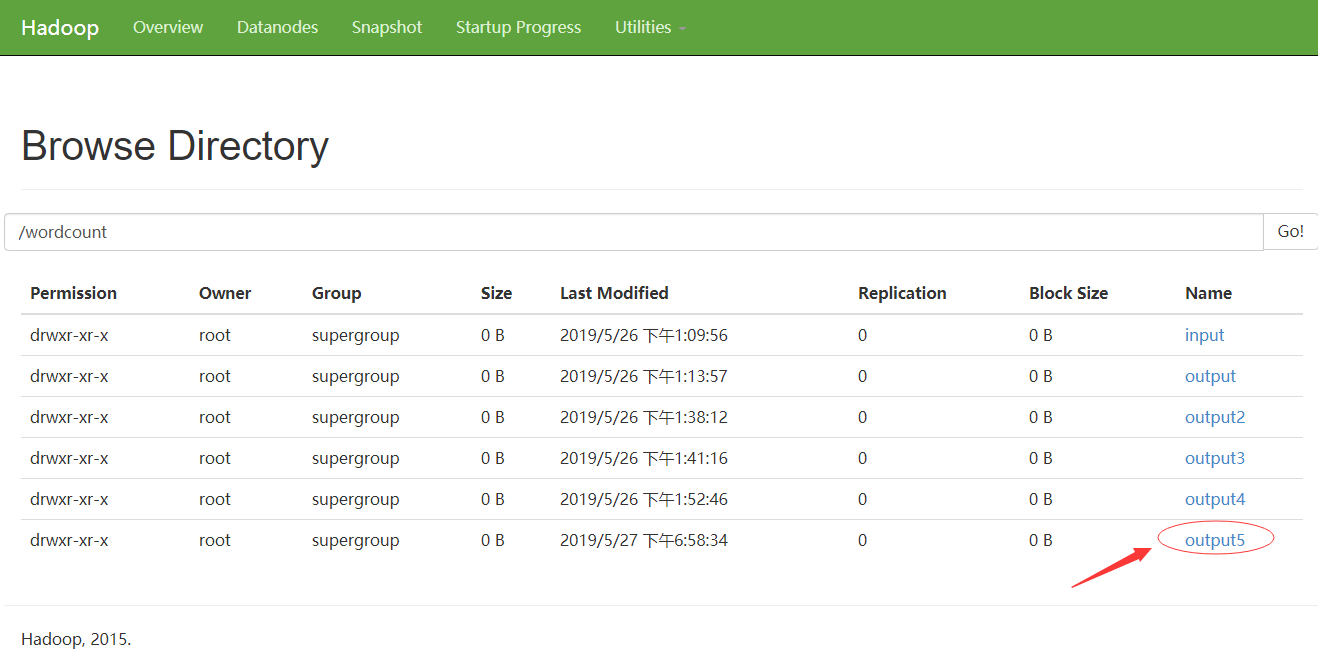
Path output=new Path("/wordcount/output5");
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root");
if(fs.exists(output)){
fs.delete(output,true);
}
//5.封装参数:本次job要处理的输入数据集所在路径,最终结果的输出路径
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job,output);
//6.封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(2);
//7.向yarn提交本次job
//job.submit();
//等待任务完成,把ResourceManage反馈的信息打印出来
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:-1);
}
}5.4.pom依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.1</version>
</dependency>
</dependencies>5.5.运行mapreduce程序
1.将工程整体打成一个jar包并上传到linux机器上,
2.准备好要处理的数据文件放到hdfs的指定目录中
3.用命令启动jar包中的Jobsubmitter,让它去提交jar包给yarn来运行其中的mapreduce程序 : hadoop jar wc.jar cn.xuyu.JobSubmitter .....
4.去hdfs的输出目录中查看结果
5.6.测试说明
本次测试在Windows环境,所以需要打成jar包,改名为wc.jar放在本地D:/盘目录下5.7.运行结果
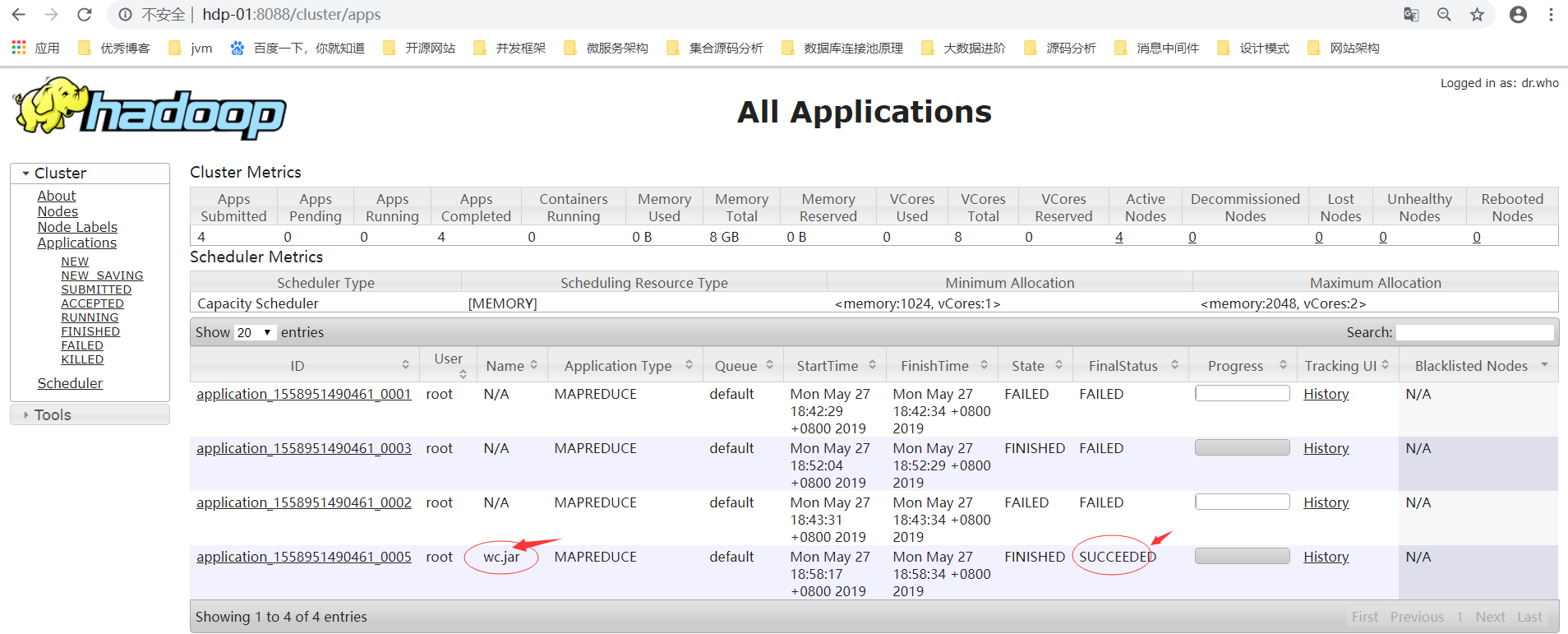
5.7.1.访问:http://hdp-01:8088/cluster/apps
5.7.2.访问:http://hdp-01:50070/explorer.html#/wordcount
5.7.3.命令行输入命令查看统计结果
[root@hdp-01 ~]# hadoop fs -ls /wordcount/output
Found 1 items
-rw-r--r-- 2 root supergroup 59 2019-05-25 22:13 /wordcount/output/res .dat
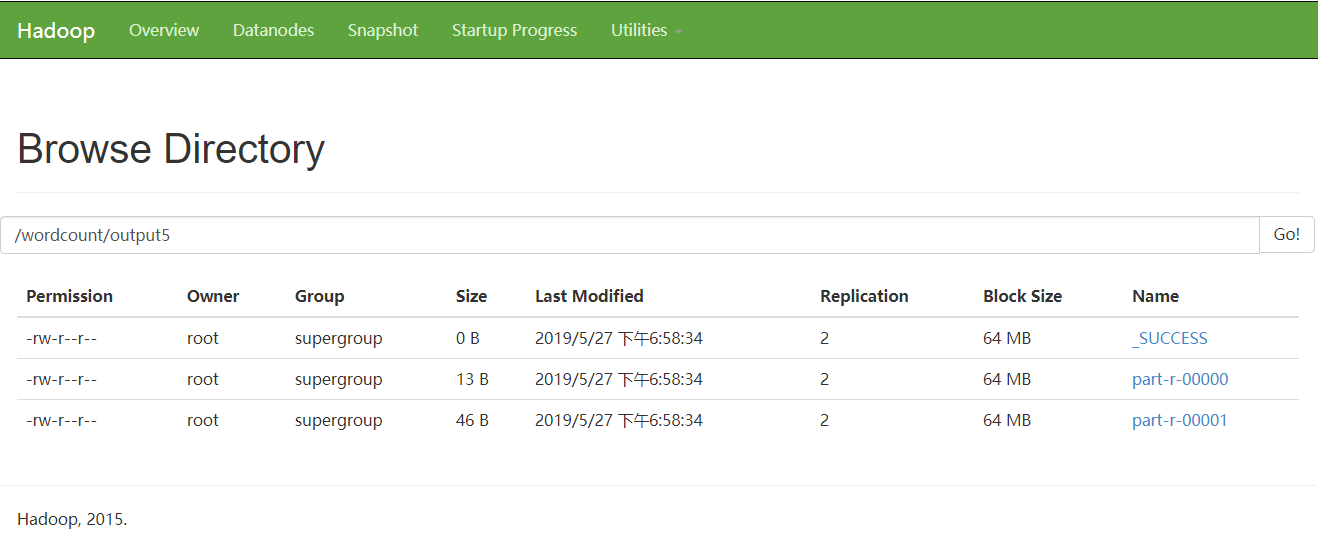
[root@hdp-01 ~]# hadoop fs -ls /wordcount/output5
Found 3 items
-rw-r--r-- 2 root supergroup 0 2019-05-27 03:58 /wordcount/output5/_S UCCESS
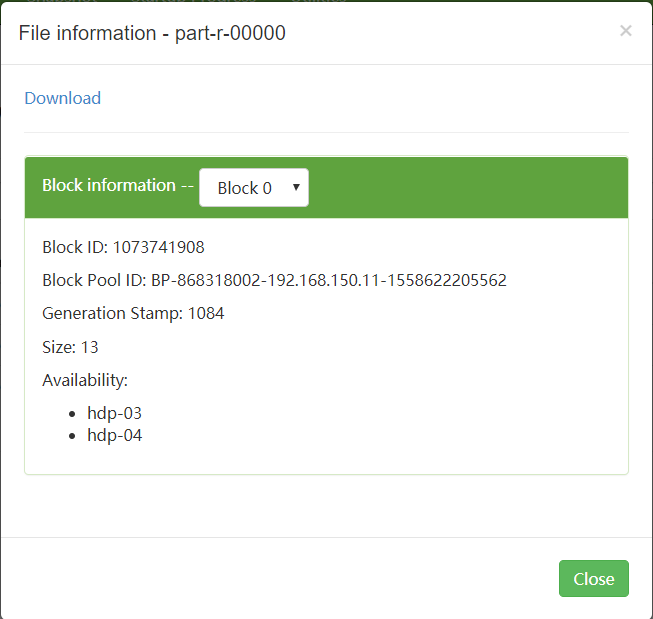
-rw-r--r-- 2 root supergroup 13 2019-05-27 03:58 /wordcount/output5/pa rt-r-00000
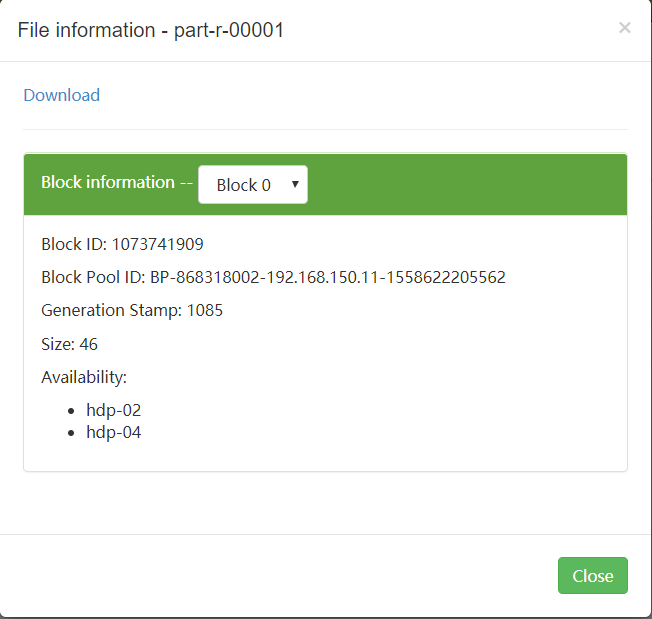
-rw-r--r-- 2 root supergroup 46 2019-05-27 03:58 /wordcount/output5/pa rt-r-00001
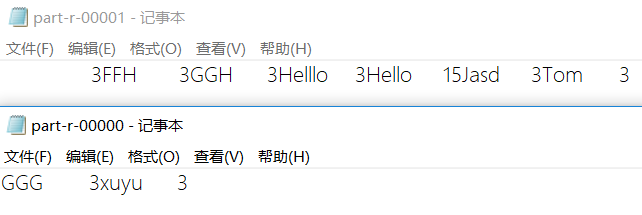
[root@hdp-01 ~]# hadoop fs -cat /wordcount/output5/part-r-00001
3
FFH 3
GGH 3
Helllo 3
Hello 15
Jasd 3
Tom 3
[root@hdp-01 ~]# hadoop fs -cat /wordcount/output5/part-r-00000
GGG 3
xuyu 3
5.7.4.在浏览器中查看内容
5.7.5.下载下来可以看到如下内容
6.在Linux环境测试
6.1需要去修改JobSubmitter 代码:如下
/**
* 用于提交MapReduce的客户端程序
* 功能:
* 1,封装本次job运行时所需要的必要参数
* 2.跟yarn进行交互,将mapreduce 程序成功的启动,运行
*说明:
* 如果要在hadoop集群的某台机器上启动这个job提交客户端的话
* conf里面就不需要指定 fs.defaultFS mapreduce.framework.name
* 因为在集群机器上用 hadoop jar springboot-hdp-a-1.0-SNAPSHOT.jar com.xuyu.mapreduce.JobSubmitter 命令来启动客户端main方法时,
* hadoop jar这个命令会将所在机器上的hadoop安装目录中的jar包和配置文件加入到运行时的classpath中
*
* 那么,我们的客户端main方法中的new Configuration()语句就会加载classpath中的配置文件,自然就有了
* fs.defaultFS 和 mapreduce.framework.name 和 yarn.resourcemanager.hostname 这些参数配置
*/
public class JobSubmitter {
public static void main(String[] args)throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//动态获取jar包在哪里
job.setJarByClass(JobSubmitter.class);
//2.封装参数:本次job所要调用的mapper实现类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//3.封装参数:本次job的Mapper实现类产生的数据key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//4.封装参数:本次Reduce返回的key,value数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path output=new Path("/wordcount/output5");
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root");
if(fs.exists(output)){
fs.delete(output,true);
}
//5.封装参数:本次job要处理的输入数据集所在路径,最终结果的输出路径
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job,output);
//6.封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(3);
//7.向yarn提交本次job
//job.submit();
//等待任务完成,把ResourceManage反馈的信息打印出来
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:-1);
}
}
6.2需要重新打包发布到Linux虚拟机上
这里上传到hdp-04这台虚拟机上
进入目录:cd /root/apps/hadoop-2.7.2/etc/hadoop
修改配置文件名字:mv mapred-site.xml.template mapred-site.xml编辑配置:vi mapred-site.xml
加入这些配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</name>
</property>运行程序:
hadoop jar springboot-hdp-1.0-SNAPSHOT.jar com.xuyu.mapreduce.JobSubmitter
6.3效果展示
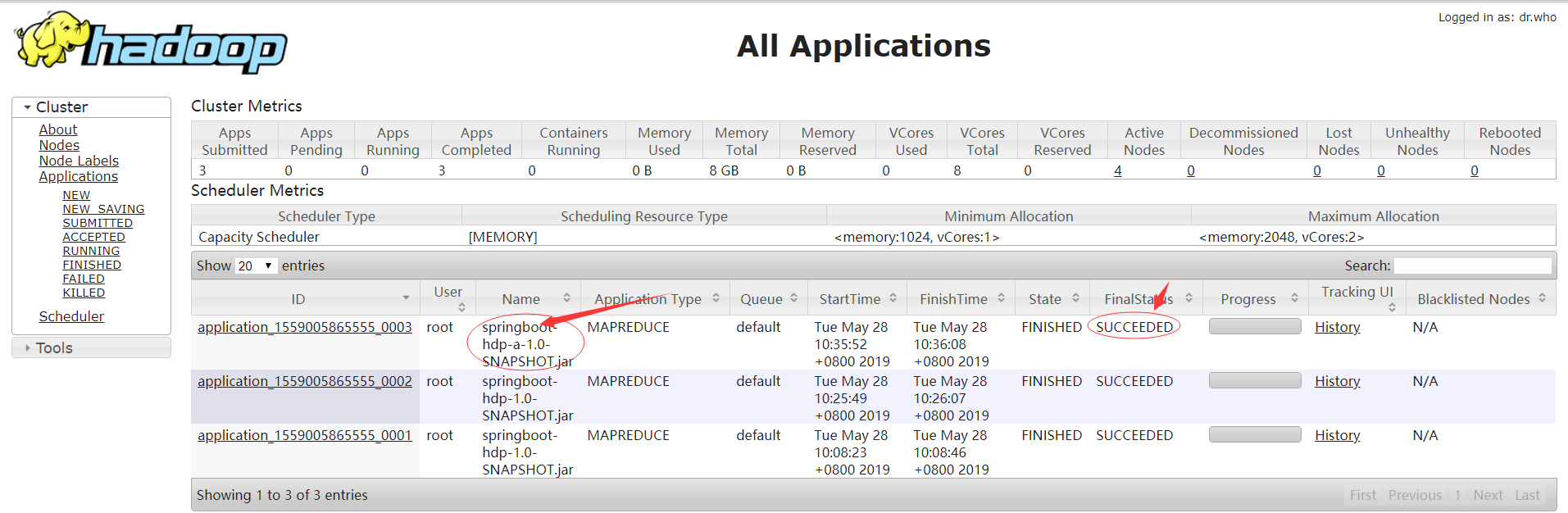
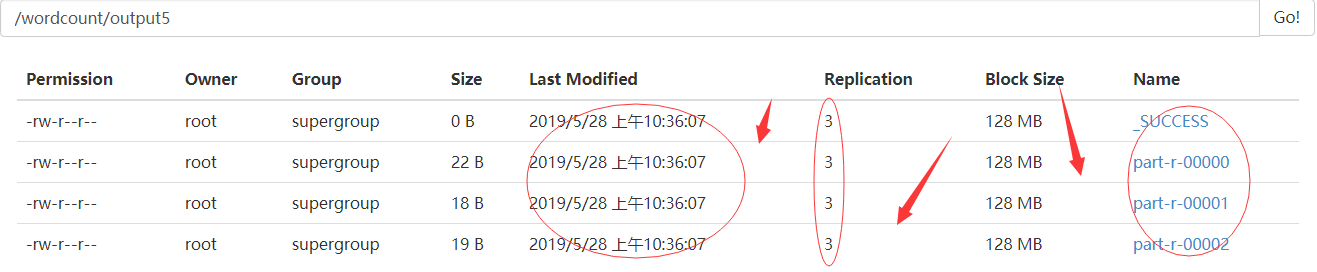
7.如果直接在windows上运行,进行测试代码修改如下
import com.xuyu.mapreduce.WordcountMapper;
import com.xuyu.mapreduce.WordcountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobSubmitterWindowsLocal {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS", "file:///");
//conf.set("mapreduce.framework.name", "local");
Job job = Job.getInstance(conf);
job.setJarByClass(JobSubmitterWindowsLocal.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("f:/mrdata/wordcount/input"));
FileOutputFormat.setOutputPath(job, new Path("f:/mrdata/wordcount/output1"));
job.setNumReduceTasks(3);
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
版权@须臾之余https://my.oschina.net/u/3995125















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









