







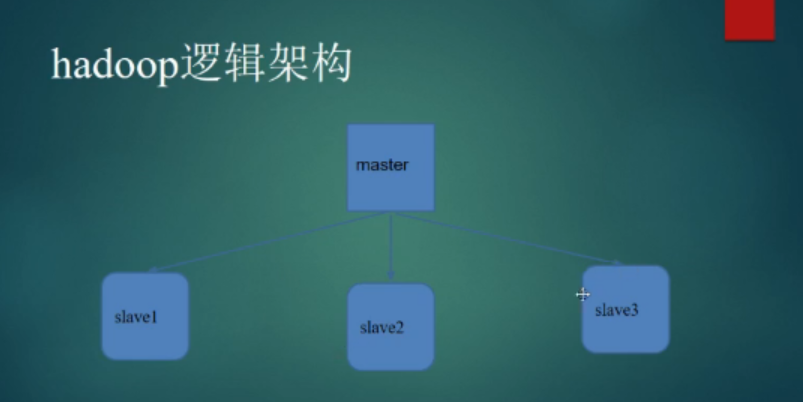
1.我们将搭建一个hadoop的基础集群
2.用VitrualBox安装服务器基础版的Centos7.
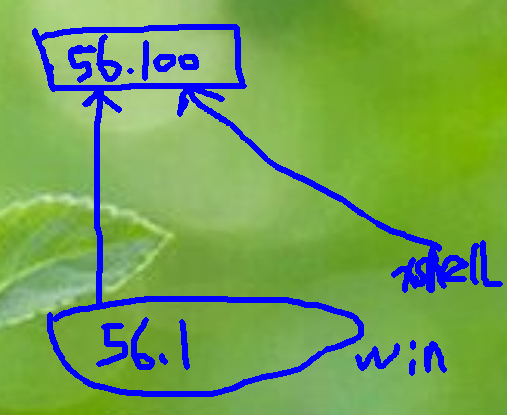
3.因为虚拟机需要设置为host-only,Win10对VirtualBox并不支持host-only的创建,该如何办呢?host-only是让虚拟机间可以通行,和宿主可以通信,一般和Internet隔离来保证安全。
4.56.100是电信机房的电脑,xshell将连接访问之。56.1是windows电脑。win8.1安装xftp时可能报异常丢失nslicense.dll,暂未解决?
5.配置文件修改
a.设置ip:/etc/sysconfig/network-scripts/ifcfg-enp0s3
TYPE=Ethernet
IPADDR=192.168.56.100
NETMASK=255.255.255.0
b.设置网关:/etc/sysconfig/network
NETWORKING=yes
GATEWAY=192.168.56.1
hostnamectl set-hostname master
systemctl restart network
ping 192.168.56.1测试连接成功,windows中ping 192.168.56.100测试成功。
c.如果想让虚拟机也可以上网,共享internet,那就设置为共享的192.168.137.1网段的信息。并将虚拟机的网段也统一到192.168.137.1网段内,就可以相互通信,并且上internet网了。配合dns服务器时,简单的方式是:echo "nameserver 114.114.114.114">> /etc/resolv.conf ,网上找时候看了一堆,有点复杂。
6.然后用xshell进行登录,通过xftp上传hadoop,jdk上传到linux的/usr/local机器上。
7.rpm -ivh jdkxxx.rpm 安装jdk。tar -xvf hadoop.xx.zip
8.配置hadoop运行jdk环境。/usr/local/hadoop/etc/hadoop/hadoop-env.sh ,因为会用到jdk功能。
9.hadoop执行命令的路径加到我们的path变量的路径里,这样那个目录下面都可以执行hadoop命令。/etc/profile,export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin,/source/profile。
10.测试安装jdk,hadoop成功后,然后我们复制虚拟机。不可能重复新再安装一遍吧。
12.然后将slave1,2,3对应的ip修改为101,102,103,ping 192.168.56.1可以联通windows属主机。
13.host-only的好处是设置完ip可以保持不变。bridge是需要真实的IP,NAT每次启动IP可能变化。
14.最后启动4台机器,这是架构。
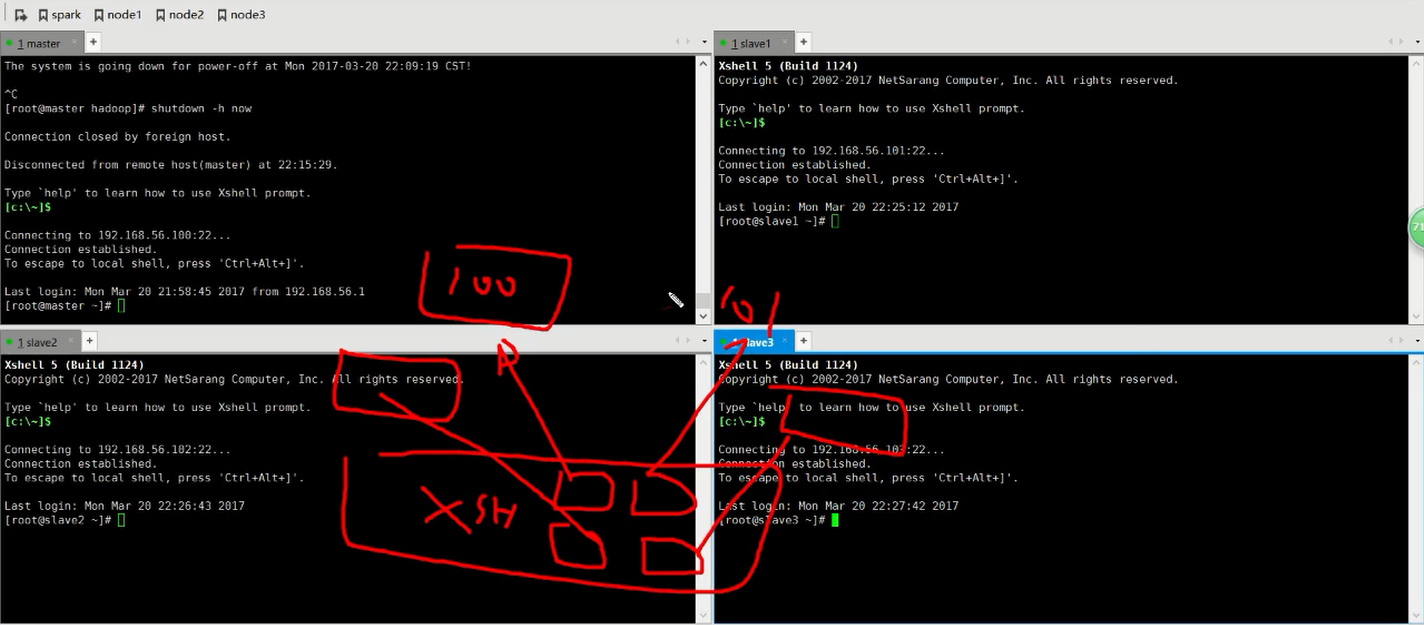
14.然后相互ping确认都可以互相通信后,停止并关闭所有机器的防火墙。systemctl stop firewalld;systemctl disable firewalld。
15.master是管理者,文件名及相关路径的记录者,datenode是数据存储的机器。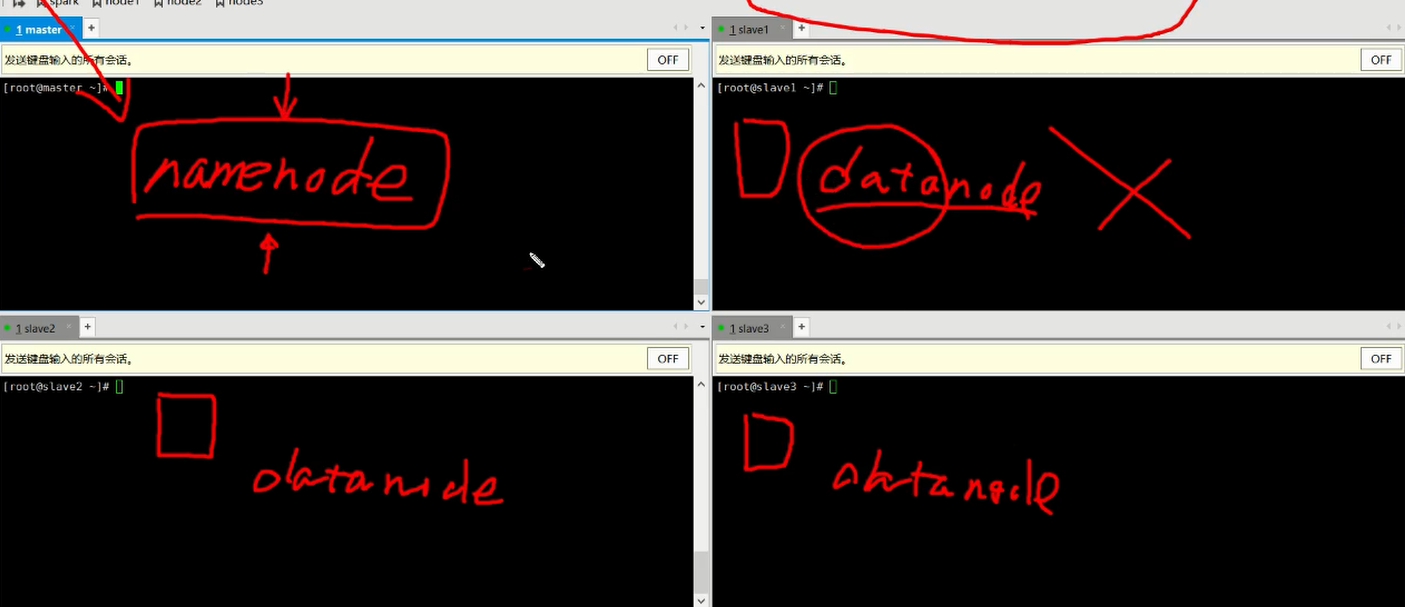
16.下面启动hadoop. 大家都要知道master是在那台机器上,core-site.xml是大家都要设置的:/usr/local/hadoop/etc/hadoop/core-site.xml。
17.我们用最基础简单的核心方法,再迭代的知识更新。
配置的信息:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
18.启动hadoop,master启动namenode,salve*启动datenode。
19. 修改让机器之间相互认识名字。/etc/hosts
内容:
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
20.内容存储格式化:hdfs namenode -format,注意是在/tmp下的。
21.master启动: hadoop-daemon.sh start namenode,jps后显示 NameNode,说明启动完毕。
22.datenode启动,hadoop-daemon.sh start datanode,jps显示datanode,说明启动完毕。
33.此时master管理着slave这些节点。并相互建立了联系。
总结:
1.市面上很多大数据课程都是集成了master脚本一下就配置和部署好相关机器的配置了,所以看着比较乱,我建议先把简单的搭起来,看看hadoop是个什么,写个简单的例子,慢慢就了解了。
2.xshell可以同步多发送命令很好用。
3.hadoop大概10个小时课程概念基本就建立起来了,mapreduce虽然什么都能干,但是别扭。实际工作中不常用,实际用hive,scalar,python来开发。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









