






阿里云数据事业部强琦为大家带来内存计算方面的内容,本文主要从软硬件趋势、分布式计算简史与内存计算开始谈起,包括HIVE、ADS的介绍,接着分析了统一的计算框架,最后讲解了Spark和Flink经典的系统技术分析。一起来了解下吧。
软硬件趋势
我们现在使用的主流硬件从多核CPU 32核/56核,内存192G /384G,以及定制机型下更大的内存,存储层级可以做到三T的SSD/11×6T的SATA硬盘,而网络拓扑和带宽从IDC内的万兆网卡到IDC间的专线光缆,还有大数据和它的复用程度,读写比比较高的数据是业务价值极高的数据,我们可以针对不同的读写比的数据进行不同的系统优化,随之而来会有相应的问题:
- 从小型机到分布式到单机能力提升,矛盾么?
- 是否单机能力越强越好?
- 构建在虚拟机上的分布式?
数据密集型的计算可能会根据不同的计算平台选定不同的机型号,这就需要看计算任务到底 短板和瓶颈在哪里,比如瓶颈在CPU,那我们适当的增加CPU核心,把混合存储和内存降下来,这样可以有效的提高整个的资源利用率。
从现在的软硬件趋势可以看到,无疑CPU越来越快、memory越来越大、存储层级越来越丰富。
分布式计算简史与内存计算
经典的DataBase(DB)和现在比较火的BigData(BD)有哪些异同点呢?
从DataBase来看,数据是业务用户产生的,数据都必须schema化,而且保证强一致性,支持随机访问,数据实时的insert要能实时的查询,数据的访问按照CIUD集中的范式,机房是分散的,注重延时,还有一些其他显著特征,这是经典的OLTP的类似功能。
现在涌现的BigData技术体系,它的数据源是业务db或者log等,强调宽表,注重扫描,它是离线数据,侧重于数据计算,机房集中,BD重吞吐,最经典的领域就是数据仓库 OLAP。
DB势必要影响BD,而BD的一些技术最终也会推进DB领域的技术演进。
BigData
BD的数据有什么特点如下:
Volume、Velocity、Variety。
它的数据量是极其巨大的,对成本的要求非常苛刻;速度方面,数据不再以天、小时为单位,数据入口的吞吐、整个的时效性和用户的体验都有非常高的要求;多样性方面,数据怎么融合,数据源采集非常广泛,格式也是五花八门,对质量的把控也完全不一样。
今天BigData所面临的情况与DataBase不可同日而语,面临着巨大的复杂性和难度。
BD数据量有扩展性、有成本问题,BD的技术栈表示能力也是从支持机器学习到非SQL领域, 从半结构化到非结构化,它的计算模式以扫描为主。
GFS
分布式计算作为软件系统,也有着它与之匹配的演进。
在工业界、产业界,分布式计算蓬勃发展有赖于GFS,很快就对应着开源实现,HDFS开源社区的蓬勃发展,在某种程度上,也给国内的技术从业者提供了很大的学习机会。
- GFS主要是进行大文件或者快文件的存储,在GFS之上的系统可以把小文件合并成大文件,然后进行存储,流式文件同样根据它写入的特征特点和它读取的特点,在大文件上可以封装出流式文件;
- GFS具备不可修改性,在这种情况下,可以封装出Mutable的功能特性,比如说LSM可以支持随机读写;
- GFS扩展性可以达到跨核心、跨IDC、跨国;
- GFS使用廉价的服务器降低成本,通过replication来增加它的可靠性。
编程模型
在此之前,普通的技术开发者很难在集群上编写分布式程序和并行程序,编程模型在其表达能力方面,从RPC到MPI到SQL,它的表达能力是在不断的降弱,但是它的应用型是在不断的增强。
要在分布式上编程,程序怎么能做到扩展性?
- 如何根据网络拓扑来切分任务,怎么利用数据存储的本地化来避免不必要的网络传输和网络带宽?
- 如何去容错?1000台服务器的集群,只要有任意一个有故障,都算做整个集群有故障。
- 长尾效应。
无论是异构机型还是异构的网络拓普,或是根据数据分布的data scale,都会造成长尾效应,计算会被其中最慢的那个节点拖后腿,长尾会对整个用户提交任务的延时和对雪崩造成非常大的伤害。
计算逻辑和编程模型表示方面,ETL的工程师大多希望使用SQL建模的工程师,也会使用OLAP,而机器学习由于其对性能的极致要求,用户会希望系统开放最底层接口。
表示能力和自由度其实是一对treadoff,表示能力越强约束就越少,如果对原语进行约束,系统就会做很多failover。
MapReduce
MapReduce约束了用户的编写能力、编写范式,使得系统可以做非常多的分割容错的工作,用户只关心它的业务逻辑。
MapReduce适用于通用的数据密集型编程模型,最新的Hadoop 2.0其根基在于一个系统叫做Yarn,随着MapReduce的涌现,不同的数据密集型的编程模型也不断的出现,例如,图计算模型Pregel、Spark、Dremel 、Drill。
MapReduce的编程模型非常简单,它把Data Type建模成Key-value模型,那么Map function接受一条数据返回一个list(k,v),这个list(k,v)会通过一个本地的Combiner,Combiner接受(k,list(v)),返回list(k,v),那么,进行这样本地的重新组合以后,通过网络的shuffle进行数据的重新组织,根据K来组织的Reduce function,接受(k, list(v)),输出list(out)。
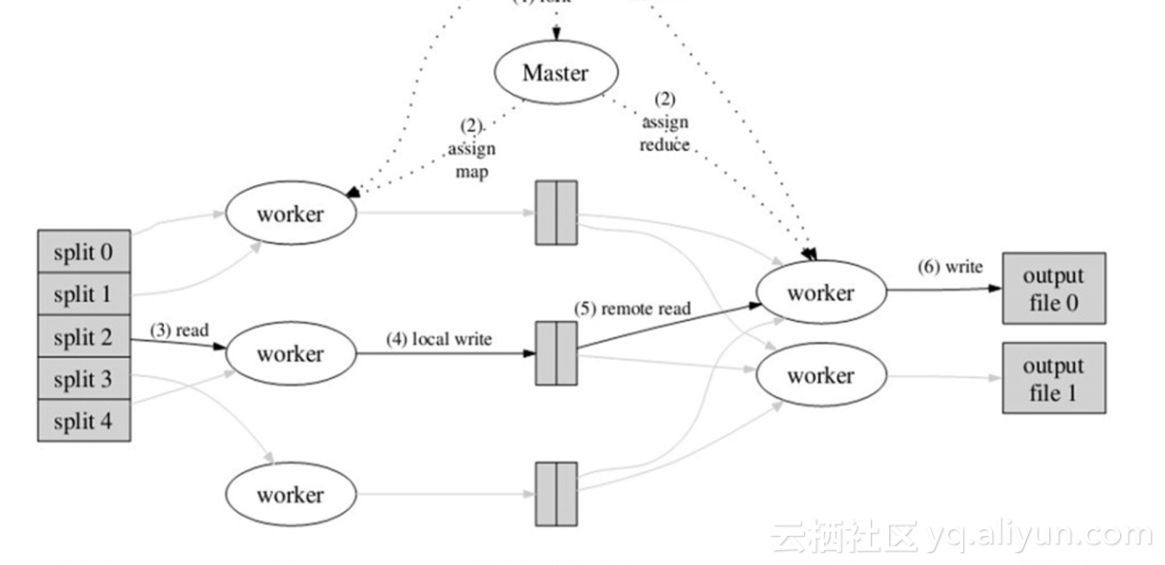
大致的执行过程如图,提交任务后,Master会将数据进行split 切分,然后分配给不同的worker,也就是Map节点,每个Map节点回调用户Map的implement,每个worker会回调
用户的Map实现。每个Map实现都会对着N个Reduce,通过shuffle输出文件,本地shuffle会进行sort和merge,进而可以调用Combiner,减少不必要的网络传输,当每个Map结束,
它的N个Reduce的结果都已经存储在本地,这时Master知道Map都已经结束,拉起Reduce节点,并且告知Reduce节点的数据,Reduce的shuffle会根据相应的地址,把它的每个Map里面属于它的文件拖回到本地,然后,不同Map节点相同Reduce节点的文件进行sort merge,sort merge完毕后,调用用户的Reduce方式,最后输出。
MapReduce模型,每步都要落地,并且shuffle是N×M的,N假设是Map,M是Reduce数,这里头存在大量的文件寻道和传输。
MapReduce的历史意义是非常重大,自动切分任务为多个小task,根据调度策略,兼顾本地性(gfs),将map tasks下发到执行节点,当task结束后,进行load balance,当全部map task结束后,根据reduce并发拉起进程,进行shuffle、sort merge,当本节点shuffle全部结束后,进行reduce task。
如果task失败,重新运行task,可以看到所有数据都是Immutable,不存在版本问题;如果node挂了,挑选节点重新运行task;如果有慢的task,backuptask。
调度
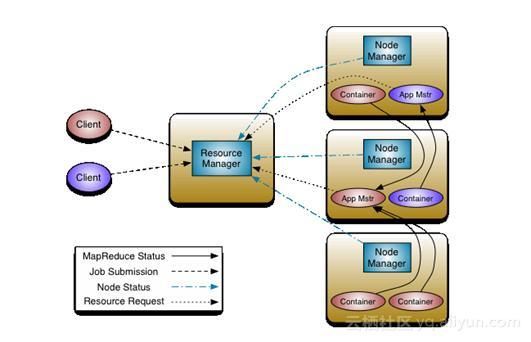
第一代的MapReduce,有非常多的问题。比如,无论是hdfs还是MapReduce,其Master都是单点,一旦宕机会有较长的恢复时间或者不可恢复性;而计算的Jobtracker,全局唯一,如果使用大量的文件则会加剧元数据的膨胀,资源分配和任务内调度混合;从资源角度,静态资源无法进行动态的划分,一旦分配出去,资源无法与别人共享;划分粒度较大,隔离性较差。鉴于以上原因,规模很难线性扩展,而且,单一Master造成整个升级非常困难。
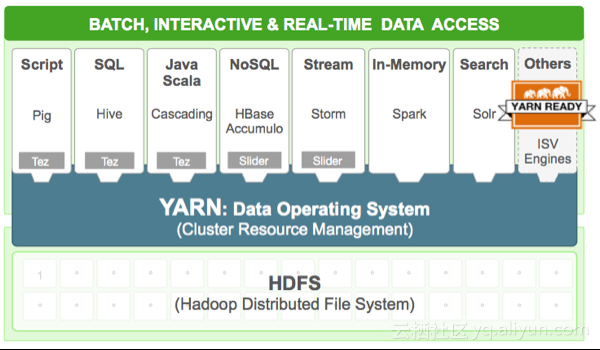
图是Hadoop2.0也就是Yarn的架构,可以看到最明显的一个标志,即将一层资源调度
和二层业务逻辑摆放分成了两个角色,也就是RM与AM的分离;增加了Container,保证更精细化资源的调度。当然,现在的Hadoop软件栈丰富了很多,从最底下的HDFS到上面的Yarn,也出来了很多新的东西,比如说Tez。
那么,从分布式计算来看,如何去切任务、如何去选资源、如何在这些载体里面摆放以最大化运行效率、如何运行下发的任务、以及如何控制时机?
Hive
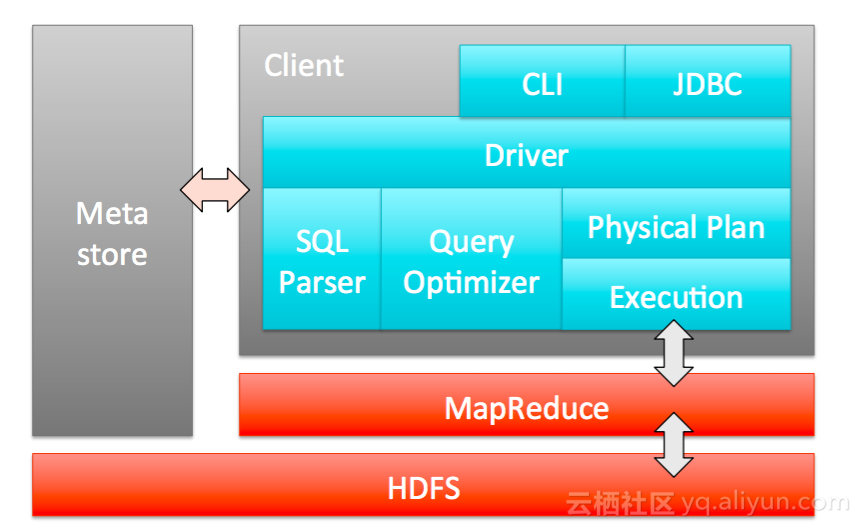
Hive是facebook开源的,它总体上是工作在MapReduce基础上,由Client 或者JDBC接受用户的SQL请求,然后将SQL进行语法的Parser,经过逻辑执行计划、物理执行计划下发,将一个SQL翻译成MapReduce的物理执行计划,下发到MapReduce机群。
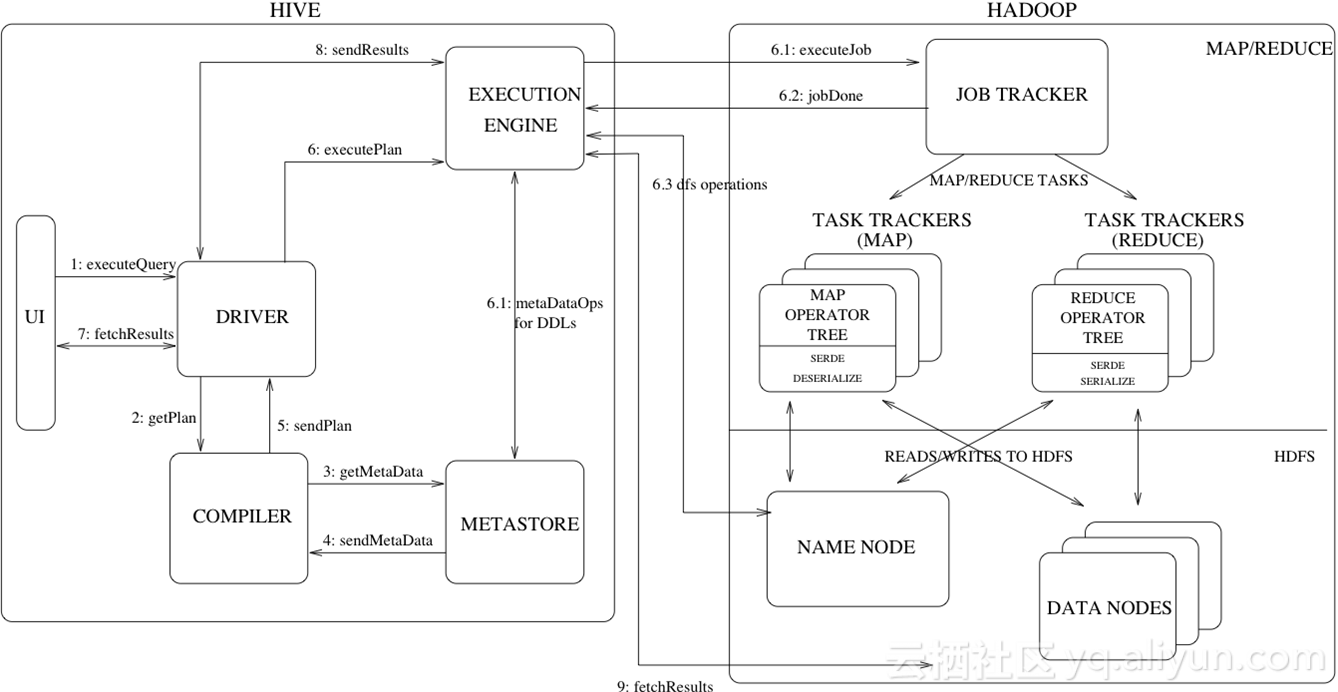
上图是一个MapReduce Module组成的DAG有向无环图。可以看到,HIVE是一个SQL的语法,所以可以提取出大量的元信息进行global的存储,进行权限控制。这个图描述了整个HIVE的下发执行逻辑,用户提交query发布SQL,通过编译提交编译模块,拿到物理执行计划,然后通过执行引擎向job tracker提交任务,最终根据用户的DDL信息存储,并且通知用户fetch结果。HIVE是完全架构在Hadoop、MapReduce的基础上。
Back to SQL
MapReduce的工作层次太低,而SQL leval太高、表达能力很强,整个的MapReduce执行是一个串行的运行,而DAG每一步都会落在磁盘上面,产生大量的磁盘IO、网络IO和磁盘寻道,Hadoop引入了Distributed cache,另外,MapReduce编写程序对整体存储耦合过重,所以MapReduce编写代码成本较高。
返回SQL来看,SQL完全是面向用户的视角,受众面和用户群非常广,易用性非常好,已经有非常好的行业标准,而且不断的在演进;
从系统视角来说,schema是一种知识,有了schema,就可以把数据质量控制在进入环节,可以制定很detail的数据安全策略,数据粒度可以到行、也可以到列,因为有了SQL,我们可以把基础算子进行组合,另外 SQL的出现,使得系统可以去理解用户的功能目的,作出大量的优化。
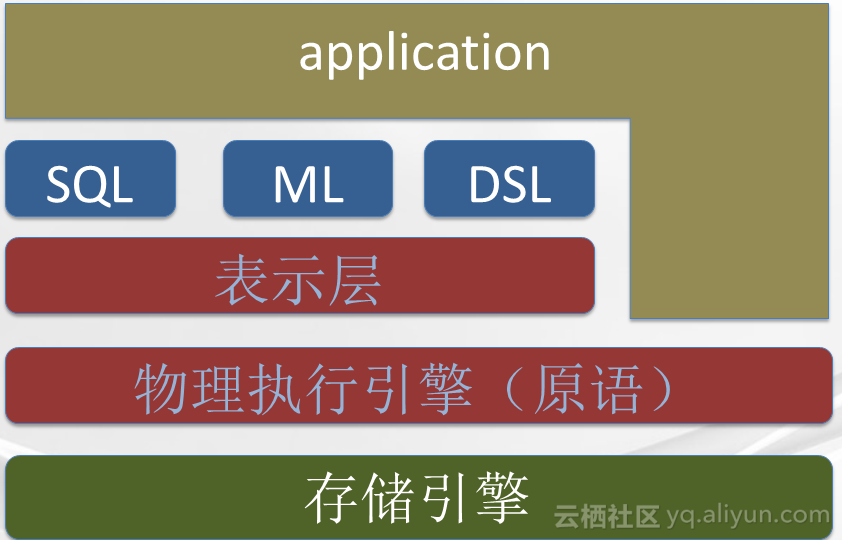
分布式计算领域也有按照DB的思路来做分布式计算的,比如MPP数据库,它的架构一般都分为存储引擎、物理执行引擎、SQL三层。而BigData的分层,一般最底下也是存储层,但是这个存储层跟DB的存储层有一些不一样,这个存储层是分布式存储层,BigData一般会存在物理执行引擎、这个物理执行引擎定义了最基本的原语,上面的算子表示层可以利用这个原语实现各种不同的基础算子,比如说distinct 、discounting 、count sum以及各种UDF 、UDEF,在此之上可以构建SQL的语意、machine learning的语意等,DB向上只提供SQL,而BigData 向应用即暴露物理执行原语,也可以暴露表示层原语,也可以支持各种DSL。
那么,无论是DataBase还是BigData,发展了几十年,有相当多的理论基础沉淀和工业实践。DB和BD在技术层面上肯定存在融合互相借鉴,包括Schema、逻辑执行计划、物理执行计划、Index、更精细化的存储格式、数据库领域的物化视图、内存的有效使用等方面,DB与BD的融合已经开始发生,无法阻挡。
数据库领域也会学习分布式计算,支持更复杂的更多变的数据结构,支持嵌套结构、支持更复杂的计算,抽象出更多的表示层,开放出更多的表示能力,我们不希望在异构系统之间拖动数据,增加数据成本和移动成本,使得不同的计算架构在一套执行器上,在运行时复用一套元数据。如今,GFS和MapReduce的出现,Hadoop社区蓬勃发展起来,Tez 、Dremel、 Drill、Lmpala 、Hana、Percolator 、Piccolo、Spark 和Flink相继问世,分布式计算领域系统层出不穷。
ADS
近期我们正式推出了阿里巴巴的分析数据库服务,叫做ADS。它支持的业务响应延时在1秒左右,它是进行OLAP分析,所处理的数据规模在千亿到万亿之间;ADS无需建模,具备较高的灵活性,ADS使用了大量的数据库索引技术和搜索的索引技术;它在成本计算模型上跟Hadoop和Impala还是有着自己独特的定位;在请求次数少于一定层数以内,加载索引的成本高于运行时成本,这时候用它是不划算的,但是高于这个成本以后,它基本上的使用成本
不会随着你的调用次数而增加。
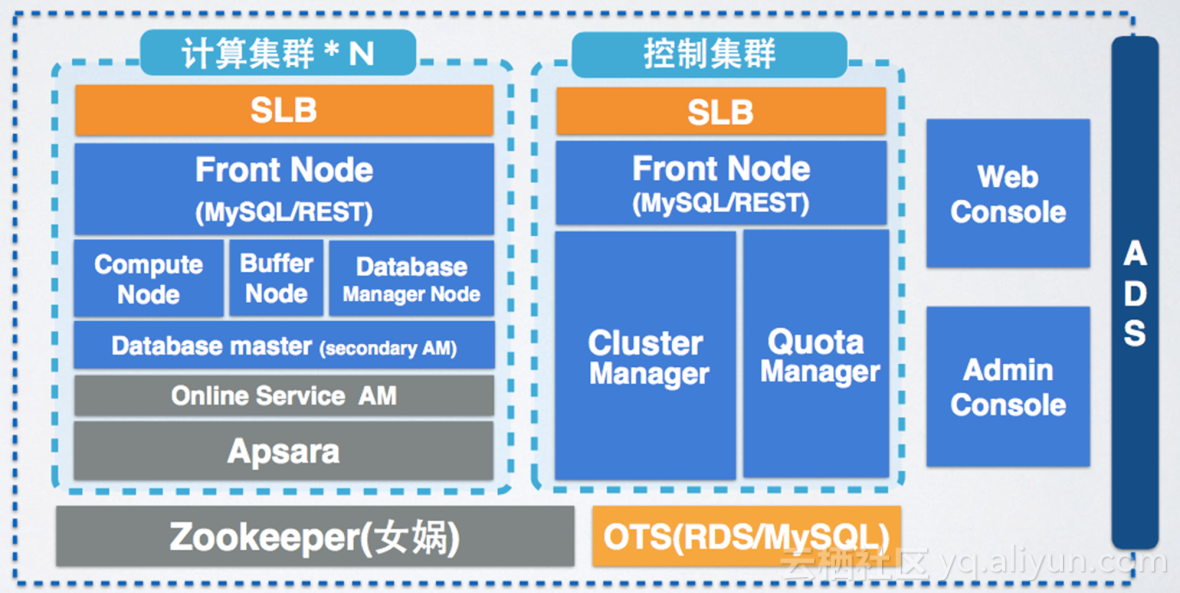
ADS完全兼容SQL92的标准,它大量引入了数据库搜索的索引技术,支持选数据、跳略过无效用数据、扫数据,ADS支持数据库的CRUD操作,支持多租户,以服务化的形式提供服务。
那么可以看到,ADS分成了三大部分:
- 一部分是Console,其中分为WebConsole和AdminConsole;
- 第二部分是控制集群,它管理整个集群的Cluster、完全用户的Quota;
- 第三部分是计算集群,计算集群分成前端节点和计算节点,计算节点是真正一个任务,也就是SQL下发执行的地方,在每个Compute Node上执行相应表相应分区,本地将这个表的本分区任务进行计算后,汇总到一台Compute Node上进行全局的汇总,最终返回到Front Node给用户返回。
整个ADS架设到阿里巴巴飞天的技术平台上,ADS做到快的原因主要有:
第一,整个集群预先拉起;
第二 , 制定丰富的数据结构,比如Index和元数据、帮助计算跳数据、最大减少扫数据;
ADS采用大量的基于成本和规则的优化、以及HBO的优化来针对不同的摆放策略、数据类型、元数据,针对用户的SQL进行物理执行计划和SQL改写。
内存计算
在我看来,所谓的狭义定义内存计算应该是最大化利用内存容量,并且可编程,框架内置容错,可以对数据在内存的摆放Replication和partition进行有效控制,并且内存数据进行最大化的reuse。
流式计算引入的Batch,可以把一批数据切批,每批相对比较小,都可以放在内存里头运行,而Batch内进行串行运算,Batch间进行并行运算,它所需要的数据Sort Merge都可以在内存完成,而Merge是一个update oldValue的过程,即便它超出内存,我们也可以让它全内存运算,Snapshot state可以引入Incremental一个snapshot机制进行有效的容错和存储访问,并且线性扩展。
统一的计算框架
历史上的不同计算系统,目前大有融合的趋势。
我们从统一计算框架的视角来看,换为纬度看计算:数据是不是分批执行、数据的Shuffle方式是push还是pull、数据进程或者说用户task是否需要预先拉起。

如图所示,A0B1C0为传统离线,A0B0C1为service mode,A1B0C1为流计算。
我们支持8种任意组合,只不过有些组合效率比较低,引入一个状态计算的计算框架MRM,提供一个灵活高效的Shuffle service以及一个灵活的APPMaster体系。
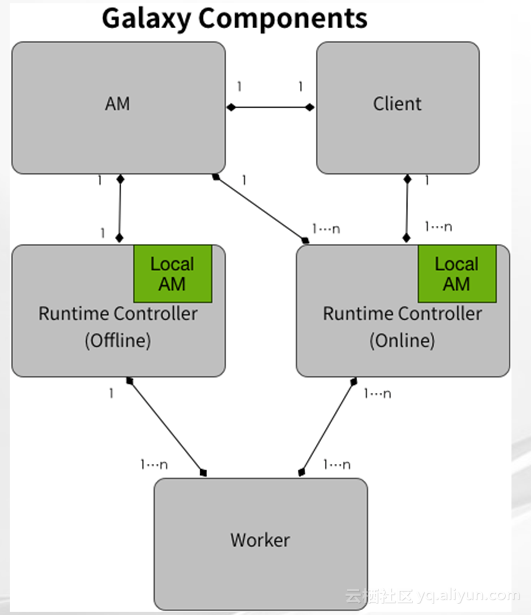
可以看到我们在进行尝试的统一计算框架里有很重要的角色,叫Runtime Controller,其中有Local AM,意思是在线请求或者对延时较高的请求,可以不唯一通过AM来提交任务,每个Runtime Controller里面有一个本地的Local AM,保留着足够供它决策的信息;我们这里的Session概念指的是在Session内的所有类型的job都可以复用数据,所以Session是复用数据的边界,在Session之外的job数据复用只能借助第三方存储比如DFS或者类似Tachyon这样的文件类型系统,或者其他的TV存储;在Local AM里有一个重要的管理组件叫做DAGManager,其中的DAGSession是管理提前拉起的物理执行dag,而与之对应的BlockManager里的重要数据结构BlockSession管理任务间复用的数据全局运行时管理,而VertexManager管理和开放所有的控制逻辑运行时机,LocalAM保留着跟AM里数据结构一致的本地AM,包括DAGManager、BlockManager和VertexManager,然后AM会通过心跳将新增加的DAGManager里的信息同步给所有的Runtime Controller的localAM,所以,在线请求提交任务的时候,如果发现localAM里已经有与这个请求相匹配的拉起的物理DAG执行资源,直接选取这些资源,然后再查看这个计算涉及到的数据是不是已经被加载在BlockSession里头去,如果已经有进行合适的摆放,选择完所有所需要的资源后直接下发Worker,当然,大家可以看到不同的Runtime Controller的资源是一样的。
算子
与传统的离线不同的是,在Worker端会存在不同任务的竞争,所以,在Worker端会有本地的调度。算子层也提供了五类基础算子map , reduce , merge , shuffle , union ,这五类基础算子是“正交”的,可以组合出复合算子,或衍生出高级算子。
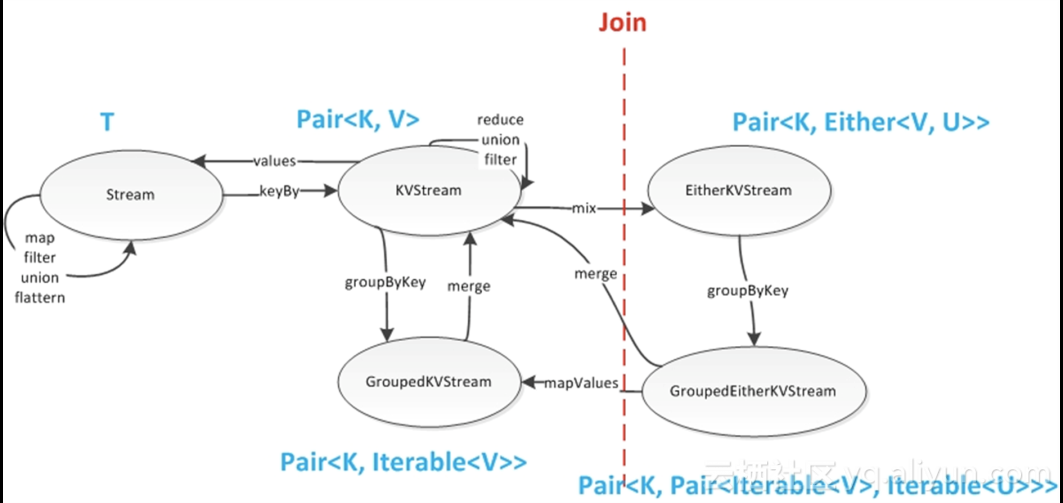
图为几个算子之间数据结构的流转图。
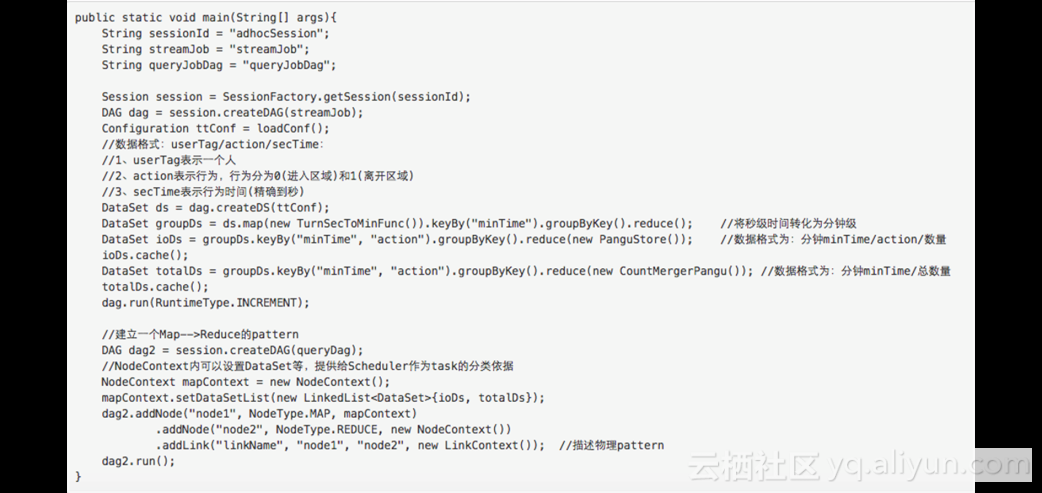
可以看到这个Case包含了离线计算、实时计算和adhoc的查询,这段代码是为在线准备物理拓扑,一旦拓扑建立,在线请求将不会通过AM,而直接通过本地Local AM找到合适的计算资源进行下发执行。

在线的这部分query直接可以复用离线拉起的DAGSession,从而达到秒级以内的在线请求。
问题引申
统一计算框架的引入,定义了Runtime Controller,其看到的资源基本一致,需要Worker层的本地调度,它具有灵活的表示层,但是灵活的表示层所有的数据类型都是范型,范型就会有较高的运行时和内存的代价,所以引入对象池以及内存池来尽可能的缓解这个问题;Table是一个具备schema的存储表示,可以利用用户schema和系统schema做大量的本地化的物理计划执行优化和算子的改写,我们也同时支持LocalDataSet,用户可以指定不同的Dataset具备相同的Tag,系统在加载的时候尽量使得相同Tag摆放在相同的内存,我们定义了一些抽象行为来指导系统的优化器,比如Match接口;我们也引入了CBO和RBO的框架来进行Join和大量的Pushdown,将不同的运行方式与用户的处理剥离出来,使得用户的处理逻辑只跟他的功能相关。
那么,数据库技术是不是可以和BigData分布式计算技术进行有效的融合和相互借鉴?
数据不拖动,更好的Schema控制,更精细化的索引元数据,本地调度策略,CBO框架以及引入更多的目标客户,这些目标客户已经很熟悉SQL的语意和语法。

在代码优化方面,从向量优化方面来说,我们有了schema,可以进行列式存储,列式存储很明显的好处是可以做高效的压缩;另外,我们可以利用CPU单指定级多数据级的特点,如果向左边的去运算,每次都会产生一条CPU指令,而优化成右边,C0和C1是集中存储,在一次迭代中,一次指令可以把多条数据进行集中运算,相比于左边,在密集数据计算情况下可以把性能提升4到10倍以上;
大家都知道在举证运算和图形渲染方面,现代CPU的技术分支预测和执行估计本质上运行时会出现比较大的问题,尤其是在switch/case、if/else、for/while这样的环节,我们的核心要点是将运行时的不确定性变成运行时的确定性,所以,利用了Codgen技术,包括序列化/反序列化、虚函数、(Sql)表达式、DAG执行以及String优化来将运行时的不确定性变成确定性,使得整个CPU更加友好。
业界经典系统技术分析
Spark

spark在写WordCount函数时,处理代码非常简单,读一行一行的数据是udtf,把它数据按照空格打成一个一个的map,发现key,而Reduce做加法最终存储。
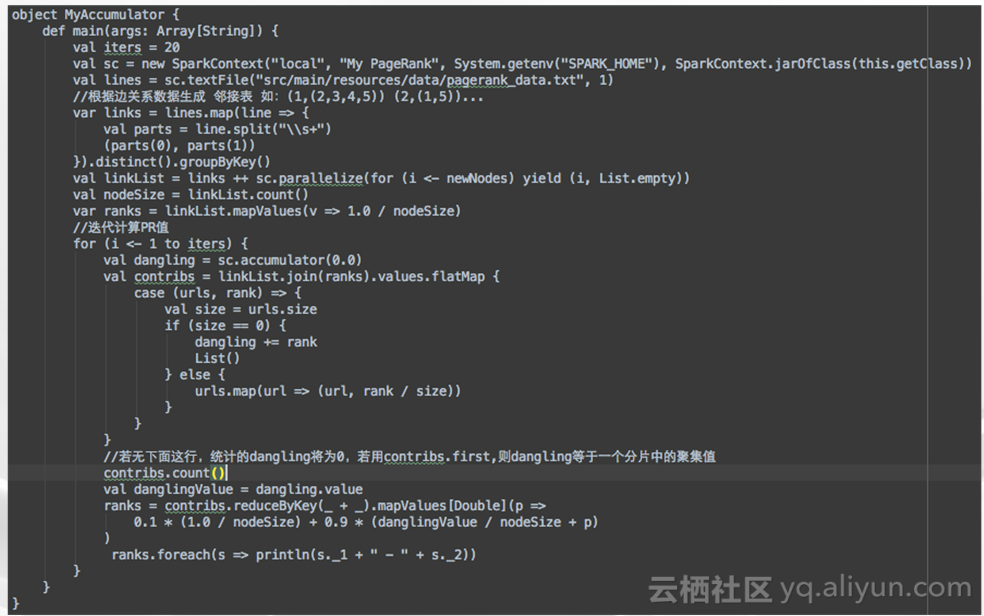
spark做PageRank,这是spark做内存reuse、数据reuse很经典的案例。每轮迭代的时候,MapReduce都会把这张Link表以及PageRank表写入HDFS,在下一轮迭代重新加载,这造成了大量的无效的IO开销和网络开销,可以看到Spark将这张Link表catch以后,这张表在后面的迭代按照partition,一直都在加载内存,而在本轮迭代的Map以后,这个Map操作的Shuffle是与这个关系表的partition是一致的,所以,保证了Map的本地化、Join的本地化,可以看到,关系表先去Join初始化的Link,然后这两个dataset 的RDD按照partition去Shuffle切齐的,Join都是本地命中,然后,一个URL命中,通过一个flag map由一个list变成多个数据,然后每个数据去把它的新Map向自己的初边发射出去,而这个Shuffle又会组成新的PageRank的RDD,可以看到底下reduceby就把它所有的入度给它的PageRank更新值,算出一个最终的rank值,然后进行下一轮迭代。
Flink
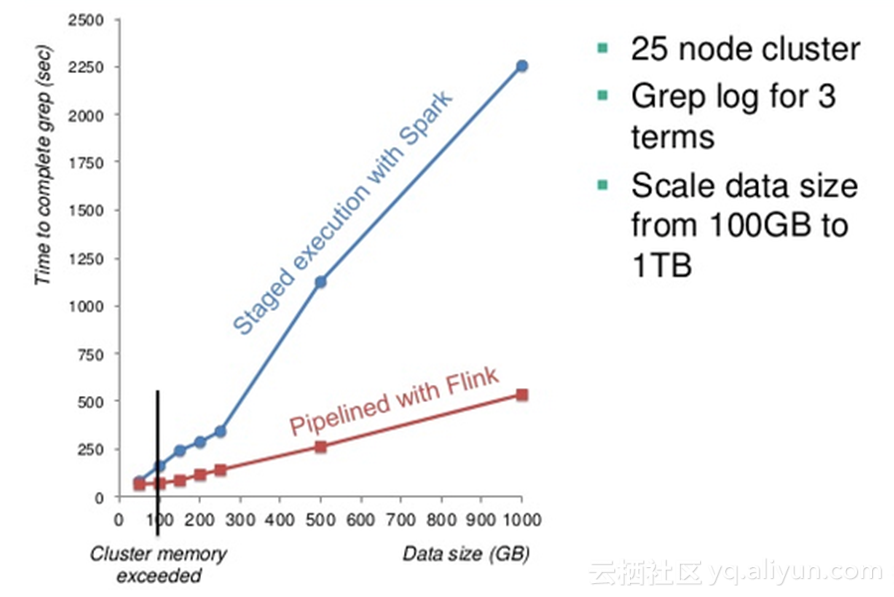
Flink跟Spark最大不同在于它引入了一个Pipeline的执行框架,当数据量超过了物理内存的
界限的时候,Spark要进行计算,它一定要通过sort merge,它的计算延时是线性成长上去。而Flink类似于分Batch运行,所以,每批次它都可以进行内存操作。
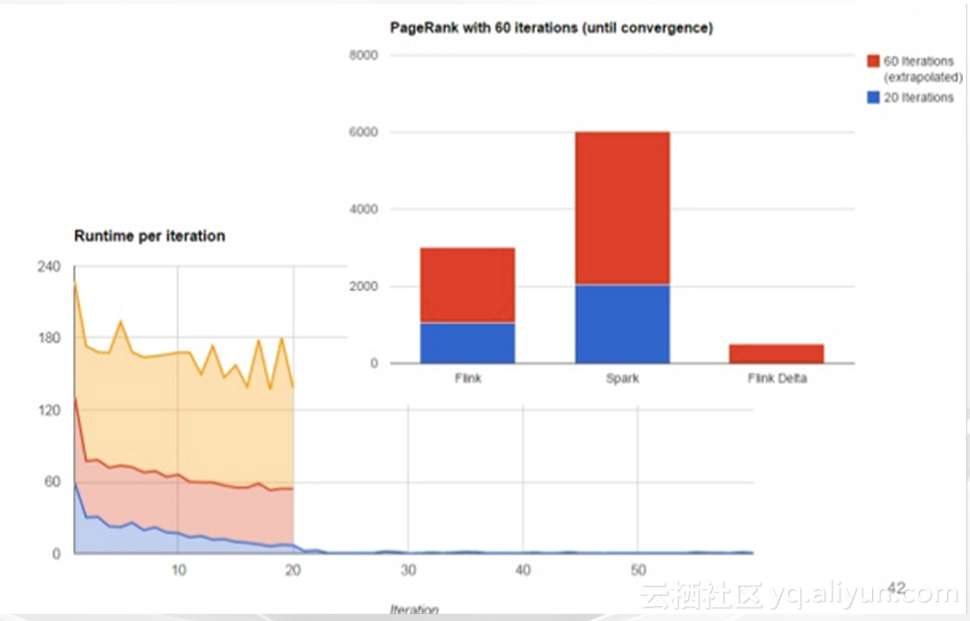
这是一个实测的结果图,Flink在迭代计算有一些特殊的考量,比如说它的delta计算,大量研究表明,类似于PageRank这样的计算,百分之三四十的节点是在最初的十轮迭代后面的值,迭代更新已经不显著,所以,它们完全可以不参与后阶段的迭代计算,这样就可以
节省大量的Shuffle网络资源和IO资源,Flink支持用户编写非常容易的代码来进行早停,也就是说,节点在收敛度数不大的情况下进行早停,大量的计算可以避免。在引入delta计算以后,Flink的迭代收敛速度大大提高。
在大规模数据下,stage by stage的模型其实不可避免的超过物理内存的界限,而使整个计算延迟加剧,我们到底采用怎么样的技术才能保证可以进行完全的内存计算呢?
对此,我们在这个方面正在进行大量的尝试,内存计算和统一计算框架近期发展非常迅速,但远远还没有达到我们期望的阶段,尚有大量的技术难点有待我们去攻克,在这个领域仍然有非常多的机会和非常大的空间等待去攻克,和大家分享就到这里。
谢谢大家!















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









