






本篇是这个系类的最后一篇,但优化方案不仅于此,需要后续的研究与学习,本篇主要从schema设计的角度来做一些实践。
schema.xml 这个文件的作用是定义索引数据中的域的,包括域名称,域类型,域是否索引,是否分词,是否存储,是否标准化,是否存储项向量等等。在solr6中这个文件是存放在zookeeper的/configs节点之下的,在创建新的collection时,solr会根据此节点下的信息生成相应的索引库,其相关的配置信息会同步到solrhome/core目录下的core.properties文件中。同步schema文件的指令语句样例为:
bin/solr zk -upconfig -z 127.0.01:2181 -n conf -d /solrhome/configsets/sample_techproducts_configs/conf为了改进性能,可以从以下几个方面来着手:
1、对于field元素,我们将所有只用于搜索的,而不需要作为查询结果的field(特别是一些比较大的field)的stored设置为false,这样这个字段的值将不会被存储,但可以被检索,会减少不小的IO开销。我们设计了一个利用solr来做hbase的二级索引架构,可以利用hbase来存储字段信息,充分利用hadoop的大数据特性。
2、能不用copyfield这个元素就不用,这个属性会对字段做双倍存储,显然非常耗性能,好处就是在查询的时候,想要对多个字段进行检索只需要检索一个字段。
3、将一些不需要被检索的字段的index属性,设置成false,这样solr就不会对这个字段进行索引。
5、不使用中文分词器或者使用高亮功能。termPositions termOffsets的值全都设置成false。
6、在测试中发现solr在处理小报文(1K以下)的情况下吞吐量并不理想,当适当增大报文,发现速度可以得到大幅度提高,可以从之前的每个节点10M/S暴涨到30M/S。
但是在很多情况下,我们并不能人为控制报文长度,这个时候,可以通过solr的字段多值来达到目的,即将将多条消息的每个字段的值放到一起,在schema中配置multValued为true。存储到solr中是这个样子的:
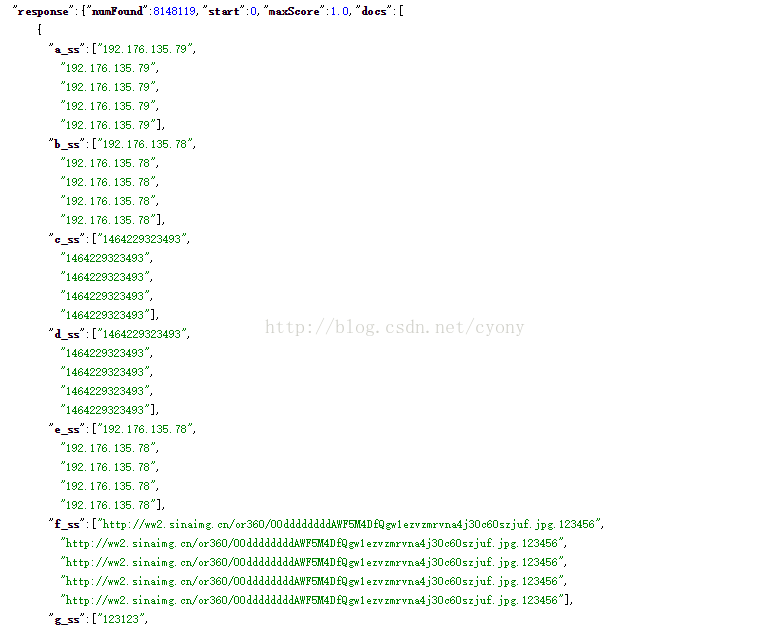
这样速度是可以单台节点达到30M/S甚至更高,但是带来的问题就是查询会变得很复杂,在命中多值中任意一条记录,结果集会带出所有值,在solr中认为这一组数据是一个文档,我们想了很多方案来解决这个问题,比较简单的方法是,在生成文档的时候控制多值字段中,没有重复的值,这样检索结果则会变得精确,缺点就是灵活性太低。另一个方案,是通过对数据做预聚合,管理快照,由于其实现比较复杂,效果也不是很理想,在此就不做过多描述了。
在不追求检索精确度,或者对数据可控的情况下,对于索引速度真的可以带来很大的惊喜。
尾言:solr由于是利用lucene为底层,lucene本身是单机的无法分布式,solr的核心就是引入了分片的机制,在数据规模变得特别庞大的时候各种弊端就显示出来了,无论是建立索引还是查询性能都不尽人意。但通过各种方法的优化与舍弃之后,差不多可以做到水平拓展,线性增长,能够满足大多数的业务场景。但是如果是要对历史数据进行检索的时候,这个历史数据规模又是极其巨量时,solr恐怕是无法承受的。现在兴起了很多列式存储结构以及时间序列的数据库以及仓库,比如driud和tsdb,他们在巨量数据检索时可以带来极高的性能体验。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









