






主要内容
本教程中所有例子跑在Spark-1.4.0集群上
- DataFrames简介
- DataFrame基本操作实战
DataFrames简介
DataFrames在Spark-1.3.0中引入,主要解决使用Spark RDD API使用的门槛,使熟悉R语言等的数据分析师能够快速上手Spark下的数据分析工作,极大地扩大了Spark使用者的数量,由于DataFrames脱胎自SchemaRDD,因此它天然适用于分布式大数据场景。相信在不久的将来,Spark将是大数据分析的终极归宿。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,与传统RDBMS的表结构类似。与一般的RDD不同的是,DataFrame带有schema元信息,即DataFrame所表示的表数据集的每一列都带有名称和类型,它对于数据的内部结构具有很强的描述能力。因此Spark SQL可以对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率。
DataFrames具有如下特点:
- Ability to scale from kilobytes of data on a single laptop to petabytes on a large cluster(支持单机KB级到集群PB级的数据处理)
- Support for a wide array of data formats and storage systems(支持多种数据格式和存储系统,如图所示)
- State-of-the-art optimization and code generation through the Spark SQL Catalyst optimizer(通过Spark SQL Catalyst优化器可以进行高效的代码生成和优化)
- Seamless integration with all big data tooling and infrastructure via Spark(能够无缝集成所有的大数据处理工具)
- APIs for Python, Java, Scala, and R (in development via SparkR)(提供Python, Java, Scala, R语言API)

DataFrames实战
假设Spark-1.4.0集群已经搭建好了,搭建方法见本人另一篇文章,Spark-1.4.0集群搭建http://blog.csdn.net/lovehuangjiaju/article/details/46883973
在spark安装目录中执行root@sparkmaster:/hadoopLearning/spark-1.4.0-bin-hadoop2.4# bin/spark-shell ,在Spark-1.4.0中,spark-shell除了自动创建SparkContext实例sc外,还会自动创建SQLContext实例sqlContext
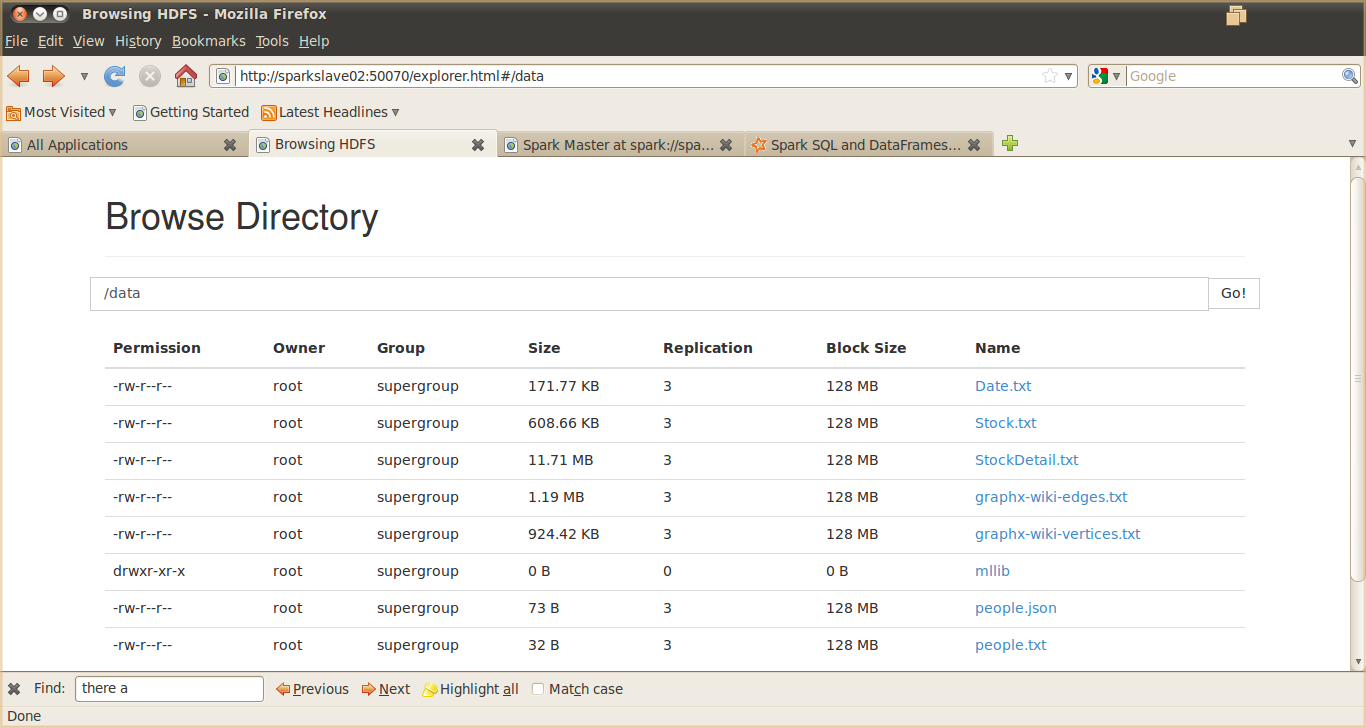
1 上传测试数据到hdfs上。本实验数据取自http://blog.csdn.net/bluejoe2000/article/details/41247857
中的sparkSQL_data.zip,关于数据的描述可以参考对应博客中的文章,将sparkSQL_data.zip上传到SparkMaster,然后解决到根目录,利用hadoop fs -put /data / 进行文件上传,上传后的结果如下图:
2 从HDFS文件创建DataFrame,并进行相关操作
//从HDFS上创建DataFrame
val df = sqlContext.read.json("/data/people.json")
从中可以看到DataFrame是带类型的
// 显示DataFrame的内容
df.show()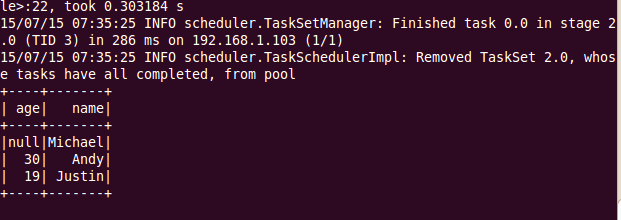
//打印DataFrame的Schema信息
df.printSchema()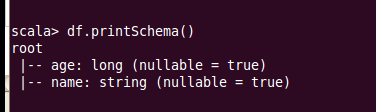
//选择名称列并显示
df.select("name").show()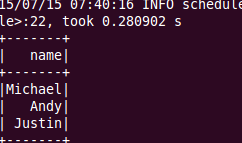
//过滤数据
df.filter(df("age") > 21).show()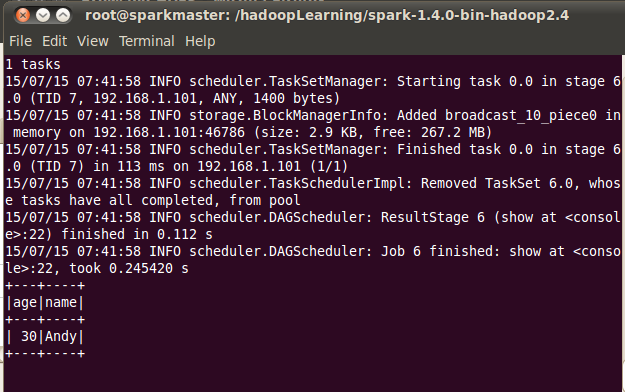
//分组计数
df.groupBy("age").count().show()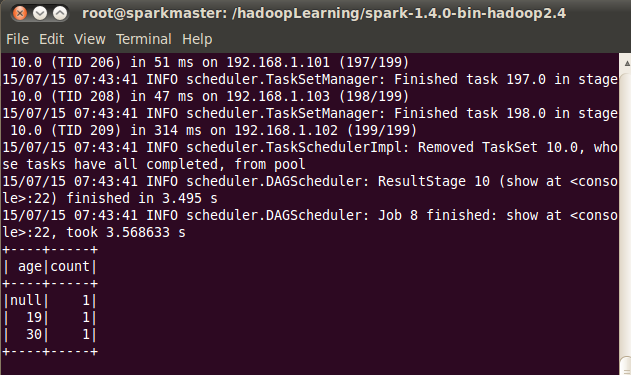
3 注册成表,并进行SparkSQL操作
//将DataFrame注册成表
df.registerTempTable("people")
//利用sql方法进行SparkSQL操作
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
//将返回结果看作是数据库操作的一行,(0)表示第一列,依次类推
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)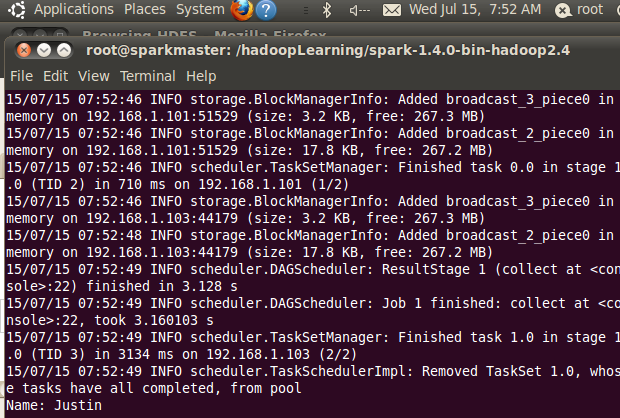
//通过域的名称获取信息,结果同teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
teenagers.map(t => "Name: " + t.getAs[String]("name")).collect().foreach(println)
//将结果以Map的形式返回
teenagers.map(_.getValuesMap[Any](List("name", "age"))).collect().foreach(println)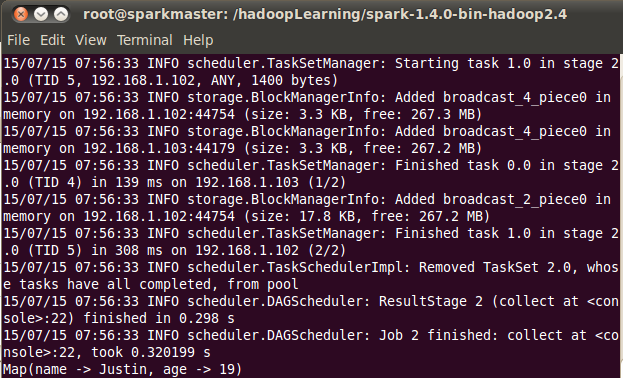
这是本节关于DataFrames的基础操作,后期我们将对DataFrames内部原理、Schema及相关API的详细使用进行深入介绍。
获取更多内容可以关注公众微信号 ScalaLearning
















 3895
3895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









