






前言
在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误。我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了。因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题。
说明: 遇到的问题以及相应的解决办法是对于个人当时的环境,具体因人而异。如果碰到同样的问题,本博客的方法无法解决您的问题,请先检查环境配置问题。
Hadoop伪分布式相关的问题
1,FATAL conf.Configuration: error parsing conf hdfs-site.xml
原因: 字符编码问题。
解决办法: 统一编码,将文件打开,另存为统一编码,如UTF-8 即可。
2,Use of this script to execute hdfs command is deprecated。
原因:hadoop版本问题,命令过时。
解决办法: 将hadoop命令改成hdfs。
3,org.apache.hadoop.hdfs.server.namenode.NameNode。
原因:没有指定路径
解决办法:修改hadoop-env.sh文件。安装的hadoop路径是“/usr/local/hadoop/hadoop-2.8.2”, 在此路径下执行 vim etc/hadoop/hadoop-env.sh 在文件最后面添加 export HADOOP_PREFIX=/usr/local/hadoop/hadoop-2.8.2 ,并保存。
Hadoop相关的错误
1,启动hadoop时候报错:localhost: ssh: Could not resolve hostname localhost: Temporary failure in name resolution”
原因: hadoop的环境没有配置好,或者没有使配置生效。
解决办法: 如果没有配置Hadoop的环境变量,就填加配置。
例如:
export JAVA_HOME=/opt/java/jdk
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin然后使配置文件生效
输入:
source /etc/profile2,mkdir: `/user/hive/warehouse': No such file or directory
原因: 使用hadoop新建目录的时候报错,命名格式有问题
解决办法: 输入正确的命令格式
例如:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse3,bash:...: is a directory
原因:可能是/etc/profile 配置未能成功配置
解决办法: 确认配置文件没有问题之后,发现环境变量后面多了空格,将环境变量后面的空格去掉之后就好了。
4,Hadoop警告:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己编译64位的版本。
解决办法:
1.编译64位版本的lib包,可以使用这个网站提供的编译好的http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 。
- 将这个解压包解压到 hadoop/lib和hadoop/lib/native 目录下。
- 设置环境变量,在/etc/profile中添加
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" - 输入 hadoop checknative –a 检查
参考:
http://blog.csdn.net/jack85986370/article/details/51902871
5,hadoop成功配置之后,namenode没有成功启动。
原因:可能是hadoop的集群的配置不正确
解决方案: 检查hadoop/ etc/hadoop 的主要配置文件是否正确配置。
Spark相关的错误
1,使用spark sql的时候报错:javax.jdo.JDOFatalInternalException: Error creating transactional connection factory
原因:可能是没有添加jdbc的驱动
解决办法: Spark 中如果没有配置连接驱动,在spark/conf 目录下编辑spark-env.sh 添加驱动配置
例如:
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/spark/spark2.2/jars/mysql-connector-java-5.1.41.jar或者在spark目录下直接加载驱动
例如输入:
spark-sql --driver-class-path /opt/spark/spark2.2/jars/mysql-connector-java-5.1.41.jar2, spark-sql 登录日志过多
原因: spark的日志级别设置为了INFO。
解决办法:
将日志级别改成WARN就行了。
进入到spark目录/conf文件夹下,此时有一个log4j.properties.template文件,我们执行如下命令将其拷贝一份为log4j.properties,并对log4j.properties文件进行修改。
cp log4j.properties.template log4j.properties
vim log4j.properties将
log4j.rootCategory=INFO, console改成
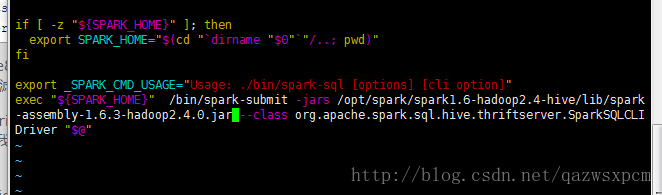
log4j.rootCategory=WARN, console3,spark sql启动报错:org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
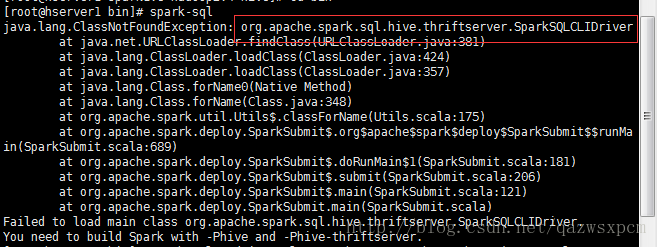
在spark/bin 目录下 修改spark-sql ,添加蓝色的字体的内容。
export _SPARK_CMD_USAGE="Usage: ./bin/spark-sql [options] [cli option]"
exec "${SPARK_HOME}" /bin/spark-submit -jars /opt/spark/spark1.6-hadoop2.4-hive/lib/spark-assembly-1.6.3-hadoop2.4.0.jar --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"
HBase 相关的错误
1,启动HBase错误: -bash: /opt/hbase/hbase-1.2.6/bin: is a directory
原因:未输入正确的命令,或者Hadoop未能正确运行
解决办法:
首先检查命名格式是否正确,然后检查Hadoop是否成功运行。
2,Java API 连接HBase 报错
org.apache.hadoop.hbase.client.RetriesExhaustedException: Failed after attempts=36, exceptions:
Tue Jul 19 16:36:05 CST 2016, null, java.net.SocketTimeoutException: callTimeout=60000, callDuration=79721: row 'testtable,,' on table 'hbase:meta' at region=hbase:meta,,1.1588230740, hostname=ubuntu,16020,1468916750524, seqNum=0
原因:可能是使用了主机名进行连接,而未载windows系统的hosts文件进行配置。
解决办法:
1.确认本地和集群服务之间的通信没有问题。
2.修改 C:\Windows\System32\drivers\etc\hosts 的文件,添加集群的主机名和IP做映射。
例如:
192.169.0.23 master
192.169.0.24 slave1
192.169.0.25 slave2
Hive相关的错误
1,hive2: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
原因: 无法连接元数据库,可能没有初始化元数据
解决办法:初始化元数据
输入: schematool -dbType mysql -initSchema
然后在输入: hive
2,进入hive警告:Class path contains multiple SLF4J bindings
原因:日志文件冲突。
解决办法: 移除其中的一个架包就可以了。
例如:移除hive或hadooop相关的一个slf4j.jar就可以;
3,java连接hive报错:HIVE2 Error: Failed to open new session: java.lang.RuntimeException:org.apache.hadoop.ipc.RemoteExc
原因:没有设置远程连接权限。
解决方案:在hadoop/conf/core-site.xml 中添加如下部分,重启服务即可:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>4,java连接hive报错:hive:jdbc connection refused
原因:可能hive未启动或者配置未能正确配置
解决办法:
1.查看服务是否启动
输入:
netstat -anp |grep 100002.查看hive / conf/hive-site.xml配置是否正确,是否添加了这些配置
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>注: master是我配置主机的名称,可以替换成主机的IP。
3.确认配置没有问题之后,输入hive --service hiveserver2 之后,在使用java连接测试。
5,使用hive警告:WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist
原因: Hive的这个配置在1.0之后就废除了。
解决办法:
在hive / conf/hive-site.xml 去掉这个配置就行了
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property> 6,Hive On Spark报错:Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Iterable
原因:缺少spark编译的jar包
解决办法:
我是使用的spark-hadoop-without-hive 的spark,如果使用的不是这种,可以自行编译spark-without-hive。
1.将spark/lib 目录下的spark-assembly-1.6.3-hadoop2.4.0.jar 拷贝到hive/lib目录下。
2.在hive/conf 中的hive-env.sh 设置该jar的路径。
注:spark-assembly-1.6.3-hadoop2.4.0.jar 架包在spark-1.6.3-bin-hadoop2.4-without-hive 解压包中.
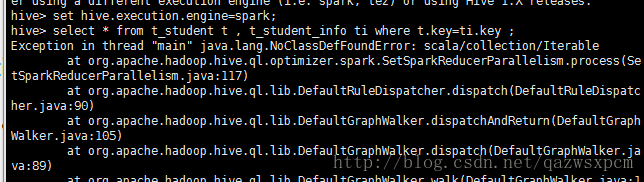
下载地址:http://mirror.bit.edu.cn/apache/spark
7, hive 使用spark引擎报错:Failedto execute spark task, with exception'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create sparkclient.)
原因:在使用Hive on Spark 执行查询命令的时候,出现这个错误。
解决办法:
1.检查hive和spark的版本是否正确,如果不相匹配,则配置相匹配的版本。
2.编辑hive/conf 目录下的hive-site.xml 文件,添加
<property>
<name>spark.master</name>
<value>spark://hserver1:7077</value>
</property>8,初始化hive元数据报错:Error: Duplicate key name 'PCS_STATS_IDX' (state=42000,code=1061)
原因:这可能是metastore_db文件夹已经存在;
解决办法: 删除该文件
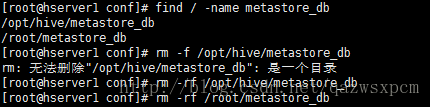
9,hive 初始化元数据库报错:
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : Access denied for user 'root'@'master' (using password: YES)
SQL Error code: 1045
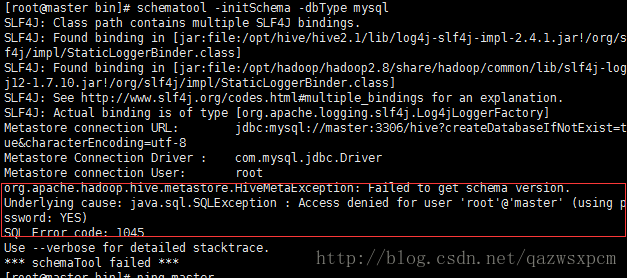
原因: 以为数据库连接用户名密码或权限问题,然而检查hive/hive-site.xml配置,和mysql设置的用户名和密码以及权限,都没问题。
解决办法: 将hive/hive-site.xml连接数据库的别名改成ip地址就可以了。
9,hive使用mr进行关联查询报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask
原因:内存太小了。
解决办法:将mr内存设置大一点
set mapred.reduce.tasks = 2000;
set mapreduce.reduce.memory.mb=16384;
set mapreduce.reduce.java.opts=-Xmx16384m;Zookeeper相关的错误
1,zookeeper集群启动之后输入status 报:Error contacting service. It is probably not running.
原因:可能是zoopkeeper集群未能成功配置以及相关的环境未配置好。
解决办法:
- 集群成功配置并且启动成功后,检查集群中的防火墙是否关闭;
2.检查myid和zoo.cfg文件配置格式是否正确,注意空格!!!
3.输入jps查看zookeeper是否成功启动。
4.zookeeper集群全部都启动成功之后,再输入zkServer.sh status 查看。
Zoo.cfg完整的配置
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888myid的配置为 1、2、3














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









