







- 并发与并行
- 传统并发有什么不好?
- 线程的调度
- 并发编程框架
- 线程实现模型
- C、C++等传统支持并发的方式有诸多不足
- pthread API
- go 调度器解决线程池的常见问题
并发与并行 (Concurrency and Parallelism)
并发
只是更符合现实问题本质的表达方式,最初目的是简化代码逻辑,而不是使程序运行的更快
可以通过以下方式做到:
- 显式定义并触发多个代码片段(逻辑控制流),由应用或os对它们进行调度
它们可以是独立无关的,也可以是相互依赖需要交互的
线程只是实现并发的其中一个手段,除此之外,运行库或是应用程序本身也有多种手段来实现并发
- 隐式放置多个代码片段,系统事件发生时执行相应的代码片段(事件驱动),如某个端口或管道收到数据(多路IO)、进程接收到了某个信号(signal)
并行
可以在四个层面上做到:
- 多台机器
- 多CPU(多颗CPU/多核/超线程),总之有了多个CPU流水线
- 单CPU核ILP(Instruction-level parallelism),指令级并行
复杂制造工艺和对指令的解析以及分支预测和乱序执行,单个时钟周期内执行多条指令,从而,即使是非并发的程序,也可能以并行的形式执行
- 单指令多数据(Single instruction, multiple data. SIMD),优化多媒体数据处理
1 牵涉分布式处理(数据的分布和任务的同步等),是基于网络
3、4 通常是编译器和CPU的开发人员需要考虑的
- 并行性是指两个或多个事件在同一时刻发生
- 而并发性是指两个或多个事件在同一时间间隔内发生
还能总结出
- 并行一定并发,并发不一定并行
- 单核计算机只能并发执行
这种经过一番推敲的答案
答案无疑是正确的,但却也不够完美。因为它只是从任务层级(task-level)上去描述这两个概念
硬件知识中有, 并行加法器,现代计算机在不同层次上都使用了并行技术
- 位级(bit-level)并行
32位计算机的运行速度比8位计算机更快?因为并行
对两个32位数的加法,8位计算机必须进行多次8位计算,而32位计算机可以一步完成
然而由位升级带来的性能改善是存在瓶颈的,短期内我们无法步入128位时代的原因
- 指令级(instruction-level)并行
现代 CPU 并行度很高,技术包括流水线、乱序执行和猜测执行等
尽管处理器内部的并行度很高,但是经过精心设计,从外部看上去所有处理都像是串行的
而这种“看上去像串行”的设计逐渐变得不适用。处理器的设计者们为单核提升速度变得越来越困难
多核时代必须面对的情况:无论是表面上还是实质上,指令都不再串行执行了。可以深入 “内存可见性”部分
- 数据级(data)并行
(“单指令多数据”,SIMD)架构,可以并行地在大量数据上施加同一操作。并不适合解决所有问题,但在适合的场景却可以大展身手
如图像处理,多媒体
为了增加图片亮度就需要增加每一个像素的亮度
- 任务级(task-level)并行
即使是单任务的情况下也是会存在并行的,广义上的并行和并发不存在子集关系
并发偏向于逻辑,并行更偏向于物理
传统并发有什么不好?
多线程,需要知道线程安全问题,然后去用锁,然后去查看是否有死锁/活锁
多进程,需要考虑进程通信问题
总之想要用并发去解决问题,反而会引入另一些问题
并发模型并没有改变依赖多线程/多进程的实质,只是提供了一种避免麻烦的手段
Actor 模型
Actor 可应用于共享内存架构和分布式内存架构,适合解决地理分布型的问题。同时还能提供很好的容错性
线程并发中,共享的可变状态会引入诸多麻烦 对此有许多解决方法,比如常见的锁,事务,函数式编程中则直接使用了不可变状态
而 Actor 模型允许可变状态,只是只通过消息传递的方式来进行状态的改变
Actor 模型由一个个 Actor 的执行体和 mailbox 组成
用户将消息发送给 Actor,实际上就是将消息放入一个队列中, 然后将其转交给处理被接受消息的一个内部线程。消息让 Actor 之间解耦
一个 Actor 收到其他 Actor 的消息后,会做出不同的行为,还可能会给其他 Actor 发送更进一步的消息
CSP 模型
与 Actor 模型类似,CSP 模型也是由独立的、并发执行的实体所组成,实体之间也是通过发送消息进行通信
但两种模型的差别是:CSP 模型不关注发送消息的实体,而是关注发送消息时使用的 channel
from threading import Thread
from queue import Queue
from time import sleep
def run_thread(func, *args, **kwargs):
t = Thread(target=func, args=args, kwargs=kwargs)
t.start()
return t
def work_for(channel):
while True:
cmd = channel.get()
if cmd == 'return':
return
print('Start working on {} ...'.format(cmd))
sleep(1)
print('Done')
if __name__ == '__main__':
channel = Queue()
for i in range(3):
run_thread(work_for, channel)
for i in range(6):
channel.put(i)
for i in range(3):
channel.put('return')
和平时利用 Queue 的多线程没有什么区别?的确,我们无意之间已经在使用 CSP 了
Golang 自身支持了CSP,通过 goroutine 的作为执行实体。实际上就是协程
package main
import "fmt"
var ch = make(chan string)
func message(){
msg := <- ch
fmt.Println(msg)
}
func main(){
go message()
ch <- "Hello World."
}
这两者是十分相近的概念,都着眼于消息传递,都使用了 channel/mailbox 这样的信道(队列)和 Actor/goroutine 这样的执行实体
Actor 模型将执行实体和 mailbox 进行了耦合,一个 Actor 用一个 mailbox
而 CSP 可以绑定多个 channel(类似发布者/订阅者模型)
CSP 中的 channel 通常是匿名的, 即任务放进 channel 之后你并不需要知道是哪个 channel 在执行任务
而 Actor 是有"身份"的,你可以明确的知道哪个 Actor 在执行任务
线程的调度(抢占式)
进程的意义是 隔离的执行环境
IA-32 CPU指令控制方式,如何在多个指令序列(逻辑控制流)间切换
CPU 通过 CS:EIP寄存器值确定下一条指令位置,但不允许直接用MOV指纹更改EIP的值,必须通过JMP、CALL/RET、或INT指令实现代码跳转
指令序列间切换时,除更改EIP,还要保证代码可能会使用到的各个寄存器值,尤其是栈指针SS:ESP,EFLAGS标志位等,都能够恢复到目标指令序列上次执行到这个位置时候的状态
内核与应用共享CPU,EIP在应用代码段时,内核并没有控制权
内核并不是一个进程或线程,只是以实模式运行的,代码段权限为RING 0的内存中的程序
产生中断或应用系统调用时,控制权才转到内核
内核里所有代码都在同一个地址空间,为给不同线程提供服务,内核会为每一个线程建立一个内核堆栈,这是线程切换的关键
线程调度
内核在合适时机对整个系统线程调度
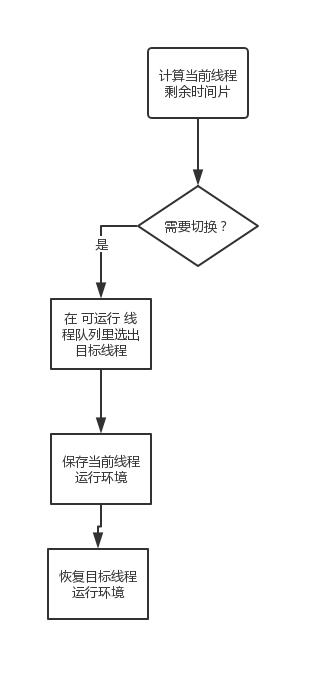
最重要就是切换堆栈指针ESP,再把EIP指向目标线程上次被移出CPU时的指令
现在每颗CPU有多个核 (processor core),每个核又可以支持超线程 (是逻辑处理器)
逻辑处理器有自己一套完整的寄存器,包括CS:EIP和SS:ESP
以os和应用的角度来看,每个逻辑处理器都是一个单独的流水线
同一个核上两个超线程共享L1/L2缓存
有NUMA支持的场景里,每个核访问内存不同区域的延迟是不一样的,多核场景里的线程调度又引入了“调度域”(scheduling domains)的概念
中断发给哪个CPU
- 软中断 (除以0,缺页异常,INT指令)该中断的CPU上产生
- 硬中断分两种,内部中断每CPU处理自己的,外部中断如IO,可以通过APIC指定其送给哪个CPU
因为调度程序只能控制当前的CPU,所以,如果IO中断没有进行均匀的分配的话,IO相关的线程就只能在某些CPU上运行,导致CPU负载不均,进而影响整个系统的效率
并发编程框架
代码片段(逻辑控制流)的调度和切换其实并不神秘
理论上,可以不依赖 os 和其提供的线程,在自己程序代码段里定义多个片段,然后程序里对其进行调度和切换
和内核的实现类似,只是不需要考虑中断和系统调用,我们的程序本质上就是一个循环,循环本身就是调度程序schedule()
- 维护一个任务列表
- 根据自定义策略(先进先出或/优先级等),每次从列表里挑选出一个任务,恢复各寄存器值
- JMP到该任务上次被暂停的地方,所需保存的信息都可作为该任务的属性,存放在任务列表里
线程实现模型
- 内核级线程模型
- 用户级线程模型
- 混合型线程模型
区别在线程与内核调度实体 KSE(Kernel Scheduling Entity) 之间对应关系
KSE 指可以被 os kernel 调度器调度的对象实体(或又可称 内核级线程),是 kernel最小调度单元
内核级线程模型
用户线程与KSE(1:1)
- linux pthread
- Java java.lang.Thread
- C++11 std::thread等线程库
都是对 os线程(内核级线程)的一层封装
创建出来的每个线程与一个不同的KSE静态关联,调度由OS调度器做
- 实现简单,直接借助OS提供的线程能力
- 不同用户线程间一般不相互影响
- 创建/销毁/线程间的上下文切换等 直接由OS亲自做,需要使用大量线程的场景下对OS的性能影响会很大
用户级线程模型
用户线程与KSE(M:1)
创建/销毁/协调等由 用户实现的线程库来负责,对OS内核透明
一个进程中所有创建的线程都与同一个KSE在运行时动态关联
可创建的数量与上下文切换所花费的代价小很多
致命的缺点
某用户线程上调用阻塞式系统调用(如用阻塞方式read网络IO),一旦KSE因阻塞被kernel调度出CPU的话,剩下所用户线程全阻塞(整个进程挂起)
所以协程库要
- 把自己一些阻塞的操作重新封装为非阻塞形式
- 然后在以前要阻塞的点上,主动让出自己
- 并通过某种方式通知或唤醒其他待执行的用户线程在该KSE上运行
从而避免了内核调度器由于KSE阻塞而做上下文切换,整个进程不被阻塞
混合型线程模型
用户线程与KSE(M:N)
一个进程创建多个KSE,且线程可与不同KSE在运行时进行动态关联
某个KSE由于其上工作的线程的阻塞操作被内核调度出CPU时,当前与其关联的其余用户线程可以重新与其他KSE建立关联关系(用户级代码实现,复杂) Go的并发就是这种实现方式
Go 的调度器负责 gorouting 与KSE的动态关联。又可称 两级线程模型
- 用户调度器 > 用户线程到KSE的“调度”
- 内核调度器 > KSE到CPU上的调度
C、C++等传统支持并发的方式有诸多不足
程序负责创建线程(一般通过pthread等lib调用实现),os负责调度
复杂
创建容易,退出难
创建一个thread(如用pthread)虽然参数也不少,但好歹可以接受
int pthread_create (pthread_t *thread,pthread_attr_t *attr,void *(*start_routine)(void *),void *arg)
涉及thread的退出就要考虑
- thread是detached,还是需要parent thread去join?
- 是否需要在thread中设置cancel point,以保证join时能顺利退出?
并发单元间通信困难,易错
thread之间的通信虽然有多种机制可选,但用起来是相当复杂;涉及到shared memory,就会用到各种lock,死锁便成为家常便饭
thread stack size的设定
用默认的,还是设置的大一些,或者小一些
难于scaling
-
thread代价已经比进程小了很多了,但依然不能大量创建thread,除了每个thread占用的资源不小之外,os调度切换thread的代价也不小
-
很多网络服务程序,不能大量创建thread,就要在少量thread里做网络多路复用:epoll/kqueue/IoCompletionPort,即便有libevent/libev这样的第三方库帮忙,写起这样的程序也是很不易的,存在大量callback,给程序员带来不小的心智负担
pthread API
结束线程
- 线程运行的函数return了
- pthread_exit
- 其他线程调用 pthread_cancel 结束这个线程
- 进程调用 exec() or exit()
- main() 函数先结束了,而且 main() 自己没有调用 pthread_exit 来等所有线程完成任务
对线程的阻塞
int pthread_join(pthread_t threadid, void **value_ptr)
pthread_detach (threadid)
pthread_attr_setdetachstate (attr,detachstate)
pthread_attr_getdetachstate (attr,detachstate)
堆栈管理
pthread_attr_getstacksize (attr, stacksize)
pthread_attr_setstacksize (attr, stacksize)
pthread_attr_getstackaddr (attr, stackaddr)
pthread_attr_setstackaddr (attr, stackaddr)
pthread_self ()
pthread_equal (thread1,thread2)
互斥锁
pthread_mutex_init (mutex,attr)
pthread_mutex_destroy (pthread_mutex_t *mutex)
pthread_mutexattr_init (attr)
pthread_mutexattr_destroy (attr)
phtread_mutex_lock(pthread_mutex_t *mutex)
phtread_mutex_trylock(pthread_mutex_t *mutex)
phtread_mutex_unlock(pthread_mutex_t *mutex)
pthread_mutexattr_init
pthread_mutexattr_destroy
pthread_mutexattr_getpshared
pthread_mutexattr_setpshared
pthread_mutexattr_getprotocol
pthread_mutexattr_setprotocol
pthread_mutexattr_setprioceiling
pthread_mutexattr_getprioceiling
条件变量
pthread_cond_wait (condition,mutex)
pthread_cond_signal (condition)
pthread_cond_broadcast (condition)
pthread_cond_destroy (condition)
pthread_condattr_init (attr)
pthread_condattr_destroy (attr)
Go scheduler
将goroutines放到不同的操作系统线程中去执行
在语言层面自带调度器,称原生支持并发
解决了一般线程池常见的问题
遇到阻塞或者同步动作时
- 怎么让线程池更容易扩展,不会因为其中一个任务的阻塞或者同步独占线程
- 甚至怎么避免由此问题带来的死锁
方式
发起的同步或者channel动作,哪怕网络操作 都会把自身goroutine切换出去让下一个预备好的goroutine去运行
GMP模型很容易的做到对线程池的扩展,尽可能的让线程保持在一个合适的数目















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









